序言
当深度学习的浪潮席卷全球时,R 语言社区曾处于一个微妙而略显尴尬的境地。作为统计计算与数据科学的先驱,R 在数据操纵、可视化及统计建模上拥有得天独厚的优势。其优雅的向量化语法和以 tidyverse 为代表的现代生态,使其成为探索性数据分析的标杆。
然而,长期以来 R 开发者在构建深度神经网络时,始终面临着“跨语言”的尴尬。无论是早期的 mxnet 还是后来的 tensorflow 与 keras 接口,本质上多是 Python 库的 R 语言封装。
为了跑通模型,首先要跨越“环境地狱”:配置 Python、管理 Conda 环境、处理 reticulate 的调用报错。这种复杂的工具链脱节,不仅抬高了技术门槛,更在写下首行核心代码前,就劝退了许多追求环境纯粹的数据科学家。R 优雅的数据管道与深度学习工作流之间,始终存在着一层难以消解的隔阂。
真正的转折点源于 torch (Falbel 和 Luraschi 2025) 包的横空出世。它直接构建在 C++ 的 LibTorch 之上,不是一个简单平庸的语言绑定,而是一个深思熟虑、为 R 语言习惯量身定制的原生框架。
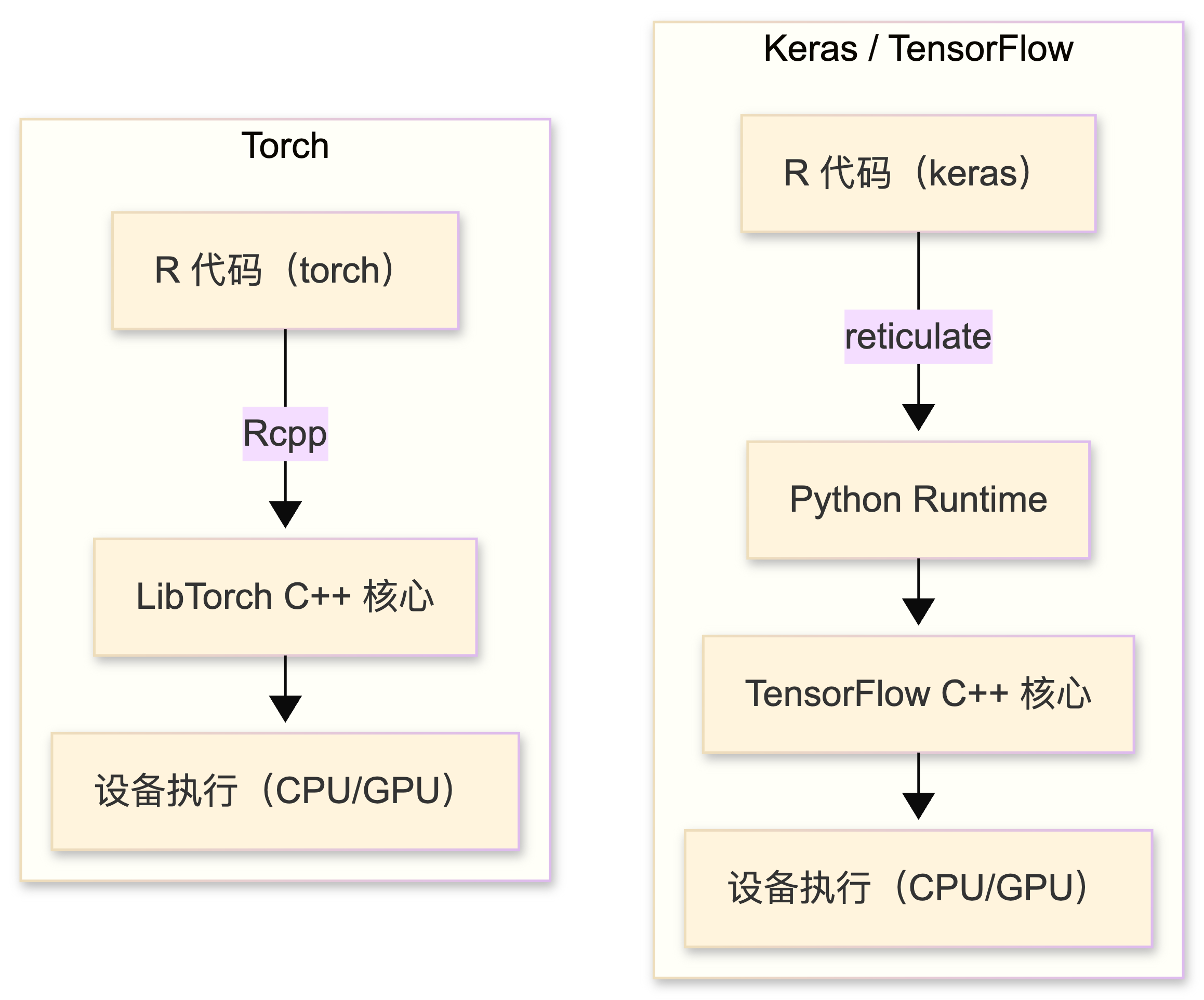
本书选择 torch 作为核心工具,正是看重其在“算法透明度”与“工程直觉”之间的完美平衡:
- 运行
install.packages("torch")得到的是一套独立、原生的解决方案。告别 Python 版本冲突与双运行时环境,让模型从开发到生产的链路变得前所未有的清爽。 torch坚持使用 R 的 1 起始 (1-based) 索引。这意味着当你面对数学公式中的 \(x_1\) 时,代码里就是 x[1] 而非反直觉的 x[0]。这种微小的一致性,极大地降低了将公式转化为算法时的认知负荷- 与高度封装、隐去细节的高级框架不同,
torch鼓励通过nn_module手动编写 forward 函数。配合动态计算图(Dynamic Graph),你可以像操作原生矩阵一样随时暂停、检查张量维度、观察梯度流动。这让深度学习不再是不可捉摸的黑盒,而是触手可及的数值演算。
不可否认,作为一个快速成长的生态,当前的 R torch 在预训练模型库(如 Hugging Face)的生态对接上,与 Python 仍有差距。但这恰恰使其成为学习深度学习本质的绝佳载体——它迫使我们回归原理,而非仅仅充当 API 的搬运工。
本书致力于将这种“母语级”的深度学习体验带给每一位 R 用户。你将看到如何用熟悉的 %>% 管道连接数据流,用 ggplot2 实时追踪损失曲线,并在同一个 Quarto 环境中完成从数学推导、代码实现到工程部署的闭环。
深度学习正在重塑现实的边界,而 torch 正在定义 R 语言在人工智能时代的新疆界。愿以此书,送给那些既追求数学之美、又严谨对待工程实践的同行者。
旅程拉开序幕,让我们开始。
刘思喆,2026 年 3 月,北京