9 Transformer
“我可以同时看到一切。”
—— 《瞬息全宇宙》(2022)
主角伊芙琳在觉醒瞬间,意识连接了无数平行宇宙中的自己。她不再受限于单一的时间线,而是能够同时感知所有宇宙的信息,瞬间捕捉到所有事物之间的关联。
9.1 注意力机制
在上一章的 Seq2Seq 模型中,我们了解到将长序列信息压缩成一个固定长度的向量,会导致信息瓶颈和长距离遗忘。为了解决这个问题,注意力机制 (Bahdanau 等 2016) 在 2014 年被引入。然而,真正让注意力机制大放异彩的,是 2017 年 Google 团队发表的里程碑论文《Attention Is All You Need》 (Vaswani 等 2017)。这篇论文彻底革新了传统架构,抛弃了循环神经网络(RNN)和卷积神经网络(CNN),提出了一种纯粹基于注意力的模型——Transformer。
本节我们将深入 Transformer 的核心组件:缩放点积注意力 (Scaled Dot-Product Attention) 和多头注意力 (Multi-Head Attention),并解释模型如何通过位置编码 (Positional Encoding) 理解时间序列的先后顺序。
回想一下我们预测北京气温的情境:当你预测第 73 小时的气温时,不应该只依赖一个模糊的“过去 72 小时总结”。相反,你需要拥有“上帝视角”——能够清晰洞察过去 72 小时中每一个时间点上的具体情况。
- RNN:依赖通过循环逐步更新的隐藏状态来捕捉序列信息。随着序列长度增加,早期信息容易被稀释,必须串行计算,极慢。
- Attention:站在当前时刻,瞬间纵览过去 72 小时,并精准聚焦于那些与当前状态最相关的历史瞬间。全矩阵并行计算,极快。
9.1.1 物理意义
在理解复杂的公式前,我们需要建立一个直观的思维模型。Transformer 将注意力机制巧妙地抽象为三个向量的概念:Query (查询)、Key (键) 和 Value (值)。
首先,模型接收到的通常是低维的物理数据(例如过去 72 小时的气象数据,每个时间点有 7 个指标,即输入特征维度为 7)。如果我们直接在 7 维空间做注意力计算,它太“窄”了,不足以承载复杂的上下文关系。
因此,Transformer 通过三个不同的可学习权重矩阵 \(W^Q, W^K, W^V\),直接将原始输入矩阵 \(X\) 扩容并投影到更宽的 \(d_{model}\) 维度(例如 64)子空间中,分别生成 \(Q, K, V\) 矩阵:
\[ Q = XW^Q, \quad K = XW^K, \quad V = XW^V \]
\(W^Q, W^K, W^V\) 实际是一个特征层,它的作用非常单纯:扩容。如果我们做天气预测有原始的温度、气压等气象指标,它们太“窄”了,不足以承载复杂的注意力计算。我们需要通过线性变换将其映射到更宽的 \(d_{model}\) 维度(例如 64)。
# d_input = 7 (原始特征数)
# d_model = 64 (模型内部维度)
self$input_proj <- nn_linear(input_size, d_model)在这里,\(W^Q, W^K, W^V\) 实际就是特征扩容的桥梁。它们不包含激活函数,作用非常单纯:把数据从具体的物理空间直接搬运并映射到高维的语义特征空间。
为了预测明天(第 73 小时)的气温,请想象你正站在当前时刻,试图从历史数据中寻找线索:
- (\(Q\))uery - 当前的查询意图:这是一个基于当前第 72 小时状态(如“西北风劲吹、气压升高”)生成的向量。其物理含义不再是客观数据本身,而是模型发出的搜索意图——“我在寻找历史上那些同样发生过冷锋过境的时刻”。
- (\(K\))ey - 历史时刻的特征键:这是过去 72 小时中每一个时间点(例如第 20 小时)生成的特征标签。如果第 20 小时也是大风降温天,它的 \(K\) 向量就会被标记为“冷锋过境”,正好能响应 \(Q\) 的查询。
- (\(V\))alue - 历史时刻的实际内容:这是第 20 小时的具体状态记录。当 \(Q\) 和 \(K\) 匹配成功后,我们提取的不是标签 \(K\),而是第 20 小时对应的实际内容 \(V\)。
注意力机制的核心,就是一场“历史重演”式的检索过程:它计算当前查询 \(Q\) 与历史所有标签 \(K\) 的相似度。如果 \(Q\) 与第 20 小时的 \(K\) 匹配度极高,模型就会给予更多“注意力”,从中提取第 20 小时的 \(V\)。
设计意图 vs. 训练现实
初学者常有一个困惑:模型怎么知道什么是“冷锋过境”?实际上,在模型刚初始化、还未进行反向传播训练时,\(W^Q, W^K, W^V\) 仅仅是随机生成的数值。此时的 \(Q, K, V\) 完全是一团乱码。前面描述的“物理意义”,实际上是注意力机制的设计意图——通过巧妙的架构安排,赋予了模型这种检索能力。只有当模型“阅读”了海量的气象数据,并通过反向传播不断更新 \(W^Q, W^K, W^V\) 的数值后,这些矩阵才真正具备了提取“搜索意图”和“气象特征”的能力。
9.1.2 缩放点积注意力
Transformer 的引擎是缩放点积注意力 (Scaled Dot-Product Attention)。其核心公式如下:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
传统的全连接层(MLP)或卷积层(CNN),它们的权重参数是静态的。无论输入什么数据,乘以的权重矩阵都是固定的。但 Self-Attention 的绝妙之处在于,它的“注意力权重”是由输入数据自我交互计算出来的。这种“输入决定权重,权重再作用于输入”的机制,赋予了它极强的动态上下文感知能力。
为了透视这个精妙的公式,我们通过 R 的 torch 底层张量操作,将其拆解并构建为一个高度自适应的自注意力模块。这里我们设定输入矩阵 \(X\) 的特征维度(embed_dim)在经过 \(Q, K, V\) 投影时保持不变,以此来专注理解其核心机制:
library(torch)
SelfAttention <- nn_module(
"SelfAttention",
initialize = function(input_dim, embed_dim) {
self$embed_dim <- embed_dim
# 步骤 1:投影层和权重矩阵合二为一
# W_q, W_k, W_v 直接负责将原始 7 维数据扩容到 64 维的 Q, K, V 空间
self$W_q <- nn_linear(input_dim, embed_dim, bias = FALSE)
self$W_k <- nn_linear(input_dim, embed_dim, bias = FALSE)
self$W_v <- nn_linear(input_dim, embed_dim, bias = FALSE)
# 增加输出映射层:注意力计算完成后,将结果重新整合
self$W_o <- nn_linear(embed_dim, embed_dim, bias = FALSE)
},
forward = function(x) {
# 假设输入 x 是原始气象数据,维度为 (Batch=32, Seq_Len=72, Input_Dim=7)
# 步骤 1:通过线性层扩容并生成 Q, K, V
Q <- self$W_q(x) # 维度瞬间变为 (32, 72, 64)
K <- self$W_k(x) # (32, 72, 64)
V <- self$W_v(x) # (32, 72, 64)
# 步骤 2:相似度计算 QK^T
# 使用 -2 和 -1 翻转最后两个维度,兼容不同 Batch Size
K_transposed <- K$transpose(-2, -1)
scores <- torch_matmul(Q, K_transposed) # 输出维度: (32, 72, 72)
# 步骤 3:缩放 (Scaled)
# 除以特征维度的平方根,避免点积结果方差过大导致 Softmax 梯度消失
scores <- scores / sqrt(self$embed_dim)
# 步骤 4:归一化 (Softmax)
# dim = -1 表示在最后一个维度(序列长度)上做 softmax
attention_weights <- nnf_softmax(scores, dim = -1)
# 步骤 5:加权求和与输出映射
context <- torch_matmul(attention_weights, V) # 上下文融合: (32, 72, 64)
out <- self$W_o(context) # 最终输出: (32, 72, 64)
return(list(out = out, weights = attention_weights))
}
)仔细观察这段代码,你会发现 Transformer 内部根本没有 for 循环!不管序列是 72 小时还是 7200 小时,所有的相似度计算、特征对齐与上下文融合,都在矩阵乘法中瞬间、并行地完成了。
9.1.3 多头注意力
理解了单头注意力后,我们面临一个现实问题:数据规律往往是多维度的。过去 72 小时里,气压、风向、湿度可能各自蕴含着不同的变化线索。如果只有一个“注意力头”,它可能会被迫把这些线索平均化,导致关键信息丢失。
多头注意力机制允许模型同时在不同的表示子空间 (Representation Subspaces) 学习信息。这就好比我们同时聘请了 \(h\) 位不同领域的专家,来并行分析同一段 72 小时的数据:
- 专家 A (Head 1):专注于短期剧烈波动(如寻找气压断崖式下跌的时刻)。
- 专家 B (Head 2):专注于日周期性规律(如对比昨天同一时刻的温差)。
- 专家 C (Head 3):专注于跨变量相关性(如评估累计降水对当前湿度的滞后影响)。
假设我们有 \(h\) 个头(Heads):对每个头 \(i\),独立计算注意力:
\[ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) \]
最后,我们将所有“专家”的分析结果拼接 (Concatenate) 在一起,并通过一个线性投影矩阵 \(W^O\) 进行最终融合:
\[ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O \]
注意一个细节:假设我们输入矩阵 \(X\) 的特征维度(embed_dim)是 64,我们设定 8 个注意力头(num_heads = 8)。模型并不会生成 8 个 64 维的矩阵,而是将这 64 维空间平均劈开,分配给 8 个头。每个头只在一个 8 维的子空间(head_dim = 64 / 8 = 8)里进行 \(Q, K, V\) 的投影和注意力计算。
通过这种多头并行机制,模型不仅打破了 RNN 的速度瓶颈,更捕捉到了极其丰富的多维度特征组合。
在代码层面,多头注意力的魔法完全依赖于张量的维度重塑 (view) 和维度交换 (transpose)。我们将原来的 3 维张量 (Batch, Seq_Len, Embed_Dim) 拆解为 4 维张量 (Batch, Seq_Len, Num_Heads, Head_Dim),然后交换维度以便并行计算。
library(torch)
MultiHeadAttention <- nn_module(
"MultiHeadAttention",
initialize = function(embed_dim, num_heads) {
self$embed_dim <- embed_dim
self$num_heads <- num_heads
# 确保特征维度可以被头数整除
if (embed_dim %% num_heads != 0) {
stop("embed_dim 必须能被 num_heads 整除!")
}
self$head_dim <- embed_dim / num_heads
# 依然是一次性生成所有头的 Q, K, V (这比写 8 个独立的线性层高效得多)
self$W_q <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$W_k <- nn_linear(embed_dim, embed_dim, bias = FALSE)
self$W_v <- nn_linear(embed_dim, embed_dim, bias = FALSE)
# 输出融合层
self$W_o <- nn_linear(embed_dim, embed_dim, bias = FALSE)
},
forward = function(x) {
batch_size <- x$shape[1]
seq_len <- x$shape[2]
# 步骤 1:线性投影
Q <- self$W_q(x) # (Batch, 72, 64)
K <- self$W_k(x)
V <- self$W_v(x)
# 步骤 2:拆分特征维度为多个头
# 将 (Batch, 72, 64) 重塑为 (Batch, 72, 8, 8)
Q <- Q$view(c(batch_size, seq_len, self$num_heads, self$head_dim))
K <- K$view(c(batch_size, seq_len, self$num_heads, self$head_dim))
V <- V$view(c(batch_size, seq_len, self$num_heads, self$head_dim))
# 步骤 3:转置,将“头”的维度提前,以便在各个头内部独立计算注意力
# 转置后维度: (Batch, 8, 72, 8)
# 注意:R 中 transpose 的索引是从 1 开始的,2 和 3 分别代表 Seq_Len 和 Num_Heads
Q <- Q$transpose(2, 3)
K <- K$transpose(2, 3)
V <- V$transpose(2, 3)
# 步骤 4:多头缩放点积注意力并行计算
# K 转置最后两个维度用于矩阵乘法: (Batch, 8, 8, 72)
K_transposed <- K$transpose(3, 4)
# scores 维度: (Batch, 8, 72, 72) - 包含了 8 个不同的 72x72 注意力矩阵!
scores <- torch_matmul(Q, K_transposed) / sqrt(self$head_dim)
attention_weights <- nnf_softmax(scores, dim = 4)
# 加权求和: (Batch, 8, 72, 8)
context <- torch_matmul(attention_weights, V)
# 步骤 5:拼接多个头的结果
# 先转置回 (Batch, 72, 8, 8),必须调用 contiguous() 让内存连续,才能使用 view 拼接
context <- context$transpose(2, 3)$contiguous()
# 重新拼接回 (Batch, 72, 64)
context_concat <- context$view(c(batch_size, seq_len, self$embed_dim))
# 步骤 6:通过最终的线性层融合各头的信息
out <- self$W_o(context_concat)
return(list(out = out, weights = attention_weights))
}
)通过这种设计,Transformer 实现了既能在不增加计算瓶颈的情况下“眼观六路”,又能保持高度的并行计算效率。
9.2 完全体架构
在上一节中,我们构建了强大的缩放点积注意力(Self-Attention)机制。它能瞬间完成全局特征的交互,且高度并行。你可能会觉得,只要把这个机制套用在时间序列上,一切预测问题都能迎刃而解。 但实际情况是,单独的注意力机制根本无法处理时间序列问题。
9.2.1 失败的实验
我们设计一个极简的“序列反转”任务:
- X:一段长度为 10 的随机特征序列(例如 [第 1 天, 第 2 天, …, 第 10 天])。
- Y:要求模型输出完全倒序的序列(即 [第 10 天, 第 9 天, …, 第 1 天])。
“反转”是一个纯粹的空间/时间位置概念。如果是一个传统的全连接层(MLP),它拥有固定的位置权重,很容易就能学到“倒序排座”的规律。但是,当我们用原生的自注意力模块来挑战这个任务时,情况会怎样呢?
让我们直接看代码。我们定义一个只包含特征扩容和自注意力的 SimpleTransformer(残缺版):
# SelfAttention 同第一节。
# 仅包含注意力机制的 transformer
SimpleTransformer <- nn_module(
"SimpleTransformer",
initialize = function(input_dim, embed_dim, output_dim) {
self$input_proj <- nn_linear(input_dim, embed_dim)
self$attention <- SelfAttention(embed_dim)
self$final_proj <- nn_linear(embed_dim, output_dim)
},
forward = function(x) {
# 1. 特征扩容
x_emb <- self$input_proj(x)
# 2. 直接进行注意力计算 (路痴状态)
att_out <- self$attention(x_emb)
# 3. 输出预测
preds <- self$final_proj(att_out$out)
return(list(preds = preds, weights = att_out$weights))
}
)
# 统一的序列反转任务
seq_len <- 10
input_dim <- 4
embed_dim <- 32
batch_size <- 64
num_epochs <- 150
# 随机生成 10 天的特征,目标为严格倒序输出
X_train <- torch_randn(batch_size, seq_len, input_dim)
Y_train <- torch_flip(X_train, dims = 2)
# 训练残缺版模型
model_simple <- SimpleTransformer(input_dim, embed_dim, input_dim)
opt_simple <- optim_adam(model_simple$parameters, lr = 0.005)
loss_fn <- nn_mse_loss()
for (epoch in 1:num_epochs) {
opt_simple$zero_grad()
out_simple <- model_simple(X_train)
loss <- loss_fn(out_simple$preds, Y_train)
loss$backward()
opt_simple$step()
if (epoch %% 30 == 0 || epoch == 1) {
cat(sprintf("Epoch %3d | Loss: %.4f\n", epoch, loss$item()))
}
}
# (此处省略提取 attention_weights 绘制热力图的代码)![]()
当你运行这段代码,你会看到损失函数(Loss)降到一个固定值后就死死卡住。如果你提取它的注意力权重热力图,无论怎么训练,永远是一片糊成一团的浅色马赛克。模型彻底失败了。
为什么会这样?回到最底层的公式:\(\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)。在这个纯粹的矩阵乘法中,没有任何一个地方包含了时间顺序信息。在原生注意力的眼中,输入序列并不是排好队的,而是一个打乱了塞在麻袋里的无序集合(Set)。
让一个根本不认路的“无序集合处理器”去执行“反转排列”的指令,犹如蒙眼摸象。如果不加任何干预,原生 Attention 是“排列等变”的,在需要严格时间先后顺序的预测中,这是致命缺陷。
9.2.2 位置编码
既然模型不知道位置,我们显式地告诉它不就行了吗?这就是 Transformer 作者极其优雅的解法:位置编码 (Positional Encoding, PE)。
\[ X_{pos} = X + PE \]
在张量形态上,PE 是一个与特征矩阵 \(X\) 形状完全相同的矩阵。假设我们的输入 \(X\) 是一段长度为 10 的序列,特征维度被扩容到了 32 维,那么 \(X\) 的形状是 (10, 32)。对应的,PE 也会是一个 (10, 32) 的矩阵。
公式中的加号 + 代表的是按元素相加 (Element-wise Addition)。这意味着:
- 序列第 1 个时间点的原始特征向量,直接加上了 PE 矩阵的第 1 行向量。
- 序列第 10 个时间点的原始特征向量,直接加上了 PE 矩阵的第 10 行向量。
经过这个简单的加法,原本纯粹表示“客观数据”的特征高维空间里,就被强行揉进去了一段表示“空间绝对位置”的信号。
既然要加特征,为什么不把 32 维的 \(X\) 和 32 维的 \(PE\) 拼接成 64 维? 实际上,拼接和相加在数学上是高度等价的(相加可以看作是拼接后乘上了一个特定的对角权重矩阵)。但直接相加不增加任何额外的参数维度和计算量,极其节省显存。在高维空间(如 64 维或 512 维)中,特征向量的容量极大,直接把位置信号叠加在语义信号上,模型凭借后续的多头注意力和 FFN,完全有能力把“内容”和“位置”重新解耦并提取出来。
关于位置编码,业界有很多实现方式。篇幅所限,这里仅介绍三种有代表性的做法:
- 正余弦位置编码 (Sinusoidal PE):这是 2017 年《Attention Is All You Need》原论文使用的方法。作者利用不同频率的正弦 (\(\sin\)) 和余弦 (\(\cos\)) 函数,为每个时间步计算出一组绝对固定的 32 维向量。这种设计的绝妙之处在于,正余弦函数的周期性能够让模型感知到位置之间的“相对距离”(比如第 3 天和第 5 天的距离,等于第 8 天和第 10 天的距离)。
- 可学习位置编码 (Learnable PE):这是目前绝大多数现代大模型(如 BERT, GPT 系列)以及我们会采用的方法。把“位置索引”(1, 2, …, 10)当成字典里的词汇,利用 R torch 中的
nn_embedding直接为每一个位置初始化一个随机的 n 维向量。在反向传播的过程中,模型会根据任务的需要,自己去“学”出最完美的位置向量表示。 - 带有线性偏差的注意力 (Attention with Linear Biases) ,简称 ALiBi (Press 等 2022) 是极其优雅且计算极快的相对位置编码方案。常用于多头注意力框架,思想是不在输入特征上加任何位置编码,而是在计算出 Attention 权重矩阵(\(Q \cdot K^T\))之后,直接在矩阵上“扣分”。比如两个时间步相距 5 个小时,我就在它们的注意力得分上减去 \(5 \times m\)(\(m\) 是一个固定的惩罚斜率)。距离越远,强制扣除的分数越多。这种机制造成了它有极其强大的外推能力(Extrapolation),模型用 72 小时的数据训练,但给 ALiBi 144 小时数据,模型也不会崩。
9.2.3 Add & Norm 与 FFN
Attention 的本质是一个加权求和操作,它极其擅长把序列中相关的特征“搬运”并混合在一起,但它有两个致命的短板:网络加深容易崩溃:纯粹的矩阵连乘会导致梯度消失或爆炸。缺乏深度的非线性变换:Attention 只是线性地混合了 \(V\) 矩阵,它本身对特征的非线性加工能力极弱。因此,我们需要为它加装另外两个关键逻辑:
1. 残差连接与层归一化 (Add & Norm)
在 Transformer 的每一个子模块(Attention 和 FFN)后面,都紧跟着一个 Add & Norm 层。其数学表达为:
\[ Z = \text{LayerNorm}(X + \text{SubLayer}(X)) \]
Add (残差连接 Residual Connection):
由于网络在刚开始训练时,Attention 计算出的权重完全是随机噪声,如果直接把原始数据丢给 Attention 处理,信息会瞬间崩塌。残差连接保证了:即使 Attention 在胡言乱语,原始的输入信息 \(X\) 也能通过这条“短路”原封不动地传递到下一层。 它给了模型试错的底气,让 Transformer 可以轻松堆叠到几十甚至上百层(如 GPT-3 的 96 层)而不至于梯度消失。
Norm (层归一化 Layer Normalization):
在图像处理中,我们常用批归一化(BatchNorm)。但在时间序列和 NLP 中,序列的长度往往参差不齐,大量的 Padding(填充)会导致 BatchNorm 算出的均值和方差产生严重偏差。 Transformer 巧妙地使用了 LayerNorm。它不再跨越 Batch 去求均值,而是对每一个时间步的特征向量(例如那 64 维特征)单独进行归一化。它将这 64 个数值拉回均值为 0、方差为 1 的正态分布,抹平了极端异常值的影响,确保特征在深层流动的稳定性。
2. 逐位置前馈神经网络 (Position-wise FFN)
在 R torch 的代码中,它长这样:
self$ffn <- nn_sequential(
nn_linear(embed_dim, embed_dim * 4),
nn_relu(),
nn_linear(embed_dim * 4, embed_dim)
)在传统的 MLP 中,输入通常是 2D 张量 (Batch_Size, Features),矩阵乘法发生在特征维度上。而在 Transformer 中,传入 FFN 的数据是 3D 张量,例如:(Batch=64, Seq_Len=10, Embed_Dim=32)。
当 torch 引擎识别到输入为 3D 张量,而线性层的权重 \(W\) 为 2D 张量 (32, 128) 时,会自动触发高维广播机制(Batched Matrix Multiplication):仅在最后一个维度 (Embed_Dim) 上独立执行矩阵乘法。
在数学计算上,权重矩阵 \(W\) 会遍历 Seq_Len 维度。第 1 天的 32 维特征与第 2 天的特征,在 FFN 层内部绝对没有发生任何交互运算。它们共享同一套权重 \(W\),但彼此完全平行。这就从工程底层实现了极其严格的“逐位置独立”。
注意看它的结构:
- 通过 \(QK^T\) 计算,张量在 Seq_Len 维度上发生运算,提取全局上下文。Self-Attention 的核心任务是“找关系”和“搬运特征”。
- 接收 Attention 混合后的特征后,FFN 通过两层线性变换(先放大 4 倍维度以在高维空间寻找复杂模式,再压缩回原维度)配合 ReLU 激活函数,独立对每个时间步进行深度的非线性特征提取。
9.2.4 实现完全体
我们将注意力机制、embedding 位置编码、Add & Norm 和 FFN 拼装成完全体,让它去挑战完全相同的序列反转任务。
首先是定义的是 TransformerBlock,里面包含了模块 Attention + Add & Norm + FFN :
TransformerBlock <- nn_module(
"TransformerBlock",
initialize = function(embed_dim) {
self$attention <- SelfAttention(embed_dim)
self$norm1 <- nn_layer_norm(embed_dim)
self$norm2 <- nn_layer_norm(embed_dim)
self$ffn <- nn_sequential(
nn_linear(embed_dim, embed_dim * 4),
nn_relu(),
nn_linear(embed_dim * 4, embed_dim)
)
},
forward = function(x) {
att_out <- self$attention(x)
x <- self$norm1(x + att_out$out)
ffn_out <- self$ffn(x)
x <- self$norm2(x + ffn_out)
return(list(out = x, weights = att_out$weights))
}
)接下来是 + PE 的完全体:
FullTransformer <- nn_module(
"FullTransformer",
initialize = function(input_dim, embed_dim, output_dim, max_len = 10) {
self$input_proj <- nn_linear(input_dim, embed_dim)
# 可学习的位置编码
self$pos_embed <- nn_embedding(num_embeddings = max_len,
embedding_dim = embed_dim)
self$transformer_block <- TransformerBlock(embed_dim)
self$final_proj <- nn_linear(embed_dim, output_dim)
},
forward = function(x) {
batch_size <- x$shape[1]
seq_len <- x$shape[2]
x_emb <- self$input_proj(x)
# 强行注入时间戳:X + PE
positions <- torch_arange(1, seq_len, dtype = torch_long())
pos_embeddings <- self$pos_embed(positions)
x_combined <- x_emb + pos_embeddings
block_out <- self$transformer_block(x_combined)
preds <- self$final_proj(block_out$out)
return(list(preds = preds, weights = block_out$weights))
}
)最后是利用前面生成的 X_train 和 Y_train 训练模型:
model_full <- FullTransformer(input_dim, embed_dim, input_dim, max_len = seq_len)
opt_full <- optim_adam(model_full$parameters, lr = 0.005)
for (epoch in 1:num_epochs) {
opt_full$zero_grad()
out_full <- model_full(X_train)
loss <- loss_fn(out_full$preds, Y_train)
loss$backward()
opt_full$step()
if (epoch %% 30 == 0 || epoch == 1) {
cat(sprintf("Epoch %3d | Loss: %.4f\n", epoch, loss$item()))
}
}![]()
控制台的输出会显示,完全体的 Loss 一路狂奔,直接跌到了极低的水平。观察它的热力图,会看到一条极其锐利的绿色反对角线从右上角贯穿至左下角。这条对角线意味着,加上了位置编码和逻辑大脑的 Transformer,完美听懂了“倒序”的指令。当它生成第 1 个输出时,精准地把 100% 的注意力打在了输入的第 10 个时间点上(同理,第 2 对应第 8)。
9.3 重构时序预测模型
为了理解 transformer 的原理,我们从底层使用 nn_linear 和矩阵乘法,手动拼装出了完整的 Transformer 编码器层。这让我们彻底看清了自注意力、残差连接和层归一化的内部流转。但在实际工程中,我们不需要重新造轮子。R torch 提供了高度优化的原生 C++ 后端实现:
nn_multihead_attention:多头注意力机制,支持attn_mask参数,如果是 Float 类型,可以直接加在注意力权重上,做变换操作。nn_transformer_encoder_layer:单个编码器层,包含多头自注意力 (Multi-Head Self-Attention) + 前馈网络 (Feedforward Network),以及残差连接和层归一化。nn_transformer_encoder:由多个nn_transformer_encoder_layer堆叠而成,形成完整的编码器部分。
如果读者有兴趣,可以观察 nn_transformer_encoder_layer 函数的定义,是否和我们的实现一致。
nn_transformer_encoder_layer$public_methods$initialize
nn_transformer_encoder_layer$public_methods$forward9.3.1 原生代码实现
在我们的北京气温预测任务中,目标是根据过去 72 小时的信息,预测第 73 小时(即未来第一个时间点)的气温。因此,我们通常会选择 Transformer 输出序列中最后一个时间步(即第 72 小时)对应的特征表示来作为预测的依据。
最后一个时间步的特征,已经融合了模型对过去所有时间点的注意力信息,被认为是当前时刻最有代表性的上下文总结,可以直接喂给 self$decoder 层进行最终预测。
tsTransformer_Native <- nn_module(
"tsTransformer_Native",
initialize = function(
input_size, d_model, nhead, seq_len, num_layers = 1, dropout = 0.1) {
self$proj <- nn_linear(input_size, d_model)
self$pos_embed <- nn_embedding(
num_embeddings = seq_len, embedding_dim = d_model)
# 原生 Transformer Layer
encoder_layer <- nn_transformer_encoder_layer(
d_model = d_model,
nhead = nhead,
dropout = dropout,
batch_first = TRUE
)
self$transformer <- nn_transformer_encoder(
encoder_layer, num_layers = num_layers)
self$decoder <- nn_linear(d_model, 1)
},
forward = function(x) {
seq_length <- x$shape[2]
x_emb <- self$proj(x)
positions <- torch_tensor(1:seq_length, dtype=torch_long(), device=x$device)
pos_embeddings <- self$pos_embed(positions)
x_combined <- x_emb + pos_embeddings
# 直接由原生 Encoder 处理
x_out <- self$transformer(x_combined)
last_step_features <- x_out[, seq_length, ]
pred <- self$decoder(last_step_features)
return(pred)
}
)调用 luz 包进行预测:
fitted_Native <- tsTransformer_Native %>%
setup(loss = nn_mse_loss(),
optimizer = optim_adam,
metrics = list(luz_metric_mae())) %>%
set_hparams(input_size = ncol(df_clean) - 1,
d_model = 64, nhead = 4, seq_len = seq_len) %>%
set_opt_hparams(lr = 0.001) %>%
fit(train_dl, epochs = 20, valid_data = valid_dl,
callbacks = list(
luz_callback_early_stopping(patience = 5,
min_delta = 0.0,
monitor = "valid_loss")
))与 LSTM 相比,你会发现 Transformer 的训练有一个显著特点:快。即使层数更深,由于 GPU 可以并行计算所有时间步的 \(Q, K, V\),它对显卡的利用率远高于需要串行计算的 RNN。模型的拟合效果如下:
![]()
9.3.2 注意力在关注什么
前面我们讲了三种位置编码的机制,不同位置编码会对注意力权重有不同影响。我们看 embedding 和 ALiBi 两种方法的可视化结果:
embedding 做位置编码
抽取一个 batch 计算 四个头的平均注意力权重:
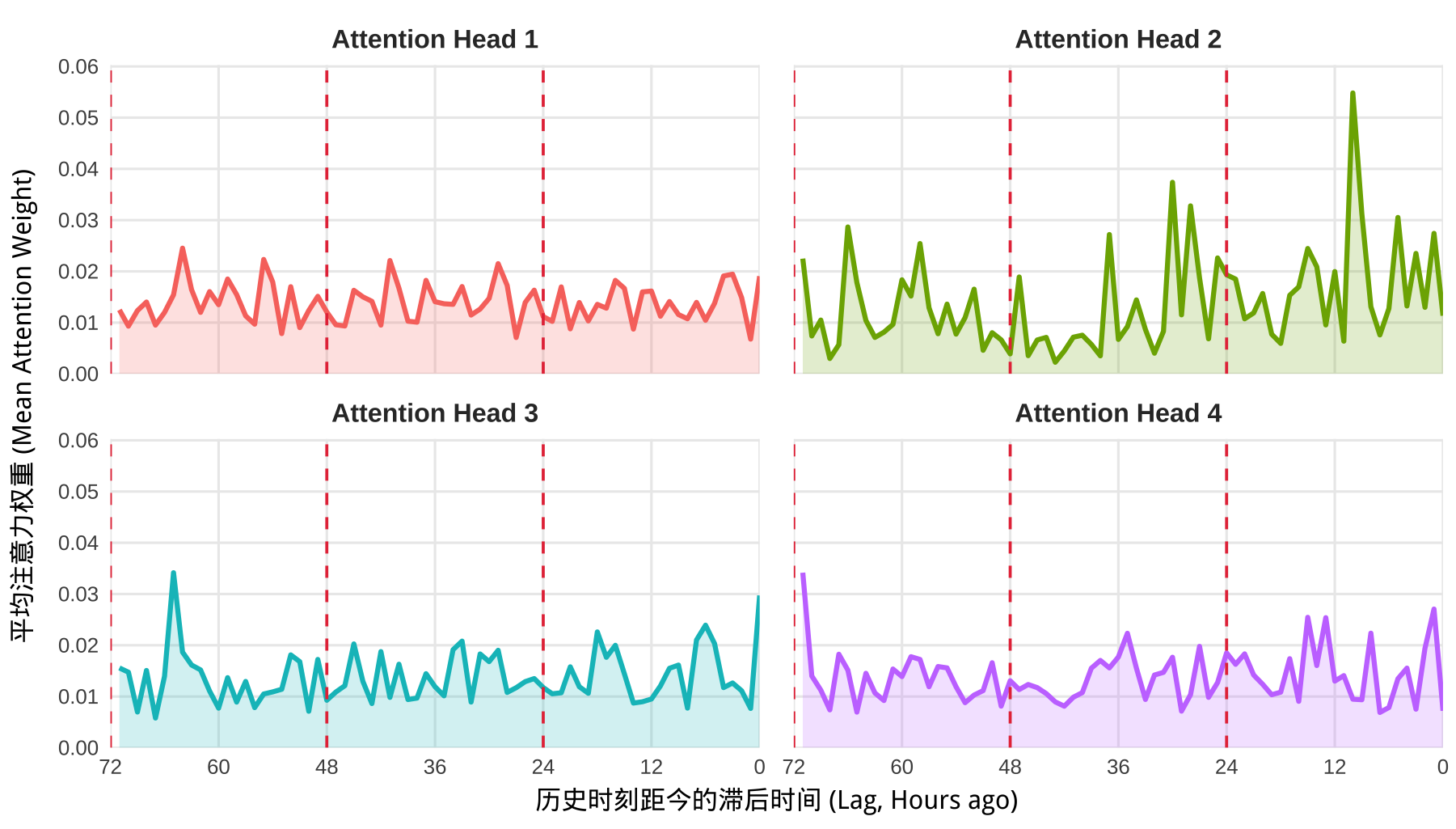
可以看到,因为是随机指定的 embedding 权重,因此 4 个头的注意力也是很分散的,没有直观的规律。
带有线性偏差的注意力 ALiBi 位置编码
ALiBi 的原理是在模型计算出 Attention 权重矩阵之后,直接根据两个时间步的距离进行“扣分(惩罚)”。距离越远,扣分越多。这样一来,位置信息就被完美地硬编码到了注意力权重的计算机制中。 如果有多个头,每个头被惩罚的策略不同的话,每个头会被强行要求学习不同的规则。
实现上我们采用“静态基建,动态通关”的方式。单独定义静态距离矩阵这个基建函数:
create_alibi_matrix <- function(nhead, max_len) {
# 1. 计算 nhead 个不同的惩罚斜率 (几何级数递减)
slopes <- 2^(-8 * (1:nhead) / nhead)
# 2. 使用 R 高阶函数 outer 计算绝对距离矩阵: |i - j|
dist_matrix <- abs(outer(1:max_len, 1:max_len, FUN = "-"))
# 3. 构建 3D 数组: [nhead, max_len, max_len]
alibi_base <- array(0, dim = c(nhead, max_len, max_len))
# 4. 遍历每个 Head,乘以对应的负斜率
for (h in 1:nhead) {
alibi_base[h, , ] <- dist_matrix * (-slopes[h])
}
return(alibi_base)
}手动生成一个 “2个 Head,最大长度为 3” 的微缩版矩阵来看看它的真面目。
> aperm(create_alibi_matrix(2, 3), c(2, 3, 1))
, , 1
[,1] [,2] [,3]
[1,] 0.0000 -0.0625 -0.1250
[2,] -0.0625 0.0000 -0.0625
[3,] -0.1250 -0.0625 0.0000
, , 2
[,1] [,2] [,3]
[1,] 0.00000000 -0.00390625 -0.00781250
[2,] -0.00390625 0.00000000 -0.00390625
[3,] -0.00781250 -0.00390625 0.00000000- 对于 head1,自己对自己惩罚是 0,但越远惩罚越重。
- 对于 head2,距离越远也会被惩罚,但惩罚的幅度要小很多。
接下来,我们组装完全体的 ALiBi Transformer 神经网络。
在模型的初始化(initialize)阶段,我们将调用上面写好的辅助函数,预先初始化一个 500x500 的绝对距离矩阵,并用 register_buffer 将其永久存在 GPU 显存里。而在每次前向传播时,我们只需付出 \(O(1)\) 的极低代价,从大矩阵中“切片”出当前序列所需的尺寸即可。
initialize = function(
input_size, d_model, nhead, seq_len, dropout = 0.1, max_length = 500) {
self$proj <- nn_linear(input_size, d_model)
self$nhead <- nhead
self$self_attn <- nn_multihead_attention(
embed_dim = d_model,
num_heads = nhead,
dropout = dropout,
batch_first = TRUE
)
self$norm1 <- nn_layer_norm(d_model)
self$norm2 <- nn_layer_norm(d_model)
self$ffn <- nn_sequential(
nn_linear(d_model, d_model * 4),
nn_relu(),
nn_dropout(dropout),
nn_linear(d_model * 4, d_model)
)
self$decoder <- nn_linear(d_model, 1)
# 调用外部 R 原生函数获取大矩阵,并注册为 GPU 缓存
alibi_array <- create_alibi_matrix(nhead, max_len = max_length)
alibi_tensor <- torch_tensor(alibi_array, dtype = torch_float())
self$register_buffer("alibi_base", alibi_tensor)
}这里使用的 R torch 的多头注意力函数 nn_multihead_attention,返回的 weights 用于可视化。接下来是 forward 部分:
forward = function(x) {
batch_size <- x$shape[1]
seq_length <- x$shape[2]
x_combined <- self$proj(x)
# 前向传播时直接进行 O(1) 切片,零计算开销
sliced_alibi <- self$alibi_base[, 1:seq_length, 1:seq_length]
final_alibi_mask <- sliced_alibi$
unsqueeze(1)$
expand(c(batch_size, self$nhead, seq_length, seq_length))$
reshape(c(batch_size * self$nhead, seq_length, seq_length))
# 将切片好的偏置矩阵注入注意力机制的 attn_mask
attn_out <- self$self_attn(
x_combined, x_combined, x_combined,
attn_mask = final_alibi_mask,
need_weights = TRUE,
avg_weights = FALSE
)
self$last_attn_weights <- attn_out[[2]]$detach()$cpu()
x_combined <- self$norm1(x_combined + attn_out[[1]])
ffn_out <- self$ffn(x_combined)
x_out <- self$norm2(x_combined + ffn_out)
last_step_features <- x_out[, seq_length, ]
pred <- self$decoder(last_step_features)
return(pred)
}你可能注意到了,我们将这个全是负数的惩罚矩阵传给了 nn_multihead_attention 的 attn_mask 参数。在 R torch 底层,attn_mask 不仅仅用来做“布尔遮挡”,如果传入浮点矩阵,底层代码会自动将其相加到 Attention 得分上。减去一个数值实现了 ALiBi 的距离削弱;试想一下,如果直接减去负无穷(\(-\infty\))会发生什么?这正是下一节我们要探索的生成式大模型中“因果掩码(Causal Mask)”的标准做法。
现在,让我们像之前一样抓取验证集的数据,提取 ALiBi 版本的 Attention 权重。你会看到一幅与传统绝对位置编码截然不同的情况:
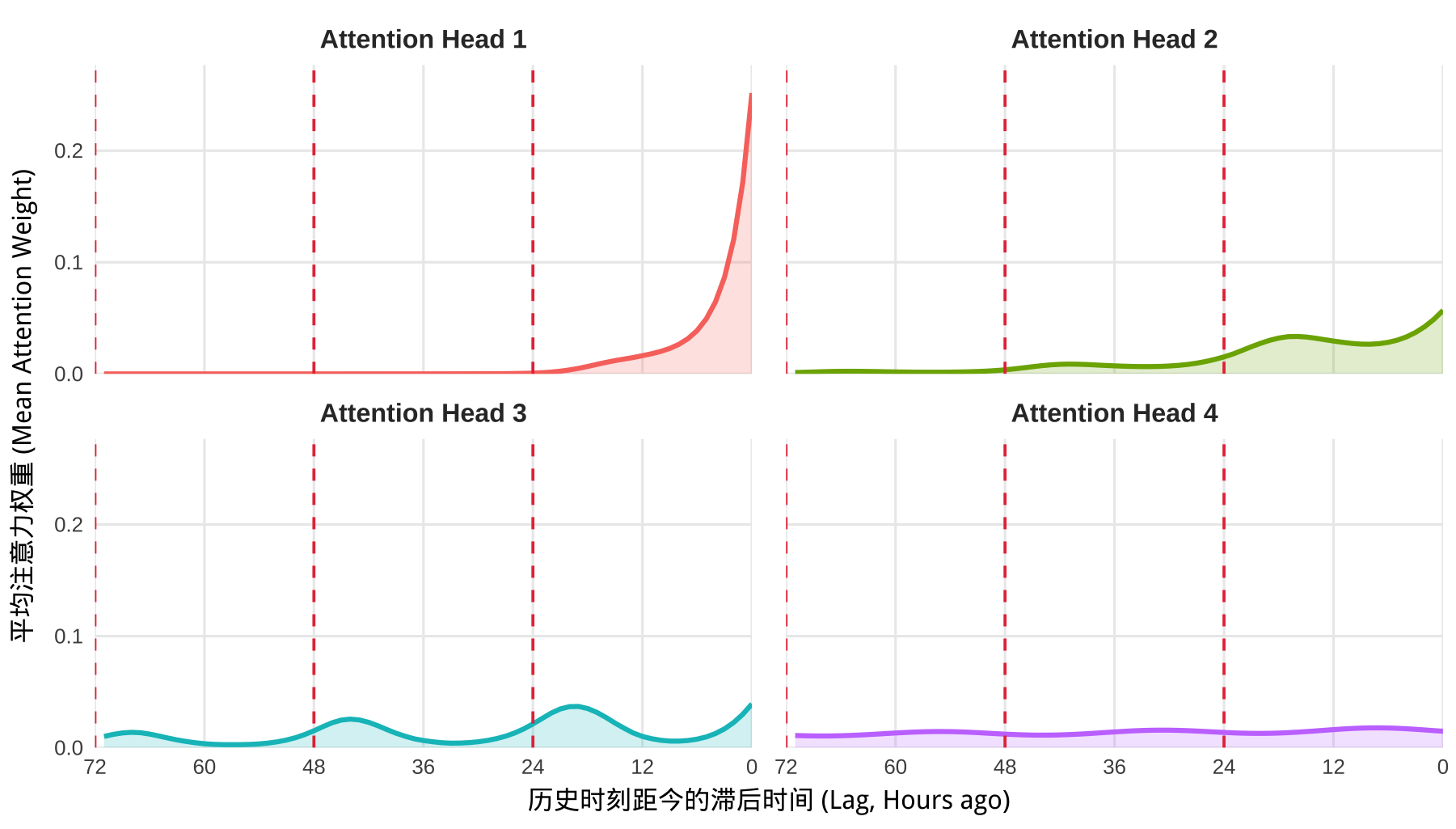
原本那种为了捕捉极值而产生的锯齿状尖峰消失了,取而代之的是极其平滑的衰减曲线,以及极其严密的多头斜率分化:
- Attention Head 1(红色) 被分配了最大的负斜率。它受到极其严厉的距离惩罚,过去 12 小时就迅速坠入冰点,强迫它只关注当下。
- Attention Head 4(紫色) 被分配了最小的负斜率。它受到的惩罚微乎其微,化身为一条几乎平缓的直线。它作为“全局观察者”,负责统揽过去 72 小时的整体基线。
- Attention Head 2(蓝色) 甚至还顺路学习到了一些周期性的规律。
模型不再死记硬背座次表,而是真正学会了“近期的事细节看,远期的事宏观看”的时间衰减物理法则。
零次学习外推(Zero-shot Extrapolation)
既然模型掌握了法则,而不是坐标位置,这就意味着它具备了突破训练边界的能力。
我们现在直接将输入数据的长度拉长一倍(144小时)。对于传统的 PE 模型,由于它初始化时只有 72 个空位,底层 C++ 代码此时会直接抛出索引越界错误。
但是,对于我们的 ALiBi 模型:
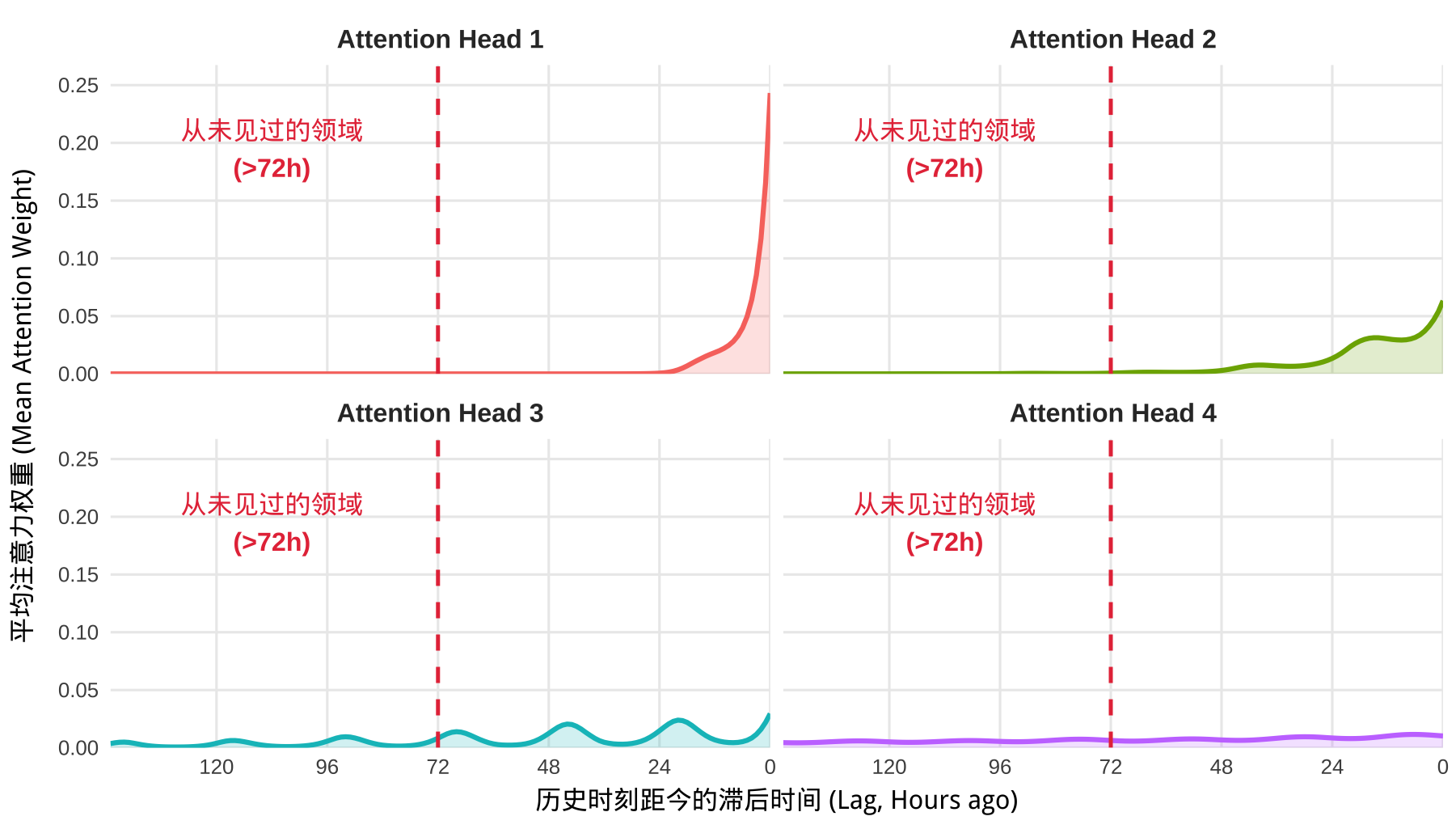
可以清晰地在红线左侧(从未见过的 >72h 领域)看到:
- Head 1 依旧死死盯住最近时刻,不越雷池一步。
- 而那些充当“全局观察者”的 Head(如 Head 3 和 Head 4),它们的注意力曲线极其顺滑地滑过了 72 小时的边界,以极其微弱但合理的权重,优雅地消化了这多出来的 3 天数据。
这也是为什么现在几乎所有能支持几十万上下文长度(Context Window)的大语言模型,底层的核心都在使用相对位置编码机制。
9.4 处理 Data frame
在本节中,我们将继续使用前面章节预测房价的 ames 数据集。为了提供一个公平的基准对比,本节的数据预处理流水线(Recipe)与此前构建 MLP(多层感知机)模型时保持完全一致。你会发现,在相同的数据输入下,Transformer 架构由于其独特的特征交互机制,能够使测试集上的 RMSE 再次出现显著下降。
处理 data frame 的核心挑战在于:如何将具有不同物理量纲的表格特征,在数学上合理地转化为 Transformer 可以处理的高维序列?
9.4.1 特征的序列化与独立投影
在自然语言处理中,输入序列的维度通常为 \(B \times S \times d_{model}\)(批次大小 \(\times\) 序列长度 \(\times\) 嵌入维度)。所有的词汇映射到同一个语义空间,因此可以使用共享权重的嵌入层。
但标准表格数据的维度为 \(B \times F\)(批次大小 \(\times\) 特征数量)。表格中的列是异质的(例如“房屋面积”与“建造年份”存在本质区别),使用共享权重的线性层进行投影并不合理。我们需要为每一个特征分配独立的权重矩阵和偏置项。
对于输入矩阵 \(X \in \mathbb{R}^{B \times F}\),我们首先在最后增加一个维度,将其转换为 \(B \times F \times 1\)。随后,定义特定的权重 \(W_{proj} \in \mathbb{R}^{F \times d_{model}}\) 和偏置 \(b_{proj} \in \mathbb{R}^{F \times d_{model}}\)。通过张量的广播机制(Broadcasting),独立地将每个标量特征投影到 \(d_{model}\) 维空间:
\[ T = X_{expanded} \odot W_{proj} + b_{proj} \]
其中 \(\odot\) 表示沿着特征维度的逐元素相乘。此时,表格数据成功转化为维度为 \(B \times F \times d_{model}\) 的序列特征张量(Tokens)。
#| filename: '9_transformer_ames.R'
# 独立特征分词器 (Independent Feature Tokenizer)
self$W_proj <- nn_parameter(torch_randn(num_features, d_model) * 0.02)
self$b_proj <- nn_parameter(torch_zeros(num_features, d_model))
# 前向传播:利用广播机制实现独立投影
x_expanded <- x$unsqueeze(-1)
tokens <- (x_expanded * self$W_proj) + self$b_proj为了让模型在无序的表格列中区分当前的特征身份,我们额外引入一个形状为 \(1 \times F \times d_{model}\) 的可学习参数矩阵 feature_emb,直接相加到 \(T\) 上,完成特征的身份编码。
# 特征身份编码
self$feature_emb <- nn_parameter(torch_randn(1, num_features, d_model) * 0.02)
# 前向传播中叠加
tokens <- tokens + self$feature_emb9.4.2 引入 [CLS] Token
经过自注意力层计算后,输出张量的维度依然是 \(B \times F \times d_{model}\)。在回归任务(如预测房价)中,我们需要将这个张量坍缩为一个标量。
如果采用平均池化(Mean Pooling)或最大池化沿着特征维度降维,会带来严重的信息丢失,并且在数学上等同于预设了所有特征对最终结果的初始贡献权重是相同的。
为了避免这种信息损耗,我们引入了 [CLS] (Classification) Token。这本质上是一个维度为 \(1 \times 1 \times d_{model}\) 的可学习向量,它在输入自注意力层之前被拼接到所有特征 Token 的最前端。
在多头注意力计算中,[CLS] Token 作为 Query 与所有物理特征(Key/Value)进行内积运算。由于它的权重是随反向传播动态更新的,它实际上充当了一个“全局信息汇聚枢纽”。在网络的前向传播中,[CLS] Token 会根据当前样本的特征分布,自适应地从不同的特征 Token 中提取并压缩最重要的信息。最终,我们只需截取序列的第一个位置进行标量映射。
# 定义并拼接 [CLS] Token
self$cls_token <- nn_parameter(torch_randn(1, 1, d_model) * 0.02)
cls_tokens <- self$cls_token$expand(c(batch_size, -1, -1))
seq_tokens <- torch_cat(list(cls_tokens, tokens), dim = 2)
# ... (经过注意力层计算) ...
# 提取 [CLS] 并输入预测头
cls_out <- seq_tokens[, 1, ]
cls_out <- self$norm_head(cls_out)
self$head(cls_out)在 R 的 torch 库中,原生的 nn_transformer_encoder_layer 函数封装了完整的 Transformer 块。但在这个工程实现中,我们选择放弃该高级封装,转而手动使用底层的 nn_multihead_attention 并配合 nn_layer_norm 与 nn_sequential 重构前馈网络。
这样做的核心目的是截获注意力权重矩阵以进行后续的可视化。nn_transformer_encoder_layer 默认不返回内部的注意力分布状态。通过显式调用 nn_multihead_attention 并设置 need_weights = TRUE,我们能够提取出维度为 \(B \times (F+1) \times (F+1)\) 的自注意力权重张量。
因为 [CLS] 是信息汇聚中心,该矩阵的第一行精确记录了在当前房价预测中,模型分配给各个物理特征的相对关注度。
# 显式使用 nn_multihead_attention 而非封装好的 encoder_layer
attn_out <- self$self_attn(
query = normed_seq,
key = normed_seq,
value = normed_seq,
need_weights = TRUE
)
# 留存注意力权重以供可视化分析
self$last_attn_weights <- attn_out[[2]]得益于特征间的动态注意力交互,该架构能够捕捉到 MLP 难以建立的复杂非线性关系。运行模型评估后,可以明显观察到测试集的 RMSE 指标相较于之前的 MLP 模型有显著的下降。
# 获取在测试集上的最终评估指标
eval_results <- transformer_fit |> evaluate(test_dl)
eval_results |> get_metrics()
## A tibble: 2 × 2
# metric value
# <chr> <dbl>
# 1 loss 0.0812
# 2 rmse 0.289 9.4.3 个体层面的特征归因
传统的线性回归或广义线性模型在训练完成后,其特征系数 \(\beta\) 是全局静态的,无论输入什么样的样本,各个特征的重要性乘数都是固定的。而 Transformer 的自注意力机制 \(A = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})\) 使得特征权重成为了关于输入数据的动态函数。这意味着模型能够根据具体样本的上下文,自适应地调整特征的关注度。通过提取测试集中“最贵豪宅”与“最便宜住房”对应的注意力权重矩阵,并截取 [CLS] 所在的行向量,我们生成了对比条形图。
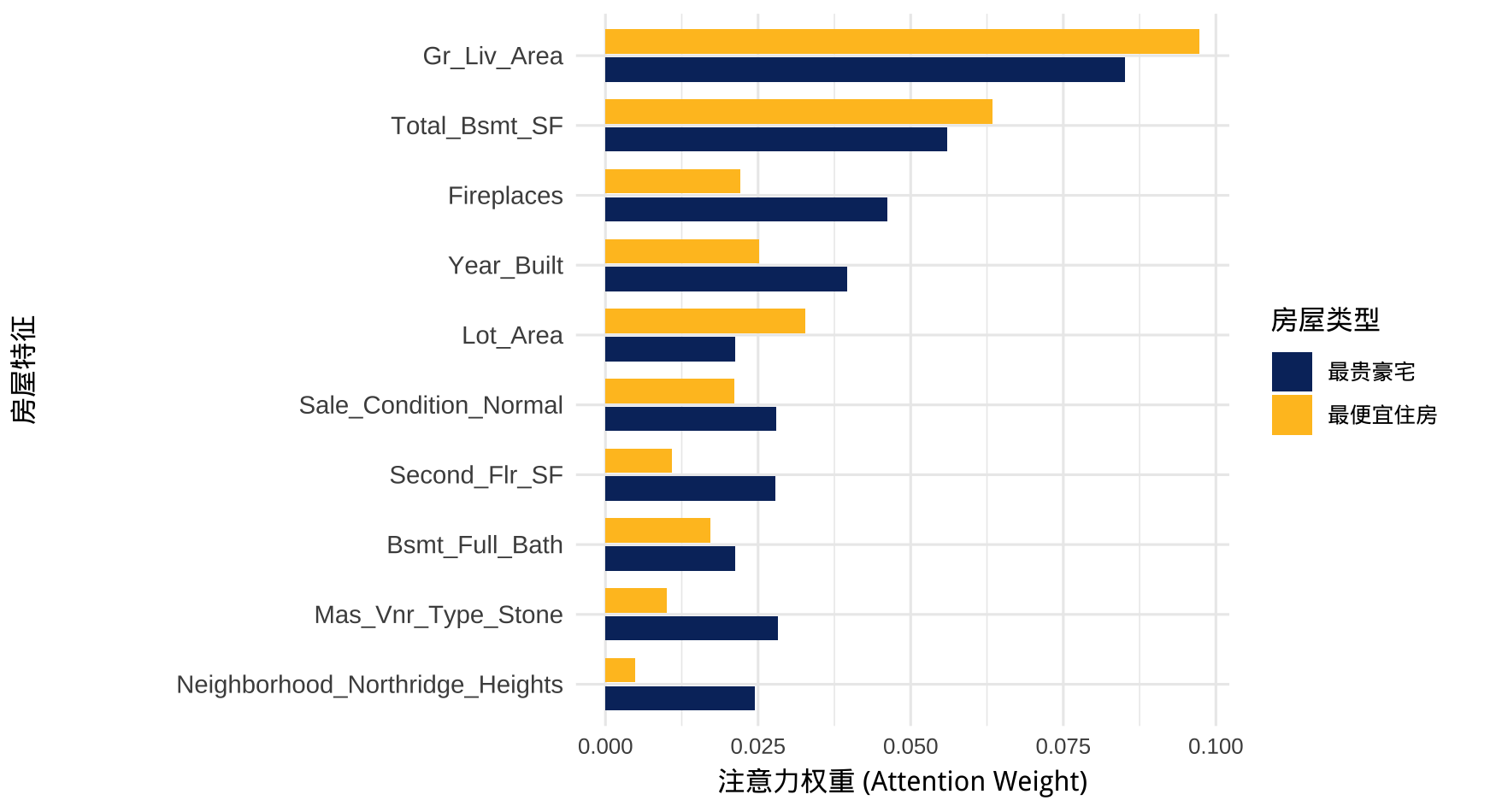
图中可以观察到以下数学与工程层面的现象:
- 无论房屋总价高低,Gr_Liv_Area(地上居住面积)和 Total_Bsmt_SF(地下室总面积)始终占据最高的注意力权重。这符合房地产定价的基础逻辑,即面积是决定价值的基准变量。
- 对于最贵豪宅,模型显著提升了对 Fireplaces(壁炉数量)、Year_Built(建造年份)、Mas_Vnr_Type_Stone(石材外墙覆盖层)以及特定街区 Neighborhood_Northridge_Heights 的注意力权重。这表明在面积基准之上,模型通过计算特征序列间的内积,成功识别出这些“改善型”特征向量对高房价的高阶贡献。
- 对于最便宜的住房,模型对上述豪华特征的关注度骤降,转而将相对更多的注意力分配给 Lot_Area(地块面积)等基础属性。
这种基于样本动态调整权重的能力,正是 Transformer 在表格数据上能够超越传统模型并降低 RMSE 的关键原因之一。
如果我们将视角从 [CLS] 单行扩展到包含物理特征的 \(K \times K\) 注意力矩阵子集,并以阈值过滤低权重连接,就可以将其映射为有向图(Directed Graph),从而直观地观察前向传播过程中的信息流向。
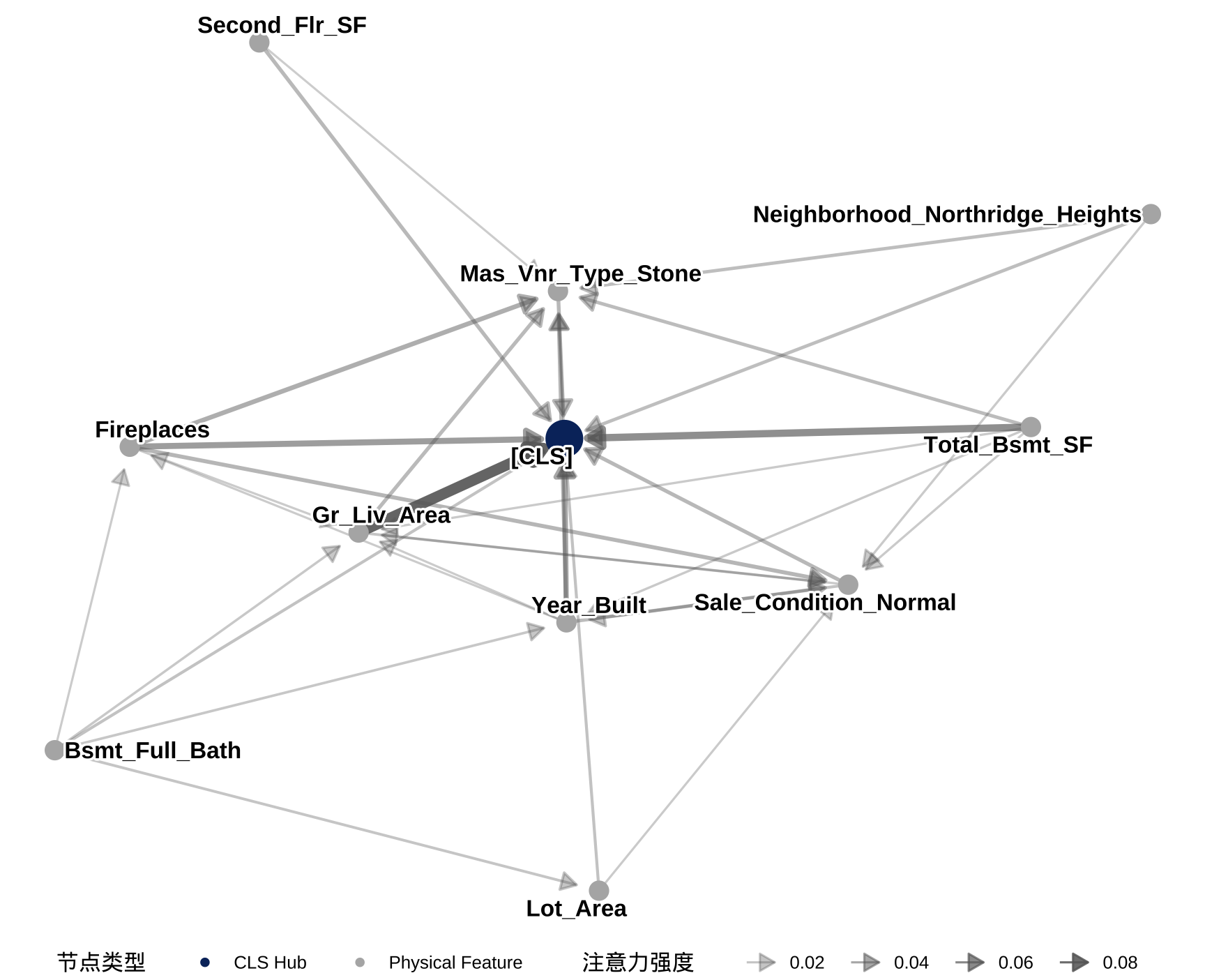
在网络拓扑图中,节点大小与连线粗细严格映射了矩阵元素 \(A_{i,j}\) 的数值大小。该图揭示了自注意力模块中的双重信息路由机制:
- 图中的中心深蓝色节点 [CLS] 扮演了信息汇聚枢纽的角色。最粗的箭头从 Gr_Liv_Area、Total_Bsmt_SF 和 Year_Built 指向 [CLS]。这在矩阵运算上表现为 [CLS] 的 Query 向量与这些核心特征的 Key 向量计算出了极高的点积,从而在当前层的输出中吸收了这些特征的表示。
- 除了指向 [CLS] 的连线,图的外围还存在物理特征之间的有向边。例如,Fireplaces 和 Year_Built 之间,以及 Mas_Vnr_Type_Stone 与其他节点之间存在信息传递。这说明在向 [CLS] 汇聚之前,物理特征 Token 之间已经通过各自的 Query 和 Key 进行了互相查询与上下文融合。这种机制使得 Transformer 无需人工进行特征工程(如构造交叉项 \(x_1 x_2\)),就能在隐藏层空间中隐式地捕捉变量间的共线性或复杂的非线性依赖关系。
transformer 技术是近些年非常重要的技术演进方向,各个方向都可以使用 Attention 机制重构模型,读者可以尝试使用 transformer 机制重构上一节 IMDB 电影评论情感分析的案例,实现代码可以参见 9_movie_sentiment.R
9.5 生成式 Transformer
本小节我们回到离散的文本生成(或语言建模) NLP 任务。虽然我们在第 8 章已经熟悉了文本数据的预处理和 nn_embedding 的使用,但在 Transformer 架构下,离散数据的处理逻辑有几个关键的工程变化。
9.5.1 数据预处理
这里有三个关键步骤:
- 读取 IMDB 的文本数据
load_imdb_data函数。 - 将文本数据进行清洗
TidyTextPipeline:初始化、encode、decode。 - 新增供模型训练的自定义 dataset 类
ImdbGenDataset。
前两步我们已经在第 8 章介绍过,这里不再赘述。
ImdbGenDataset 核心任务是将清洗后的文本数据转化为 GPT 模型所需的“自回归”(Autoregressive)训练格式。
简单来说,它完成了两个关键步骤:全量预处理(Pre-processing)和构建“下一个词预测”任务(Next Token Prediction Task)。
首先看初始化了什么?
#| filename: 9_Words_Suggestion.R
initialize = function(df, pipeline) {
self$max_l <- pipeline$max_len
target_len <- self$max_l + 1 # 输入+输出
pad <- pipeline$pad_idx
unk <- pipeline$unk_idx
vocab_map <- pipeline$token_to_idx
# 使用 map 批量处理,比在 getitem 里处理快得多
token_list <- map(df$text, function(txt) {
words <- unlist(strsplit(tolower(txt), "\\s+"))
idxs <- vocab_map[words]
idxs[is.na(idxs)] <- unk
full_seq <- c(vocab_map["<CLS>"], idxs)
len <- length(full_seq)
if (len >= target_len) {
full_seq[1:target_len]
} else {
c(full_seq, rep(pad, target_len - len))
}
})
flat_indices <- unlist(token_list)
n_samples <- length(token_list)
# 创建一个巨大的整数矩阵 [N, T]
self$data_tensor <- torch_tensor(flat_indices,
dtype = torch_long())$view(c(n_samples, target_len))
},此处我们将 <CLS> 视为序列的起始标记(Start of Sequence Token),功能类似于 GPT 中常用的 <s>。 假设模型最大上下文长度是 4。为了训练模型预测下一个词,假设有 6 个词的数据。例如:“I love R torch very much”。
- 输入 (x) 取前 4 个:“I”, “love”, “R”, “torch”
- 目标 (y) 取后 4 个:“love”, “R”, “torch”, “very”
这样模型就能学习到:输入 “I” -> 预测 “love”;输入 “I love” -> 预测 “R”。
最后把整个字符串集合直接转换成了 torch_tensor 并 reshape 成 [样本数, 序列长] 的矩阵。可以看一下它的样子:
train_ds$data_tensor[1:5,1:7]
# torch_tensor
# 3 2 310 9 6 1073 2
# 3 2 2 2 17 738 2
# 3 529 2 34 2 1959 2
# 3 14 9 706 4 91 2191
# 3 14 9 24 4 796 3756
[ CPULongType{5,7} ]第一个数字是 3,是 <CLS> (Start of sequence) 的索引。
这样在训练循环中调用 .getitem 时,只需要进行张量切片(Slicing),速度极快,且避免了 R 和 C++ 之间频繁的数据复制开销。
.getitem 阶段这是 DataLoader 在每次获取 mini-batch 时调用的函数。这里定义了 GPT 类模型的自监督学习机制。
.getitem = function(i) {
full_seq <- self$data_tensor[i, ]
list(
x = full_seq[1:self$max_l],
y = full_seq[2:(self$max_l + 1)]
)
}选择第 i 行,将其切分成输入 x 和目标 y。假设 max_len = 4,词汇表映射为:I=10, love=20, R=30, torch=40, <PAD>=0。 data_tensor 中存储的一行原始数据(长度为 5)是:[10, 20, 30, 40, 0]。当 .getitem 被调用时:
| 变量 | 索引 | 值 (Token ID) | 含义 |
|---|---|---|---|
| Ful Seq | 1:5 | [10,20,30,40,0] |
I love R torch <PAD> |
| x | 1:4 | [10,20,30,40] |
I love R torch |
| y | 2:5 | [20,30,40, 0] |
love R torch <PAD> |
模型看到 x 中的 10 (“I”),它需要预测 y 中的 20 (“love”)。 模型看到 x 中的 10, 20 (“I love”),它需要预测 y 中的 30 (“R”)。 这就是标准的因果语言建模(Causal Language Modeling) 任务。
9.5.2 模型架构
模型包含了两部分内容:
QuerySuggestGPT函数:实际是 decoder-only Transformersuggest_next函数:用于生成建议的文本序列
QuerySuggestGPT 实现了一个 GPT(Generative Pre-trained Transformer)的雏形。我们首先查看其初始化部分:
initialize = function(
vocab_size, d_model = 128,
nhead = 4, num_layers = 2,
max_len = 64, pad_idx = 1, dropout = 0.1) {
self$embedding <- nn_embedding(vocab_size, d_model,
padding_idx = pad_idx)
self$pos_embedding <- nn_embedding(max_len, d_model)
self$dropout <- nn_dropout(dropout)
self$register_buffer("pos_idx",
torch_arange(1, max_len, dtype = torch_long()))
# 预先创建因果 Mask
mask <- torch_full(c(max_len, max_len), -Inf)
mask <- torch_triu(mask, diagonal = 1)
self$register_buffer("causal_mask", mask)
encoder_layer <- nn_transformer_encoder_layer(
d_model = d_model,
nhead = nhead,
dim_feedforward = 256,
dropout = dropout,
batch_first = TRUE
)
self$transformer <- nn_transformer_encoder(
encoder_layer, num_layers =num_layers)
self$fc_out <- nn_linear(d_model, vocab_size)
}核心参数有如下内容:
vocab_size(词表大小): 5003 (pipeline 中的词汇量 + 3个特殊 token)d_model(嵌入维度/隐藏层维度): 256num_layers(层数): 2nhead(注意力头数): 4dim_feedforward(前馈网络维度): 硬编码 256max_len(序列最大长度): 32
在观察向前传播的结构:
forward = function(x) {
seq_len <- x$size(2)
pos <- self$pos_idx[1:seq_len]$unsqueeze(1)
mask <- self$causal_mask[1:seq_len, 1:seq_len]
emb <- self$embedding(x) + self$pos_embedding(pos)
emb <- self$dropout(emb)
out <- self$transformer(emb, mask = mask)
logits <- self$fc_out(out)
# 将 [Batch, Seq, Vocab] -> [Batch, Vocab, Seq]
logits <- logits$permute(c(1, 3, 2))
return(logits)
}1. 嵌入层 (Embedding Layer)
Token Embedding (
self$embedding)将每个词 ID 映射为长度为 256 的向量。参数规模 \(5003 \times 256 \approx 1,280,768\)。这是模型最大的参数来源之一。
Position Embedding (
self$pos_embedding)GPT 对位置信息极为敏感。这里使用的是可学习的位置编码(而非前文提到的固定正弦波编码),这意味着模型会自己学习“第一个词”和“第二个词”之间可能存在的不同。参数规模 \(32 \times 256 = 8192\)
2. Transformer 核心层 (Encoder Layer \(\times 2\))
代码中虽然使用了 nn_transformer_encoder_layer,但由于配置了因果掩码(causal_mask),它在数学上等价于 GPT 的 Decoder Block。这里我们堆叠了 2 层。
每一层内部包含两个子层:多头自注意力 (MHA) 和 前馈神经网络 (FFN)。
多头自注意力 (Multi-Head Self-Attention)
包含四个权重矩阵:\(W_Q\) (Query), \(W_K\) (Key), \(W_V\) (Value), \(W_O\) (Output)。输入向量被分别投影成 \(Q, K, V\),其权重矩阵被拆分为 4 个注意力头。每个头处理 \(256/4 = 64\) 维的特征,但在参数量计算上,这等同于一个更大的 \(d_{model}^2\) 矩阵。\(W_Q, W_K, W_V, W_O\) 各自是 \((D \times D) + D\) (偏置)。单层总数:\(4 \times (256^2 + 256) = 263168\)
前馈神经网络 (Feed-Forward Network, FFN)
正如上一节对
nn_transformer_encoder_layer结构的拆解所示,这是一个两层的全连接网络,用于对每个位置的特征进行非线性变换。其结构为FC(256) -> ReLU -> FC(256)。通常中间层会是前一层参数量的 4 倍,但这里硬编码为 256。因此,两层参数量为 \(2*(256^2 + 256) = 131584\)。层归一化 (LayerNorm)
通常在 MHA 前和 FFN 前(Pre-Norm)或后(Post-Norm)各有一个。每个 Norm 有两个可学习参数 \(\gamma\) (scale) 和 \(\beta\) (shift)。参数数量为 \(2 \times (2 \times D) = 4 \times 256 = 1,024\)
3. 输出层 (Final Head)
最后一步,将隐藏层向量映射回词汇表概率 self$fc_out。把维度从 256 还原回 5003,以便计算每个词的概率。参数数量: \((256 \times 5003) + 5003 (Bias) = 1,285,771\)
做一个简单表格汇总各层的功能和参数量:
| 组件 | 参数名称 | 形状 | 更新含义 |
|---|---|---|---|
| Embedding | Weight | [5003, 256] | 学习词的语义 |
| Attention | \(W^Q, W^K, W^V\) | [256, 256] ×3 | 学习如何“提问”和“索引” |
| Attention | \(W^O\) | [256, 256] | 学习如何融合多头的结果 |
| FFN | Linear1 Weight | [256, 256] | 提取特征/记忆 |
| FFN | Linear2 Weight | [256, 256] | 压缩特征 |
| LayerNorm | \(\gamma, \beta\) | [256] | 数据分布的缩放和平移 |
| Generator | Linear Weight | [256, 5003] | 计算最终每个词的概率 |
我们构建的模型呈现出“两头大,中间小”的参数分布特征:76% 的参数量 (2.56M / 3.36M) 其实都用于“查字典”(即输入和输出的词向量映射),真正负责逻辑推理的 Transformer 层只占了不到 24%1。
4. Mask
在训练时,我们是一次性把整句话喂给模型的。如果没有 Mask,模型预测第 3 个词时,能够“偷看”到第 4、5 个词的信息。这属于作弊。 Mask 的作用是遮住未来。位置 \(i\) 只能看到 \(0\) 到 \(i\) 的信息。
# 预先创建因果掩码 (Causal Mask)
mask <- torch_full(c(max_len, max_len), -Inf) # 先全填上负无穷
mask <- torch_triu(mask, diagonal = 1) # 保留上三角为负无穷,其余为 0
self$register_buffer("causal_mask", mask)假设序列为 R torch is awesome 的话,因果掩码的样子长这样:
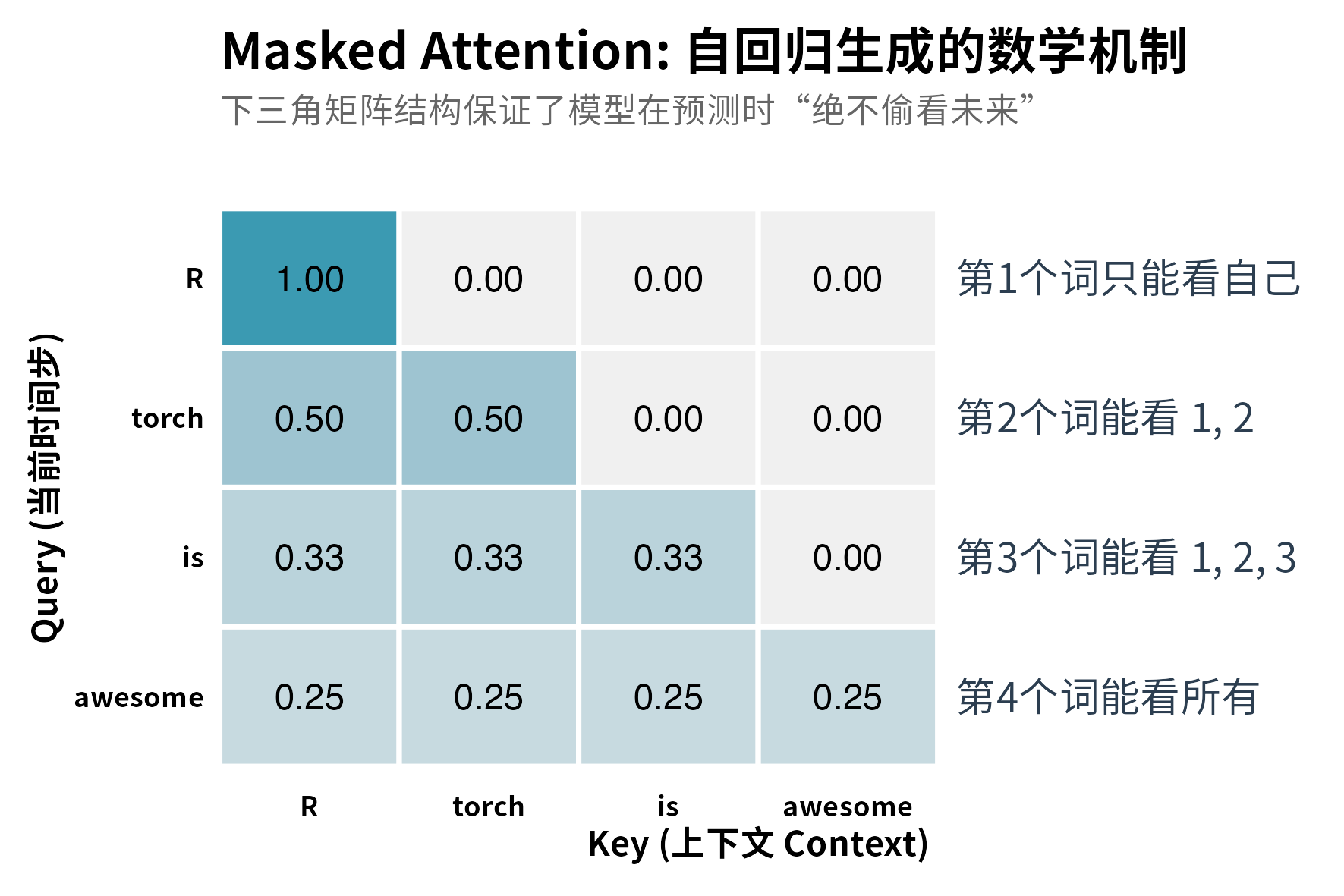
随着我们从上往下读(时间步推移),Query 能看到的 Key 的范围逐渐扩大(热力图中有颜色的格子变多)。这种逐行解锁的机制,就是 Transformer 生成文本时的真实过程。
最后通过 register_buffer 机制,保证 pos_idx 和 causal_mask 这些不是参数的张量,会随着模型移动到 GPU 或 CPU,避免报错。
9.5.3 训练过程
pad_int <- as.integer(pipeline$pad_idx)
fitted <- setup(
module = QuerySuggestGPT,
loss = nn_cross_entropy_loss(ignore_index = pad_int),
optimizer = optim_adamw # 使用 AdamW 通常效果更好
) %>%
set_hparams(
vocab_size = length(pipeline$idx_to_token),
d_model = 256,
nhead = 4,
num_layers = 2,
max_len = pipeline$max_len,
pad_idx = pad_int,
dropout = 0.1
) %>%
fit(
train_dl,
epochs = 25, # 演示用 5 epoch
accelerator = accelerator(), # 自动检测 CPU/MPS/CUDA
verbose = TRUE
)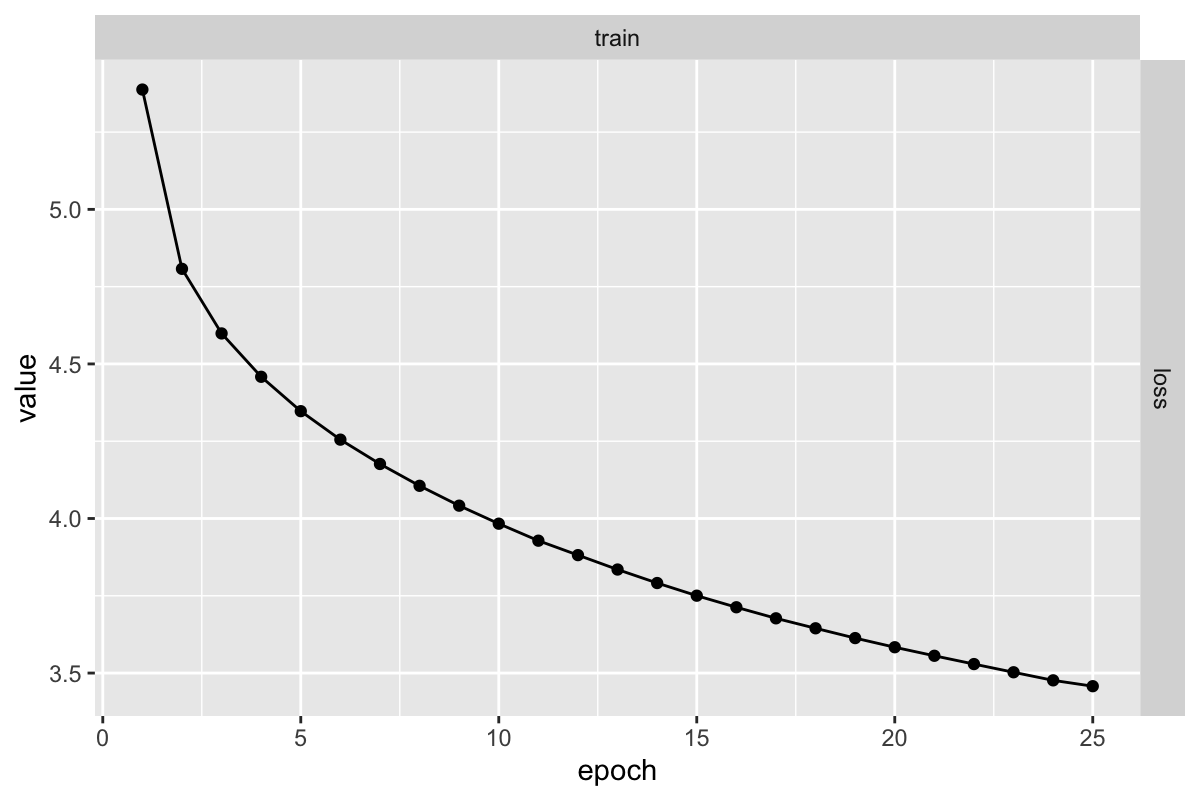
训练的过程中,我们使用了 AdamW 优化器,损失函数为交叉熵损失。训练 25 个 epoch 后,模型的损失在训练集上下降到 3.5 左右(没有配置测试集)。
交叉熵定义为
\[Loss = - \sum (y_i \cdot \ln(\hat{y}_i))\]
在初始化情况下,正确预测下一个单词的概率是随机的,为 1/5000。很容易计算此时的损失是 -ln(1/5000) = 8.602。当损失降低到 3.5 左右时,相当于在 exp(1)^3.5 (约 33)个 token 里面等概率地找下一个可能 token,范围已经缩的很小,模型的预测能力非常不错了。
9.5.4 推理生成
suggest_next 函数实现了下一个词预测。分为以下几个步骤:
- 初始化上下文 ctx,将输入文本转换为 token 索引。
- 通过滑动串口截断 ctx,切掉最前面的词,只保留最后 32 个词,保持序列长度不超过
max_len。 - 根据前面的所有词,预测“下一个词”的得分(logits)。
- 根据温度参数 temp 调整概率分布,实现不同的采样策略。
- 从调整后的概率分布中采样出下一个词的索引。
- 将采样出的词索引拼接到 ctx 后面,作为下一次循环的输入。
其核心是一个 for 循环,它不断将生成的词拼接到上下文 ctx 后面,并根据当前的 ctx 和概率预测下一个词。这种机制也被称为自回归生成(Autoregressive Generation)
# 初始化上下文 ctx
# pipeline$encode(text)
for (i in 1:max_new) {
# 1. 拿到当前的上下文 ctx
# ...
# 2. 模型预测
logits <- model(ctx_cond)
# 只取最后一个时间步的 logits!
# 因为 GPT 的逻辑是:根据前 n 个词,预测第 n+1 个词
last_logits <- logits[, logits$size(2), ]
# 3. 采样策略 (Temperature Sampling)
# Temp < 1.0 (冷): 概率分布变尖锐,更倾向于选概率最大的词
# 表现为保守、重复
# Temp > 1.0 (热): 概率分布变平坦,小概率词也有机会被选中
# 表现为胡言乱语,但有创造力
probs <- nnf_softmax(last_logits / temp, dim = -1)
next_idx <- torch_multinomial(probs, 1)
# 4. 拼接
# 把生成的词拼接到 ctx 后面,作为下一次循环的输入
ctx <- torch_cat(list(ctx, next_idx ...), dim = 2)
}为什么 Temp 能够影响创造力?主要原因是 Temp 的引入,改变了词的概率分布。标准的 Softmax 公式将 Logits (\(z_i\)) 转化为概率 (\(P_i\)):
\[ P_i = \frac{e^{z_i}}{\sum e^{z_j}} \]
带 Temp 的 Softmax 多了一步除法:
\[ P_i = \frac{e^{z_i / T}}{\sum e^{z_j / T}} \]
当 T 趋近无穷大时 \(e^0 = 1\),所有词的概率都趋近于均匀分布(大家都一样),这时候就是纯随机乱猜。当 T 小于 1 趋近 0 时 ,概率分布间的差距被指数级放大了,分布就会变得尖锐,导致最大的概率更接近为 1,这时候就是贪婪模式(Greedy Mode)。
可以查看不同 Temp 下的结果:
# 1. 贪婪模式 (最稳健,但可能重复)
suggest_next(final_model, pipeline, "the movie was", temp = 0.1)
# Input(Temp=0.1): 'the movie was'
# Suggest: so bad i didn't know about this movie but i was
# looking forward to seeing it as a kid and
# 2. 正常采样 (平衡)
suggest_next(final_model, pipeline, "i really liked", temp = 0.8)
# Input(Temp=0.8): 'i really liked'
# Suggest: this movie but it could have been a decent movie
# about joe don baker running man who is must say
# 3. 高创造性 (可能胡言乱语)
suggest_next(final_model, pipeline, "the plot is", temp = 1.2)
# Input(Temp=1.2): 'the plot is'
# Suggest: amazing but i believe it's really a brilliant
# performance of mario entire book but i guess the boys are ok这张树状图(Dendrogram)展示了 GPT 模型在进行下一个词预测(Next Word Prediction)时的动态决策路径。以 “This is one of” 为起始提示词(Prompt),图表从左至右展开了模型在接下来 4 个生成步骤(Steps)中的概率探索空间。它直观地反映了语言模型是如何基于上下文,在多种可能性中进行权衡和选择的。
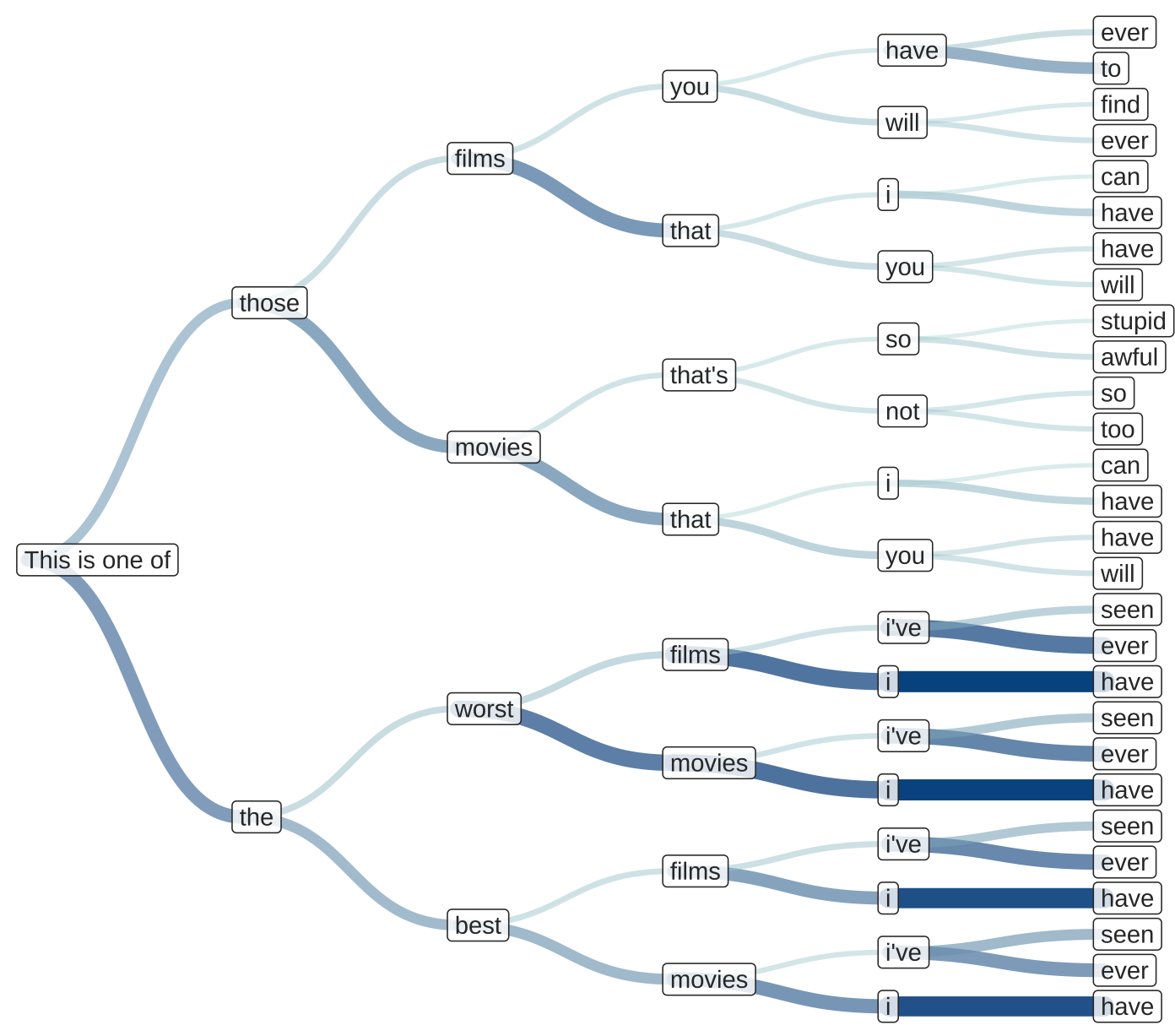
9.5.5 大语言模型
我们刚刚在 R 语言中实现的 QuerySuggestGPT,其核心正是 Decoder-only Transformer 架构与下一个词预测(Next Token Prediction)训练目标,这两者是构建 GPT-3、GPT-4、DeepSeek、Llama 等万亿参数大模型的底层基石。
可以把完整的大模型分为三个阶段,我们刚刚完成了第一阶段(且是迷你版)。
- 预训练 (Pre-training),我们所处的阶段。
- 指令微调 (SFT - Supervised Fine-Tuning)
- 人类反馈强化学习 (RLHF / DPO) —— 注入价值观
预训练 (Pre-training) 阶段的目标是让模型学会“说人话”,这是大模型训练最昂贵、最耗时的阶段。 我们的数据几千条 IMDB 影评,模型读了上文 “this movie”,学会根据概率预测下文 “is”。模型学会了语法、简单的搭配(比如 “highly recommended”),能补全句子。
GPT-4 的训练数据几乎覆盖了整个互联网的文本(万亿级 Token,包括维基百科、GitHub 代码、论文、Reddit 讨论等)。它同样是预测下一个词,但由于数据量极为庞大(量变引起质变),它不仅学会了语法,还“顺便”掌握了逻辑推理、编程、世界知识等能力。这种在模型规模和数据量达到一定阈值后突然展现出的高级能力,被称为“涌现”(Emergence)2。
| 配置项 | 本书轻量版 | 原版 Transformer | GPT-3 简化版 |
|---|---|---|---|
| vocab_size | 5,000 | 37,000 | 50,000 |
| d_model | 256 | 512 | 12,288 |
| n_layers | 2 | 6 | 96 |
| FFN维度 | 256 | 2048 | 49152 |
| Embedding参数量 | 1.28 M | 18.94 M | 617.5 M |
| 每层参数量 | 0.40 M | 3.15 M | 1,811.94 M |
| 总参数量 | 3.36 M | 37.82 M | 约 174.6B |
指令微调 (SFT - Supervised Fine-Tuning)阶段的目标是让模型学会“听指挥”,这是让 GPT 从“复读机”变成“ChatGPT”的关键一步。单纯的预训练模型只会续写。为了让它回答问题,OpenAI 雇佣了大量人类专家,编写了成千上万个高质量的 <问题, 正确答案> 对。拿着这些高质量数据,用同样的算法再接着训练。结果是,模型不再瞎编续写了,它学会了特定的模式:看见问号,就要回答;看见指令,就要执行。
人类反馈强化学习 (RLHF/DPO) 阶段目标是让模型学会“懂规矩”。即使经过了 SFT,模型有时仍可能产生不恰当或编造事实的回答。我们可以让模型对同一个问题生成几个不同的回答,再由人类进行打分(Ranking)。然后,使用强化学习(如 PPO 或 DPO),奖励模型生成高分回答,惩罚低分回答。这个阶段完成后,模型将在通用性、安全性和用户体验上得到显著提升。
9.6 遇见推荐系统
在深度学习的视角下,人类的语言和行为有着惊人的相似性,万物皆序列 (Everything is a Sequence)
- NLP 任务:给定一句话的前几个词(“我”,“想”,“吃”),预测下一个词(“火锅”)。
- 推荐任务:给定用户最近的点击历史(“手机”,“手机壳”,“数据线”),预测下一个点击(“充电宝”)。
本质上,基于会话的推荐系统 (Session-based RecSys) 就是一个特殊的“文本生成”任务,只是词表(Vocabulary)变大了而已。
| NLP 概念 | 推荐系统概念 | 解释 |
|---|---|---|
| Sentence | User Session | 用户在一段时间内的一连串交互行为。 |
| Token/Word | Item/Product | 被点击或购买的商品、电影或视频。 |
| Vocab Size | Itemset Size | 商城中商品的总数,需注意 Embedding 内存占用。 |
| [MASK] 标记 | UKN item | 在 BERT4Rec 中,随机掩盖用户历史中的某个商品求预测。 |
| Positional Encoding | sequence | 购买的先后顺序对预测至关重要(先买手机,后买壳)。 |
在这里简要介绍两种主流思路,对应书中的 Encoder 和 Decoder 知识:
GPT 风格,单向自回归,如 SASRec(Kang 和 McAuley 2018):
- 类似于第 9 章第 4 节的搜索补全。利用过去的行为预测未来。
- 适用于实时推荐,用户正在浏览,系统需要立即给出下一个建议。
- R torch 实现要点:使用
nn_transformer_decoder_layer,必须加上 Causal Mask(因果掩码)防止偷看未来。
BERT 风格,双向完形填空,如 BERT4Rec(Sun 等 2019):
- 类似于“完形填空”。把用户历史中的一个商品盖住(Mask),利用它前后的行为来猜测这个商品是什么。
- 适用于离线挖掘,理解用户的整体兴趣偏好,或数据清洗(补全缺失的交互记录)。
- R torch 实现要点:使用
nn_transformer_encoder_layer,不需要 Causal Mask,但需要随机替换 Input Tensor 中的 ID 为[MASK_ID]。
读者可以根据自己的时间,基于 MovieLens 或电商 Session 数据,根据用户过去浏览的 5 个商品,尝试预测第 6 个商品。看看预测结果是否符合预期。