4 多层感知机
“生命唯一的目的,就是传递信息。”
—— 《超体》 (2014)
露西的大脑开发率不断飙升,她眼中的世界不再是实体,而是无数条闪烁的连线。神经元之间的电流像烟火一样爆发,形成了一张覆盖全球的巨大光网。
4.1 非线性能力的引入
4.1.1 交互效应
在传统的统计建模中,最基础的假设是可加性(Additivity)。但现实数据往往充满复杂的交互效应(Interaction Effects)。
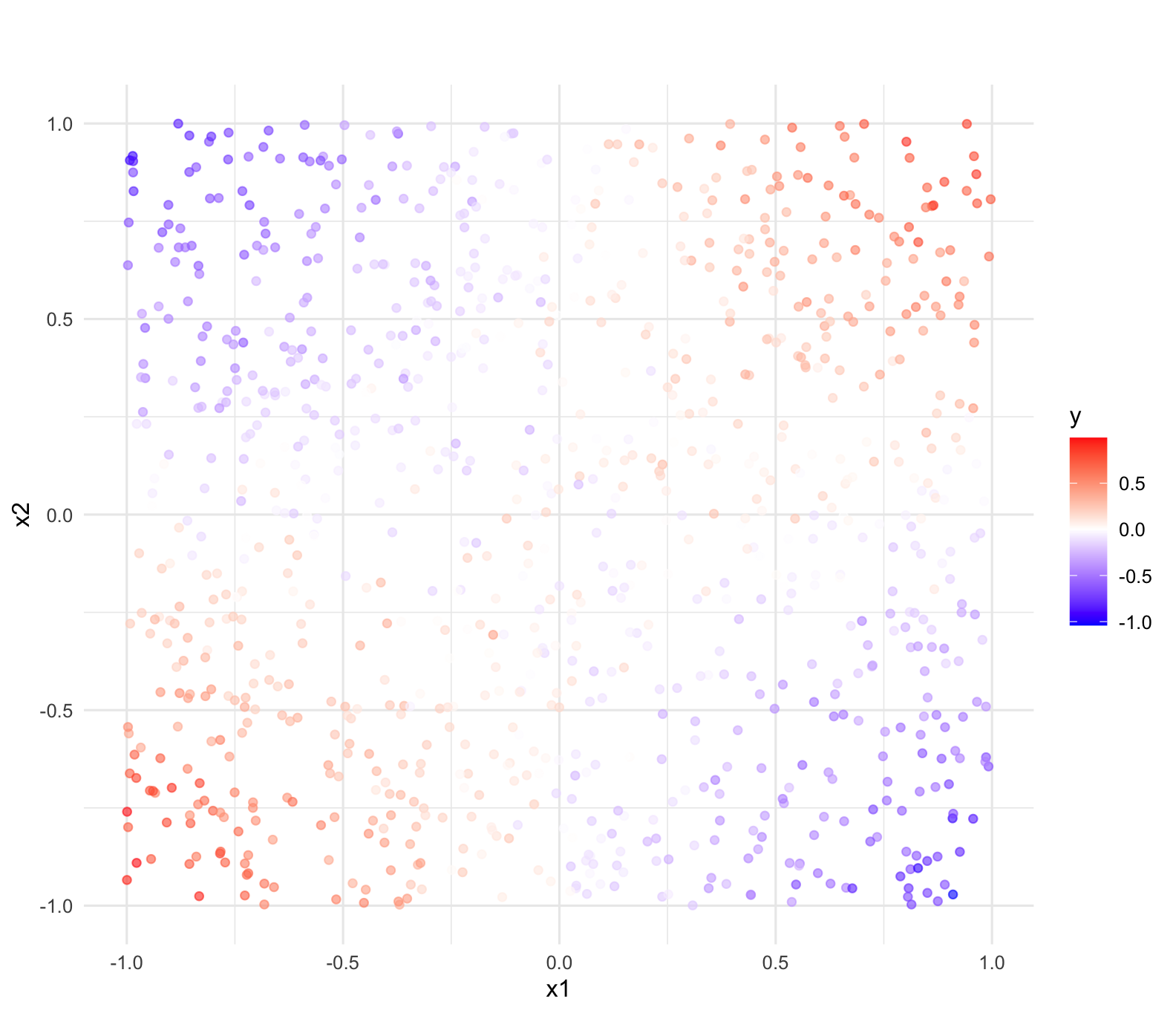
考虑一个经典的异或(XOR)风格的数据分布:
- 假设 \(y\) 取决于 \(x_1\) 和 \(x_2\) 的符号。
- 当 \(x_1\) 和 \(x_2\) 同号(同为正或同为负)时,\(y\) 倾向于正值。
- 当 \(x_1\) 和 \(x_2\) 异号时,\(y\) 倾向于负值。
这种关系在数学上可以近似为乘法关系 \(y \propto x_1 \cdot x_2\)。此时,\(x_1\) 对 \(y\) 的边际效应取决于 \(x_2\) 的正负——这就是典型的交互效应。
看一下 R 代码的实现:
library(tidyverse)
# 1. 生成交互数据
set.seed(42)
df <- tibble(
x1 = runif(1000, -1, 1) ,
x2 = runif(1000, -1, 1) ,
y = x1 * x2 + rnorm(1000, 0, 0.1) # 真实关系是乘法
)
如果我们尝试使用标准的线性回归模型的加法模型和交互模型来拟合这份数据,结果会如何?
# 线性回归 (加法模型)
model_linear <- lm(y ~ x1 + x2, data = df)
summary(model_linear)$r.squared
# [1] 0.00160... (完全失败,因为平面无法拟合马鞍面)
# 交互回归 (手动特征工程)
model_interaction <- lm(y ~ x1 + x2 + x1:x2, data = df)
# 也可写作 x1*x2, 等价于 x1:x2
summary(model_interaction)$r.squared
# [1] 0.9234... (完美拟合)虽然 x1:x2 或 x1*x2 能解决问题,但在深度学习面临的高维数据(如图像像素)中,比如输入是一张 \(28 \times 28\) 的图像(784 个像素),我们要构建交互项,理论上有 \(C_{784}^2\) 种两两组合,甚至更多的高阶组合。手动构造特征在维数灾难面前是不可行的。
我们希望构建一个神经网络,只输入原始的 \(x_1, x_2, ...\),让网络自动学会“相乘”这个非线性关系。
4.1.2 线性坍塌
初学者常有一个误区:既然单层网络能力有限,那我多堆叠几层(Deep Neural Network)不就变强了吗?
比如这个两层网络(没有激活函数):
# 这是一个没有激活函数的两层网络
net <- nn_sequential(
nn_linear(2, 10), # 第一层:把 2 维变成 10 维
nn_linear(10, 1) # 第二层:把 10 维变成 1 维
)如果你训练这个网络,你会发现 Loss 永远降不下去,预测结果和 lm(y ~ x1 + x2) 一样糟糕。为什么?
让我们做一个简单的数学推导:
- 第一层:\(h = W_1 x + b_1\) (将输入映射到隐藏层)
- 第二层:\(y = W_2 h + b_2\) (将隐藏层映射到输出)
我们将第一层的公式代入第二层: \[ y = W_2 (W_1 x + b_1) + b_2 = (W_2 W_1) x + (W_2 b_1 + b_2) \]
如果我们令新的权重矩阵 \(W' = W_2 W_1\),新的偏置 \(b' = W_2 b_1 + b_2\),那么整个网络就变成了:
\[ y = W' x + b' \]
结论令人震惊: 两个线性层的叠加,在数学上严格等价于一个线性层。
这意味着,无论你堆叠了 100 层还是 1000 层线性网络,它的表达能力(Capacity)并不比第 1 节里的那个单层线性回归强。这就是所谓的“线性塌缩”。为了打破这种诅咒,我们需要在每一层的输出后面插入一个非线性变换 \(\sigma\):
\[ y = W_2 \cdot \sigma(W_1 x + b_1) + b_2 \]
正是这个非线性的 \(\sigma\),让神经网络拥有了“弯曲空间”的能力,从而能够逼近交互项。
我们在代码中加入 nn_relu() 再试一次:
net <- nn_sequential(
nn_linear(2, 10),
nn_relu(), # <--- 关键的非线性层
nn_linear(10, 1)
)训练后,这个网络能完美拟合交互数据(400 轮迭代后 R-squared 为 0.9232)。网络在没有被显式告知“相乘”规则的情况下,自动学会了模拟 \(x_1 \times x_2\) 的关系。
虽然它本质上是把 \(x_1 \times x_2\) 的曲面看作是由无数个小平面(ReLU 的折线)拼凑出来的,但在效果上,它自动学会了交互。
4.1.3 激活函数三巨头
一、Sigmoid,非常漂亮的 S 型曲线
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]
能将任意实数压缩到 \((0, 1)\) 区间。它模拟了生物神经元的“饱和”特性——输入极小是 0(抑制),极大是 1(激活),中间平滑过渡。
但它最大的问题是,当输入 \(x\) 很大或很小时,Sigmoid 曲线非常平坦,导数趋近于 0。这会导致反向传播时,梯度信号在传递几层后就消失了,深层网络无法更新。而且输出恒为正,非零中心化。所以它几乎不在隐藏层使用。主要用于二分类任务的输出层(将 Logits 转化为概率)。
二、Tanh,零中心化的改进版
\[ \tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]
能将输入压缩到 \((-1, 1)\) 区间。它是零中心化的(Zero-centered),收敛速度通常更快。但依然存在梯度消失问题。在循环神经网络(RNN/LSTM)中依然是标配。
三、ReLU (Rectified Linear Unit),简单粗暴的王者 \[ \text{ReLU}(x) = \max(0, x) \]
正数保持不变,负数直接置零。优点是计算极快,只有比较和赋值,没有昂贵的指数运算。
在 \(x > 0\) 的区域,导数恒为 1。这意味着无论网络多深,只要神经元处于激活状态,梯度信号就可以无损地传回前端。负输入输出为 0(神经元“死掉”),这在某种程度上引入了稀疏表达,模拟了生物大脑的节能特性。是目前深度学习中隐藏层默认的首选激活函数。
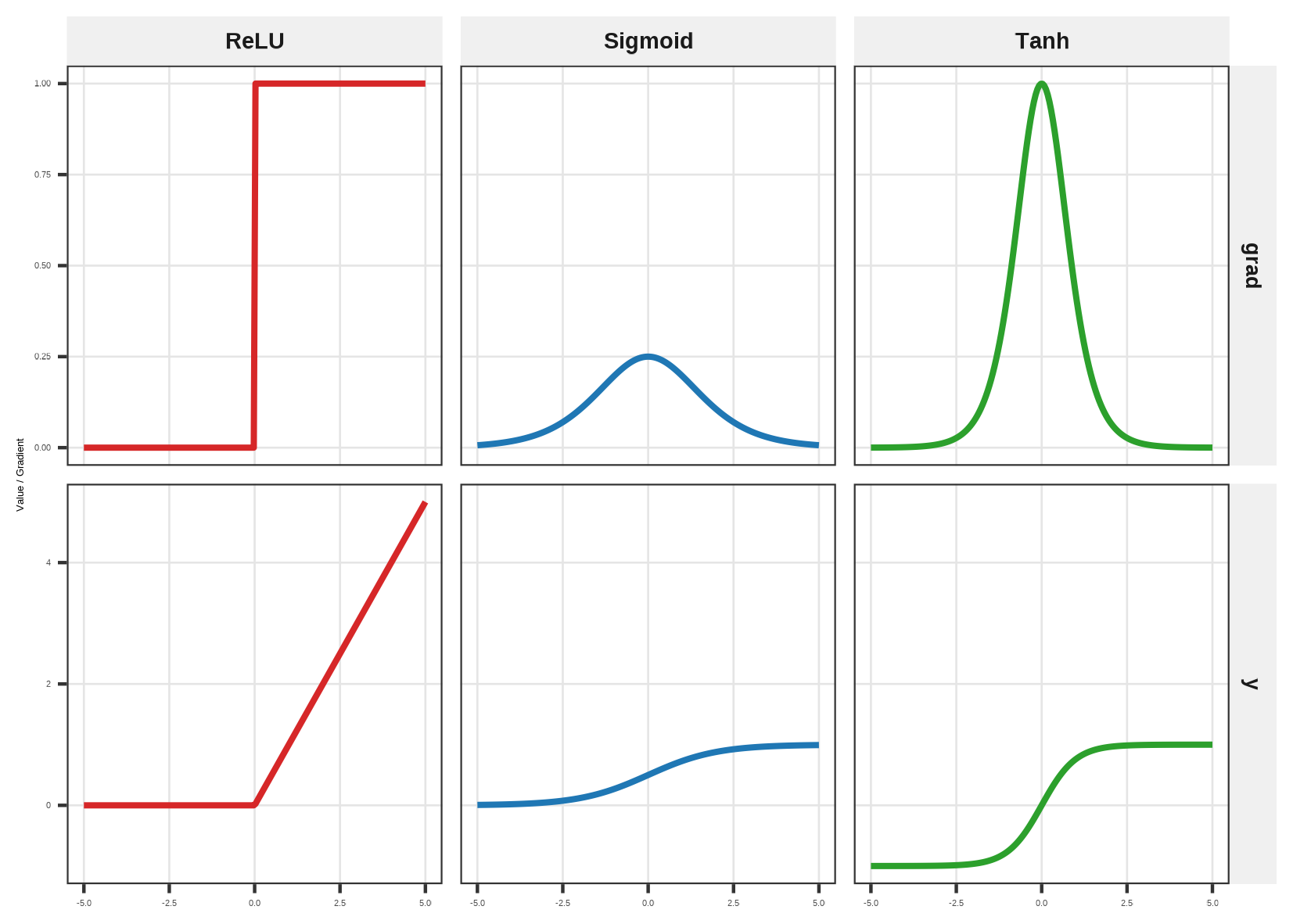
运行上述代码,重点观察第二行(grad)的图像:
- Sigmoid & Tanh:它们的导数像一个钟形。当 \(x\) 大于 3 或小于 -3 时,导数几乎变成了 0。这就是梯度消失的视觉证据——在这个区域,神经网络将停止学习。
- ReLU:它的导数是一个阶跃函数。只要 \(x > 0\),导数恒定为 1。这意味着梯度信号可以像在高速公路上一样畅通无阻地传回深层网络。
4.1.4 函数式 vs 模块式
在编写 R torch 代码时,你会发现激活函数有两种调用方式。初学者容易混淆,但它们各有用途。
方式一:函数式 (Functional API)
位于 torch_relu(), torch_sigmoid() 等。 它们是纯粹的函数,输入一个张量,输出一个张量,不保存任何状态。这个场景用的最多。
library(torch)
x <- torch_tensor(c(-2, -1, 0, 1, 2))
# 直接调用函数
out <- torch_relu(x)
# 输出: [0, 0, 0, 1, 2]适用场景:当你自己在 forward 方法中手写复杂的运算逻辑时。
方式二:模块式 (Modular API)
位于 nn_relu(), nn_sigmoid() 等。 它们是 R6 类(对象)。你需要先实例化它,把它变成模型层的一部分1。
# 实例化一个层对象
relu_layer <- nn_relu()
# 调用它 (内部会自动调用 forward)
out <- relu_layer(x)4.2 多层感知机与模块化
当我们把线性层和非线性激活函数交替堆叠,并且至少引入一个中间层(隐藏层)时,我们就构建了深度学习中最基础、最经典的模型——多层感知机(Multilayer Perceptron, MLP)。
4.2.1 什么是多层感知机
从数学结构上看,MLP 的本质就是复合函数。如果说单层线性网络只能拟合直线(或超平面),而激活函数提供了非线性的弯曲能力,那么 MLP 就是通过层层嵌套,获得逼近任意复杂函数的能力。假设有一个 13 个输入特征的数据集,一个“输入层 -> 隐藏层 -> 输出层”的 MLP 数学表达如下:
\[ \text{Price} = W_2 \cdot \underbrace{f(\underbrace{W_1 \cdot x + b_1}_{\text{线性变换}})}_{\text{隐藏特征 } h} + b_2 \]
其中:
- \(x\) 是输入向量(13 维)。
- \(f\) 是激活函数(通常使用 ReLU),负责引入非线性。
- \(W_2, b_2\) 将隐藏特征映射回 1 维的实数(预测房价)。
构建 MLP 最直观的方法,就是把这些数学运算像搭积木一样按顺序拼起来。R torch 提供了 nn_sequential 容器,它完全对应了数学上的复合函数逻辑。我们需要:
- 输入层:接收 13 个特征。
- 隐藏层:假设我们将特征扩展到 32 维。
- 输出层:回归任务只需要输出 1 个值。
代码如下2:
model <- nn_sequential(
nn_linear(13, 32), # 输入13个特征 -> 32个神经元
nn_relu(), # 非线性关系的层
nn_linear(32, 16), # 32 -> 16
nn_relu(), # 激活函数
nn_linear(16, 1) # 16 -> 输出1个预测值
)
print(model) # 打印模型结构在回归任务中,目标变量是一个连续的实数,我们希望输出范围不受限制,因此最后一层通常保持线性输出。
4.2.2 nn_module
在后续章节的实战中,我们将面对更复杂的训练需求。为了更好地管理代码和参数,我们需要掌握 torch 的核心范式:nn_module。
在 R torch 中,这通过 R6 类系统实现。定义一个模型类需要遵循两个核心步骤:
- initialize(我们要用什么零件?):定义这一层包含哪些子模块(如 nn_linear)。
- forward(零件怎么组装?):定义数据流向。
让我们把上面的房价预测模型重构为一个标准的 R6 类:
net <- nn_module(
classname = "net",
# 1. 构造函数:定义模型组件
initialize = function(in_dim = 13, h1 = 32, h2 = 16) {
self$fc1 <- nn_linear(in_dim, h1) # 输入层
self$fc2 <- nn_linear(h1, h2) # 隐藏层
self$fc3 <- nn_linear(h2, 1) # 输出层
},
# 2. 前向传播:定义数据流向
forward = function(x) {
x <- self$fc1(x) # 第一个线性层
x <- torch_relu(x) # relu 层
x <- self$fc2(x) # 第二个线性层
x <- torch_relu(x) # relu 层
x <- self$fc3(x) # 回归任务保持线性输出
x
}
)
# 实例化模型
model <- net(in_dim = 13, h1 = 32, h2 = 16)最后一步实例化结束后,就可以在 update 模块里调用 net 这个模型了。
虽然 nn_sequential 很好用,但作为工程师,我们需要更灵活的控制权,类的写法为未来留出了扩展空间,比如我们可能需要:
- Dropout:如果我们发现模型过拟合,可以在 forward 中轻松插入 nn_dropout。
- 在残差网络中需要跳跃连接。
- 在 forward 中打印调试信息,检查是否符合预期。
4.3 损失函数
在前面的章节中,我们反复提到“损失函数”的概念——它是衡量模型预测值与真实值之间差异的函数。如果说模型结构定义了如何计算预测,那么损失函数则定义了什么是好的预测。
4.3.1 均方误差(MSE)
对于回归问题(预测连续值),最常用的损失函数是均方误差(Mean Squared Error, MSE):
\[ L_{\text{MSE}} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 \]
其中 \(y_i\) 是真实值,\(\hat{y}_i\) 是预测值。MSE 的数学特性非常友好:
- 处处可导,适合梯度下降
- 对较大的误差给予更大的惩罚(平方效应)
- 在统计学中,当误差服从高斯分布时,最小化 MSE 等价于极大似然估计
很多情况下会把 MSE 开平方,得到 RMSE(Root Mean Squared Error,均方根误差)作为评价指标。它与原始目标变量具有相同的量纲,更便于解释模型的平均预测偏差。
但 MSE 对异常值(Outliers)比较敏感,因为平方会放大异常值的影响。作为替代,平均绝对误差(MAE)对异常值更鲁棒:
\[ L_{\text{MAE}} = \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i| \]
4.3.2 交叉熵损失
对于分类问题(预测离散类别),最常用的是交叉熵损失(Cross-Entropy Loss)。它衡量的是预测概率分布与真实分布之间的差异。
二分类交叉熵损失(Binary Cross-Entropy): \[ L_{\text{BCE}} = -\frac{1}{n} \sum_{i=1}^n \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right] \] 其中 \(y_i \in \{0, 1\}\) 是真实标签,\(\hat{y}_i \in (0, 1)\) 是预测为正类的概率(通常经过 Sigmoid 激活)。
多分类交叉熵损失(Categorical Cross-Entropy): \[ L_{\text{CCE}} = -\frac{1}{n} \sum_{i=1}^n \sum_{j=1}^C y_{ij} \log(\hat{y}_{ij}) \] 其中 \(C\) 是类别数,\(y_{ij}\) 是样本 \(i\) 属于类别 \(j\) 的 one-hot 编码,\(\hat{y}_{ij}\) 是预测概率(通常经过 Softmax 激活)。
交叉熵损失有几个重要特性:
- 当预测完全正确时(如 \(\hat{y}=1\) 对应 \(y=1\)),损失为 0
- 预测越错误,损失增长越快(呈对数增长)
- 在信息论中,交叉熵表示用预测分布 \(Q\) 来编码真实分布 \(P\) 所需的额外比特数
R torch 实现:
| 任务类型 | 输出层激活 | 损失函数 | 函数 |
|---|---|---|---|
| 回归 | 无(或线性) | MSE | nn_mse_loss() |
| 回归 | 无 | MAE | nn_l1_loss() |
| 二分类 | Sigmoid | 二元交叉熵 | nn_bce_with_logits_loss() |
| 多分类 | Softmax | 分类交叉熵 | nn_cross_entropy_loss() |
不同的损失函数会产生不同的梯度特性,直接影响优化过程:
MSE 的梯度: \[ \frac{\partial L_{\text{MSE}}}{\partial \hat{y}_i} = \frac{2}{n} (\hat{y}_i - y_i) \] 梯度与误差成正比,线性关系。
交叉熵的梯度(对于 Sigmoid 输出): \[
\frac{\partial L_{\text{BCE}}}{\partial \hat{y}_i} = \frac{\hat{y}_i - y_i}{\hat{y}_i(1 - \hat{y}_i)}
\] 当预测接近 0 或 1 时,分母很小,梯度会变得非常大。这可能导致训练不稳定,这也是为什么我们常用 nn_bce_with_logits_loss 的原因——它在数值上更稳定。
4.4 Ames 房价预测
本节我们将 modeldata(Kuhn 2025) 中的 Ames Housing 数据集为基础,探讨如何利用 torch 的模块化设计构建一个回归模型。
改数据集有:
- 观测数(房屋数量):2,930 套住宅
- 变量数量:约 82 个字段(在
modeldata::ames中) - 目标变量:
Sale_Price(房屋最终成交价)
变量(不完整)信息:
| 类别 | 示例变量 (英文) | 主要说明 |
|---|---|---|
| 标识与分区 | PID, MS_SubClass, MS_Zoning |
地块标识、建筑类型、区域规划 |
| 地块与位置 | Lot_Area, Neighborhood, Condition1 |
占地面积、所属社区、邻近条件 |
| 建筑与质量 | Overall_Qual, Year_Built, Year_Remod |
整体质量评分、建成年份、改建年份 |
| 外观与结构 | Exter_Qual, Roof_Style, Foundation |
外墙质量、屋顶样式、地基类型 |
| 生活空间 | Gr_Liv_Area, Full_Bath, TotRmsAbvGrd |
地上居住面积、卫生间数量、总房间数 |
| 地下室 | Total_Bsmt_SF, Bsmt_Qual |
地下室总面积、地下室质量 |
| 车库 | Garage_Type, Garage_Cars, Garage_Area |
车库类型、车库容量、车库面积 |
| 设施与功能 | Fireplaces, Heating_QC, Central_Air |
壁炉数量与质量、供暖质量、中央空调 |
| 户外设施 | Wood_Deck_SF, Open_Porch_SF, Pool_Area |
木平台、开放式门廊、泳池面积 |
| 销售信息 | Sale_Type, Sale_Condition, Yr_Sold |
销售类型、销售条件、售出年份/月份 |
| 目标变量 | SalePrice |
房屋最终售价 |
首先是数据预处理,利用 tidymodels 包中的函数将数据分为训练集和测试集
library(tidymodels)
library(torch)
library(tidyverse)
data(ames)
set.seed(123)
torch_manual_seed(123)
ames_split <- initial_split(ames, prop = 0.80)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)关于使用 tidymodels 切分数据集的相关方法,会在第 6 章展开说明。
定义数据处理的 pipeline,依次是
- 定义目标变量(Label)和预测变量(Features),预测变量为除去
Sale_Price以外的全部,数据源为ames_train。 - 对目标变量执行标准化 (Normalization)
- 剔除对预测无用的 ID 列。
- 对居住面积这个变量取 Log10。
- 如果某个社区(Neighborhood)的房子数量少于总数的 1%,就把它强制改名为 “Other”。
- 对 factor 或 character 类型变量执行独热编码 (One-Hot Encoding),把文字变为数字。
- 零方差剔除 (剔除那些所有样本都一样的无用特征)
- 对所有的变量执行标准化 (Normalization)
- 对数值型变量执行中位数补全操作
- 对 factor 或 character 类型变量执行众数补全操作
以上 10 个操作步骤对应的 R 代码:
rec <- recipe(Sale_Price ~ ., data = ames_train) %>%
step_normalize(all_outcomes()) %>%
step_rm(matches("Id")) %>%
step_log(Gr_Liv_Area, Lot_Area, base = 10) %>%
step_other(all_nominal_predictors(), threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
step_nzv(all_predictors()) %>%
step_normalize(all_predictors()) %>%
step_impute_median(all_numeric_predictors()) %>%
step_impute_mode(all_nominal_predictors())这里的目标变量执行了 Normalization 操作,在预测结束之后还需要做逆向操作。即预测值加上 ames_train 数据集的目标变量均值,再乘以 ames_train 数据集的目标变量的方差。
上面的函数定义了数据处理流程,但并不执行。接下来开始执行:
prep_rec <- prep(rec)
train_df <- bake(prep_rec, new_data = NULL)
test_df <- bake(prep_rec, new_data = ames_test)train_df 就是自己,但 test_df 的均值方差、中位数、众数要从 ames_train 继承,这样才能保证信息没有泄露给 test_df 数据集。
接着将训练集和测试集数据转为 tonsor:
x_train <- torch_tensor(
as.matrix(train_df %>% select(-Sale_Price)),
dtype = torch_float())
y_train <- torch_tensor(
matrix(train_df$Sale_Price, ncol=1),
dtype = torch_float())
x_test <- torch_tensor(
as.matrix(test_df %>% select(-Sale_Price)),
dtype = torch_float())
y_test <- torch_tensor(
matrix(test_df$Sale_Price, ncol=1),
dtype = torch_float())构建一个多层感知机,它的结构如下:
输入层 (ncol(x_train)) -> 隐藏层 (128, ReLU) -> 隐藏层 (64, ReLU) -> 输出层 (1)
结构并不复杂,我们使用 nn_sequential 来实现该模型(读者也可以尝试改成 nn_module 来实现):
model <- nn_sequential(
nn_linear(ncol(x_train), 128), # 输入特征 -> 128个神经元
nn_relu(), # 激活函数
nn_linear(128, 64), # 128 -> 64
nn_relu(), # 激活函数
nn_linear(64, 1) # 64 -> 输出1个预测值
)定义优化器和损失函数:
learning_rate <- 0.0025
optimizer <- optim_adam(model$parameters, lr = learning_rate)
loss_fn <- nn_mse_loss()接着开始循环训练:
epochs <- 1000
# 用于记录 loss 变化以便画图
train_losses <- numeric(epochs)
for (t in 1:epochs) {
# 前向传播
y_pred <- model(x_train)
loss <- loss_fn(y_pred, y_train)
# 梯度求解三部曲
optimizer$zero_grad()
loss$backward()
optimizer$step()
train_losses[t] <- loss$item() # 用于记录与打印
if (t %% 50 == 0) {
cat(sprintf("Epoch %d: Loss = %.4f\n", t, loss$item()))
}
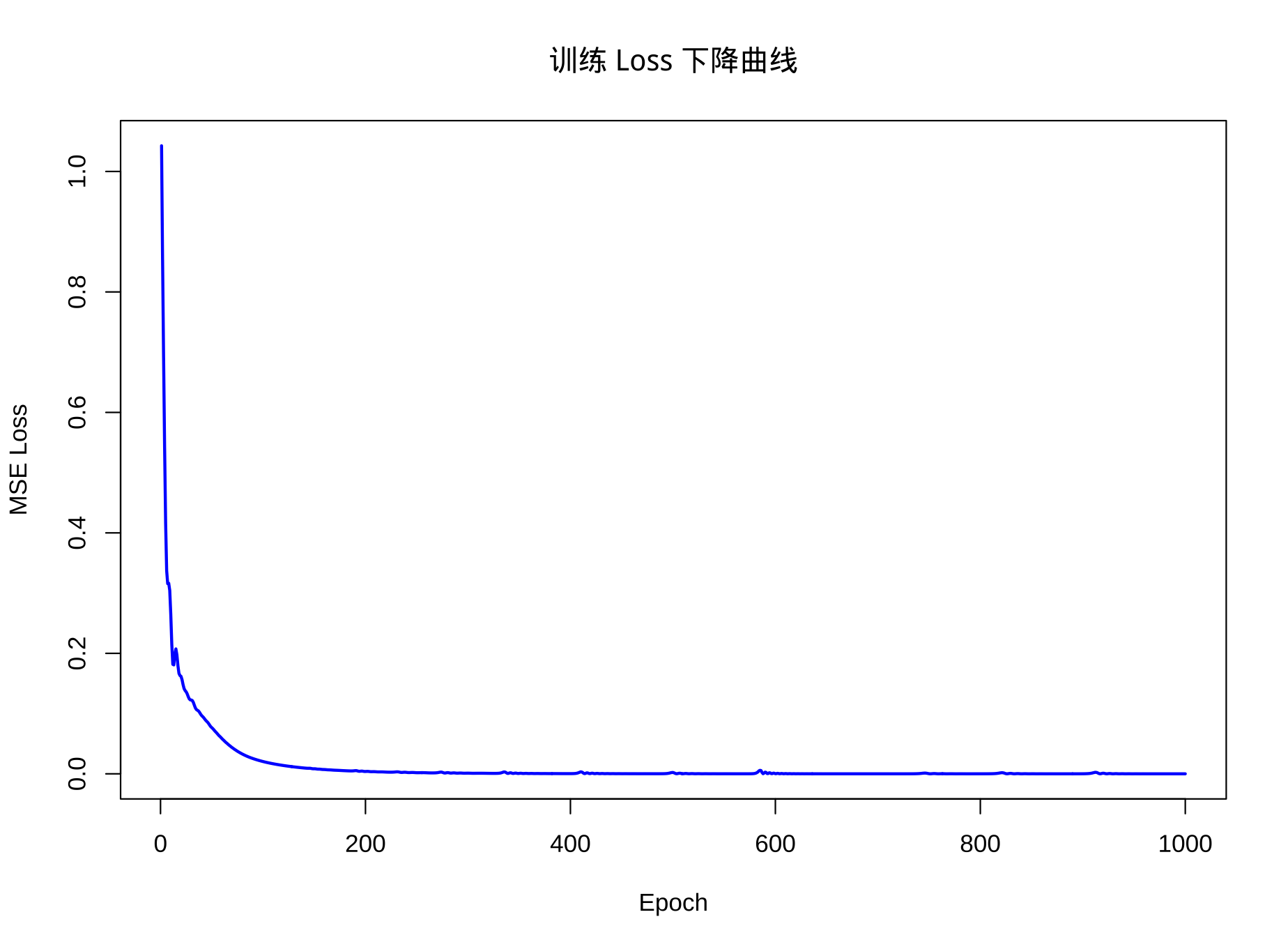
}可以看到模型的 loss 下降很快:
手工计算 RMSE
# 切换到评估模式 (虽然本例没用 Dropout,但养成好习惯)
model$eval()
with_no_grad({
preds_nn <- as.numeric(model(x_test))
})
# 计算 RMSE
truth <- as.numeric(y_test) # 真实标签
rmse_nn <- sqrt(mean((truth - preds_nn)^2))对比原生 lm 方法
fit_lm <- lm(Sale_Price ~ ., data = train_df)
# 预测测试集
preds_lm <- predict(fit_lm, newdata = test_df)
# 计算 RMSE (均方根误差)
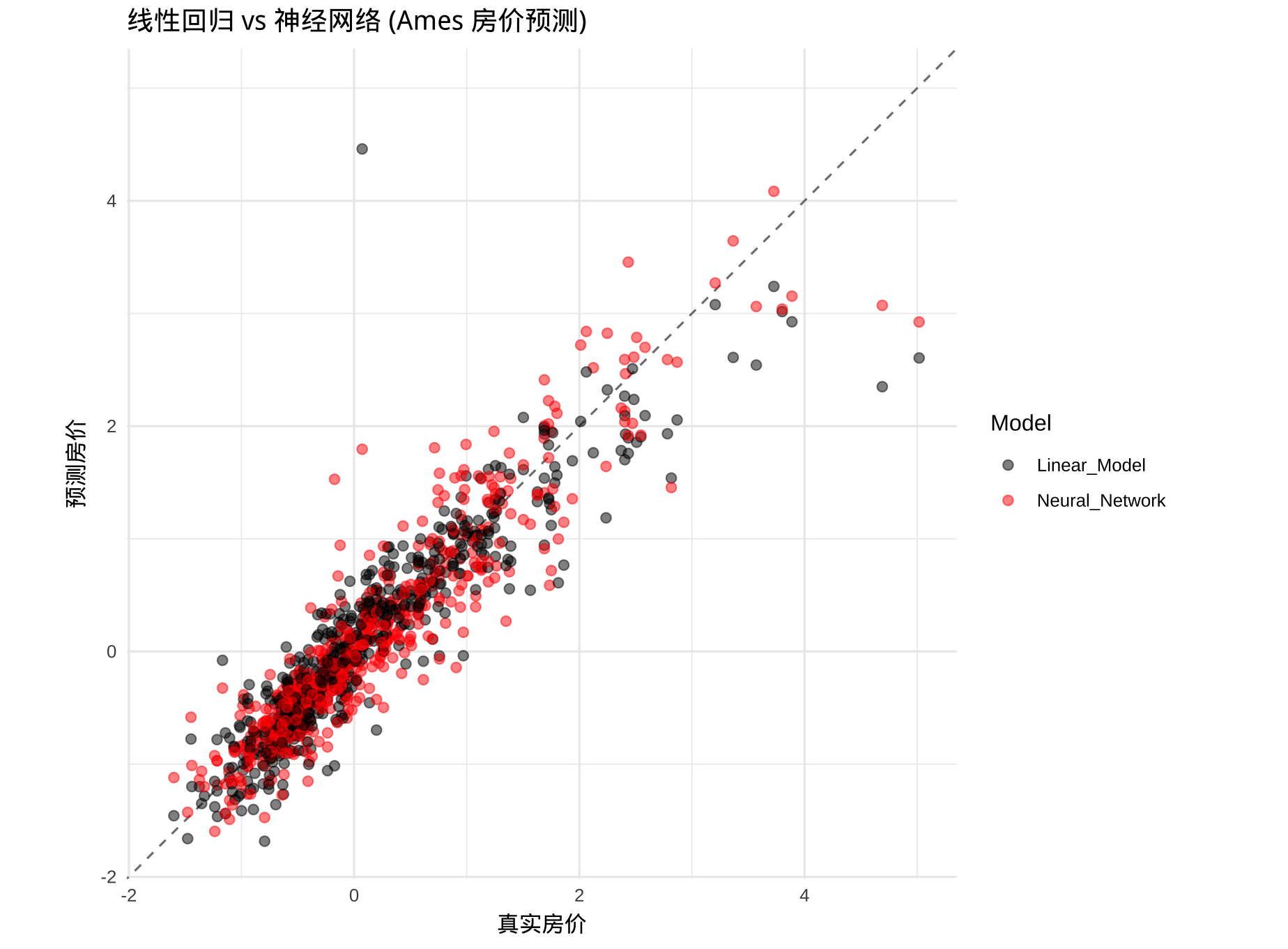
rmse_lm <- sqrt(mean((test_df$Sale_Price - preds_lm)^2))对比原生 R 方法,torch 版本的 MLP 模型在测试集上的 RMSE 差异
| 基准模型 (lm) MSE | 深度模型 (MLP) RMSE |
|---|---|
| 0.3885 | 0.3527 |
即便是在我们盲猜参数没有任何优化的情况下,MLP 因为引入了非线性变化,对于 RMSE 这个指标而言,还是略胜一筹。
打印真实值和预测值的散点图做两个方法的对比: