6 工程化实验
“因为现实是唯一真实的东西。”
—— 《头号玩家》 (2018)
主角韦德大部分时间都生活在完美的虚拟世界“绿洲”(Oasis)里。那里想要什么有什么,但这只是虚幻。最终他明白,无论游戏多美好,人终究要回归粗糙、不完美但真实的现实世界。
6.1 构建高效数据管道
在 R 语言的传统统计建模,我们习惯于将所有数据读入内存(Global Environment),清洗成一个巨大的 data.frame,然后传入模型。这种“全量内存”模式在深度学习中是行不通的。
R torch 引入了一套基于 Dataset(数据集) 和 Dataloader(数据加载器) 的标准化范式,旨在实现数据的解耦与惰性加载。
6.1.1 R6 与 Dataset 封装
torch 包提供了一个核心生成器函数 dataset(),它基于 R 的 R6 面向对象系统构建。它的核心思想是将“数据是什么”与“怎么训练”分离开来。
一个标准的 Dataset 类必须实现三个核心方法(“三支柱”):
initialize:初始化构造函数。告诉类数据在哪里(文件路径),或者进行必要的参数配置。通常不在这里读取庞大的数据文件。.getitem:获取单样本。给定一个索引 \(i\)(index),返回第 \(i\) 个样本(特征 \(x\) 和标签 \(y\))。.length:返回数据集长度,告诉加载器一共有多少个样本。
让我们定义一个简单的内存数据集来熟悉这个结构:
library(torch)
# 定义一个简单的 Dataset 类
CustomDataset <- dataset(
name = "SimpleRegressionDataset",
# 1. 初始化:这里我们在内存中生成模拟数据,实际场景通常只存储路径
initialize = function(n_samples = 100, n_features = 5) {
self$x <- torch_randn(n_samples, n_features)
self$y <- torch_randn(n_samples, 1)
},
# 2. 获取单样本:返回一个 list
.getitem = function(index) {
list(x = self$x[index, ], y = self$y[index, ])
},
# 3. 长度:返回样本总数
.length = function() {
self$x$size(1)
}
)
# 实例化
train_ds <- CustomDataset(n_samples = 10, n_features = 3)
# 测试获取第 5 个样本
sample_5 <- train_ds[5]
print(sample_5).getitem 方法返回的通常是一个列表(List),其中包含特征和标签。这个列表的结构决定了后续模型接收数据的格式。
6.1.2 惰性加载
R 用户最常遇到的报错之一是 Error: cannot allocate vector of size...。深度学习中的图片、文本或时间序列数据通常无法一次性塞入 RAM。
惰性加载是指:在 initialize 阶段,我们只记录文件的路径或元数据,只有当程序真正调用 .getitem(index) 时,才从磁盘读取对应的那个文件。
为了演示,我们先在磁盘上创建一些模拟的 CSV 文件:
# 准备模拟数据环境
data_dir <- file.path(tempdir(), "simulated_data")
if (!dir.exists(data_dir)) dir.create(data_dir)
# 创建 50 个小的 CSV 文件,每个代表一个样本
for (i in 1:50) {
df <- data.frame(
feature1 = rnorm(1),
feature2 = rnorm(1),
label = sample(0:1, 1)
)
write.csv(df,
file.path(data_dir, paste0("sample_", i, ".csv")), row.names = FALSE)
}现在,我们构建一个支持惰性加载的 Dataset:
CSVFolderDataset <- dataset(
name = "CSVDataset",
initialize = function(folder_path) {
# 只扫描文件名,不读取内容!内存占用极低
self$files <- list.files(folder_path, full.names = TRUE, pattern = "\\.csv$")
},
.getitem = function(index) {
# 只有在需要时才读取文件
file_path <- self$files[index]
# 使用 R 原生函数读取
raw_data <- read.csv(file_path)
# 转换为 Tensor,注意数据类型
x <- torch_tensor(as.numeric(raw_data[1, 1:2]), dtype = torch_float())
y <- torch_tensor(as.numeric(raw_data[1, 3]), dtype = torch_float())
list(x = x, y = y)
},
.length = function() {
length(self$files)
}
)
# 即使只有 4GB 内存,也可以轻松处理 1TB 的文件集
disk_ds <- CSVFolderDataset(data_dir)
print(paste("Dataset size:", length(disk_ds)))这种模式是处理图像数据(读取 JPEG)和文本数据(读取语料库)的基础。
6.1.3 批次与编排
有了 Dataset,我们依然只能一个一个地获取数据。在训练神经网络时,我们需要:
- Batching:将 \(B\) 个样本打包成一个张量,利用矩阵运算加速。
- Shuffling:每个 Epoch 打乱数据顺序,防止模型记忆样本顺序。
- Parallelism:利用多核 CPU 预取数据。
dataloader() 就是负责这些工作的调度器。
# 创建加载器,batch_size = 4
train_dl <- dataloader(disk_ds, batch_size = 4, shuffle = TRUE)
# 模拟训练循环中的一次迭代
# dataloader 返回的是一个迭代器
iterator <- train_dl$.iter()
batch <- iterator$.next()
# 观察维度变化
# 单个样本 x 的形状是: [2]
# Batch x 的形状变成了: [4, 2] (4个样本,每个2个特征)
print(batch$x$shape)在实际训练中,我们会使用 coro::loop() 配合 dataloader 进行高效迭代:
coro::loop(for (batch in train_dl) {
# 这里是训练逻辑
# input <- batch$x
# target <- batch$y
# pred <- model(inputs)
# loss <- loss_fn(pred, targets)
# ...
})6.1.4 处理变长数据
默认情况下,dataloader 假设一个批次内的所有样本形状完全相同,并尝试使用 torch_stack 将它们堆叠起来。
但如果我们处理的是文本(句子长度不一)或不同尺寸的图像,默认行为就会报错。这时我们需要自定义 collate_fn。collate_fn 接收一个列表(包含 batch_size 个样本),你需要手动决定如何将它们拼在一起。
假设我们的 Dataset 返回长度不一的向量(为循环网络章节做铺垫):
VarLenDataset <- dataset(
name = "VarLen",
initialize = function() {},
.getitem = function(index) {
# 返回随机长度 1 到 5 的向量
len <- sample(1:5, 1)
torch_randn(len)
},
.length = function() 10
)
# 定义 collate 函数:进行填充 (Padding)
pad_collate <- function(batch) {
# batch 是一个 list,包含 dataloader 取出的 batch_size 个元素
# 这里的元素就是 Dataset .getitem 返回的 tensor
# 使用 pad_sequence 进行填充,使得 batch 内所有向量长度一致
# batch_first = TRUE 表示输出形状为 (Batch, Max_Len)
nn_utils_rnn_pad_sequence(batch, batch_first = TRUE, padding_value = 0)
}
vl_ds <- VarLenDataset()
# 传入自定义的 collate_fn
vl_dl <- dataloader(vl_ds, batch_size = 3, collate_fn = pad_collate)
iter <- vl_dl$.iter()
print(iter$.next())通过自定义 collate_fn,我们可以灵活地处理任何非结构化数据。
6.1.5 多进程加速
数据加载往往是训练的瓶颈。当 GPU 极速计算矩阵乘法时,CPU 还在缓慢地从硬盘读取 CSV 或解压 JPEG,导致 GPU 显存空闲(Volatile GPU-Util 低)。
dataloader(..., num_workers = N) 参数允许开启 \(N\) 个后台 R 进程并行读取数据。
\[ \text{Total Time} \approx \max(\text{GPU Compute Time}, \frac{\text{Data Loading Time}}{N}) \]
在 Windows 上,R 的并行机制(基于 PSOCK)开销较大,通常设为 0 或 2;在 Linux/macOS 上(基于 Fork),可以设置为 CPU 核心数的一半。
使用多进程时,确保 Dataset 的逻辑是线程安全的,且不要在 initialize 中建立数据库连接,而应在 .getitem 中建立。 另外,有大量图片文件加载的场景,因为调度之间的损耗,设置多线程加速可能还会拖慢整体的加载速度。
6.2 偏差和方差的博弈
深度学习的本质目标不是在已有的数据上做“记忆”,而是在未见的数据上做“推断”。为了衡量这种能力,我们需要一套严谨的评估体系,以及能够透视模型内部状态的诊断工具。
6.2.1 数据划分原则
在统计学习中,我们通常假设数据是独立同分布(i.i.d.)的。为了模拟模型上线后的真实表现,我们必须人为地制造“未知”。最基础的原则是将数据集划分为三个互斥的部分:
- 训练集 (Training Set):用于计算梯度和更新参数。这是模型“学习”的材料。
- 验证集 (Validation Set):用于调整超参数(如学习率、网络层数、Batch Size)和进行模型选择。这是模型的“模拟考”。
- 测试集 (Test Set):仅在所有开发工作结束后使用一次,用于评估模型的最终性能。这是“期末考”。
如果你根据测试集的表现来调整模型结构,那么测试集实际上就变成了训练过程的一部分,其评估结果将不再具有统计效力。
这个是数据集划分原则,有些实际情况可能不太一样:
- 模型训练是“一步到位”的(closed-form 或固定迭代次数)比如线性回归、朴素贝叶斯、SVM(非核)、决策树,可以不需要验证集。
- 模型训练是“逐步优化”的(iterative optimization),比如 XGBoost、LightGBM、深度学习,需要验证集来监控训练过程。
出于重点和认知负担的考虑,本章节的案例不做复杂设计,默认验证集等同于测试集。
在 R 生态中,可以使用随机抽样 sample 这类函数做手动切片。但更规范的是使用 tidymodels 生态的 rsample 包来优雅地管理这种划分。第 4 章我们有简要提及如何切分训练集和测试集,如果严格执行标准划分准则的话,需要这样操作:
# 1. 先切 test
split1 <- initial_split(iris, prop = 0.8, strata = 'Species')
train_valid <- training(split1)
test <- testing(split1)
# 2. 再切 valid
split2 <- initial_split(train_valid, prop = 0.75, strata = 'Species')
train <- training(split2)
valid <- testing(split2)设置分层抽样(非随机抽样),保证分布的一致性,避免某类在 valid/test 里太少。分层变量使用 strata = target 来指定。
strata 参数既可以用于分类变量,也可以用于数值变量。数值型变量会被自动分箱(通常为 5 个区间),再在每个区间内按比例抽样,从而保证训练集、验证集和测试集在该变量上的分布尽可能一致。由于分箱本身具有一定的任意性,因此对数值变量进行分层抽样需要谨慎使用,通常只在希望保持目标变量分布一致的场景下采用。
6.2.2 偏差-方差权衡
为了直观理解偏差与方差,我们构造一个经典的非线性回归任务:目标函数为 \(y = \sin(2\pi x)\),并加入高斯噪声。我们将分别使用线性模型(过于简单)和高阶多项式模型(过于复杂)来拟合它。
generate_data <- function(n = 100) {
x <- torch_rand(n, 1)
y <- torch_sin(2 * pi * x) + 0.1 * torch_randn(n, 1)
list(x = x, y = y)
}
train_ds <- generate_data(20) # 小样本更容易观察过拟合
valid_ds <- generate_data(100)先构建一个能够动态调整多项式次数的模型。这里我们利用 torch_cat 手动构造多项式特征 \(x^1, x^2, \dots, x^n\)。
PolyNet <- nn_module(
"PolyNet",
initialize = function(degree) {
self$degree <- degree
self$linear <- nn_linear(in_features = degree, out_features = 1)
},
forward = function(x) {
# 生成多项式特征矩阵
x_poly <- torch_cat(lapply(1:self$degree, function(d) x^d), dim = 2)
self$linear(x_poly)
}
)接着,我们分别训练一个 degree=1 (线性) 的模型和一个 degree=15 (高阶) 的模型,并记录每个 Epoch 的训练 Loss 和验证 Loss。
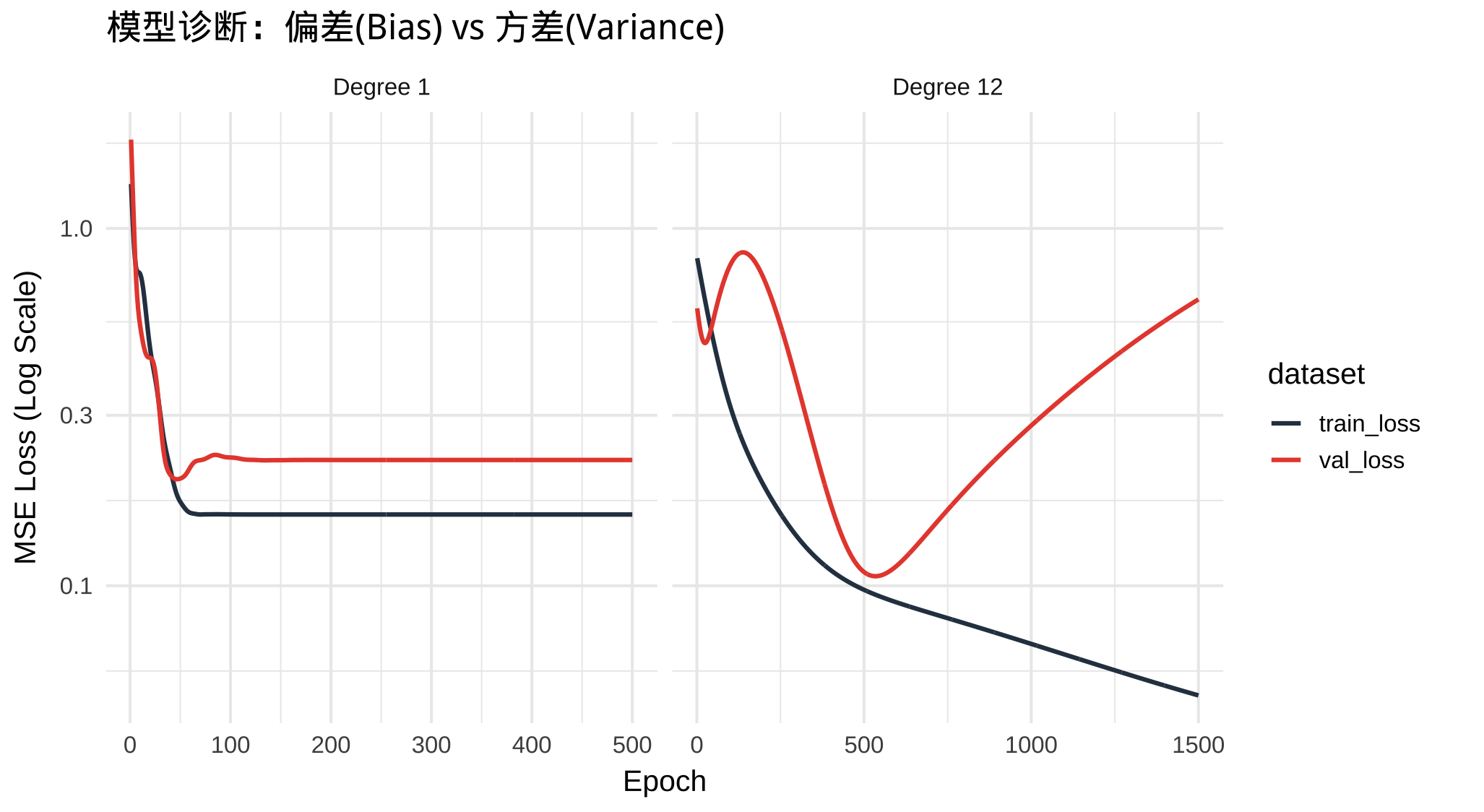
当 degree=1 时:
- 欠拟合 (Underfitting) ,模型试图用一条直线去拟合正弦波,效果不可能好。
- Training Loss 很高且无法继续下降;Validation Loss 也很高。
当 degree=15 且训练数据量较少时:
- 过拟合 (Overfitting) ,模型有足够的能力“死记硬背”每一个训练样本。
- Training Loss 持续下降,甚至接近于 0;但 Validation Loss 在下降一段时间后,开始反向飙升。
上述实验揭示了机器学习中著名的误差分解公式。对于一个给定的输入 \(x\),模型的期望预测误差可以分解为:
\[ E[(y - \hat{f}(x))^2] = \text{Bias}[\hat{f}(x)]^2 + \text{Var}[\hat{f}(x)] + \sigma^2 \]
- 偏差 (Bias):来源于错误的模型假设(如用直线拟合曲线)。高偏差意味着模型“太笨”。
- 方差 (Variance):来源于模型对训练数据微小波动的敏感性。高方差意味着模型“太敏感”。
- 不可约误差 (\(\sigma^2\)):数据本身的噪声,任何模型都无法消除。
在工程实践中,我们很少直接计算数学上的偏差和方差,而是通过 Loss 曲线的行为来定性判断:
| 现象 | 诊断 | 工程对策 |
|---|---|---|
| Train Loss 高, Val Loss 高 | 欠拟合 (高偏差) | 1. 增加模型复杂度(加深网络、增加神经元) 2. 减少正则化 3. 增加特征工程 |
| Train Loss 低, Val Loss 高 | 过拟合 (高方差) | 1. 收集更多数据(最有效但最贵) 2. 正则化(Weight Decay, Dropout) 3. 降低模型复杂度 4. 早停法 (Early Stopping) |
| Train Loss 低, Val Loss 低 | 理想状态 | 保持现状,尝试微调或部署 |
在深度学习时代,我们通常倾向于:先构建一个稍微过拟合的模型(保证偏差足够低,能学会数据),然后通过正则化手段来控制方差(压低验证误差)。
6.3 正则化策略
前面我们见识了“过拟合”的可怕:模型在训练集上表现神勇,但在验证集上却一塌糊涂。要解决这个问题,我们需要引入正则化 (Regularization)。正则化的本质是给模型人为地制造困难,限制其“胡乱记忆”的能力,强迫它学习数据背后真正的规律。
本节我们将探讨三种最核心的正则化手段:权重衰减 (Weight Decay)、Dropout (随机失活) 和 Batch Normalization (批归一化),并演示如何在 luz 框架中优雅地组合使用它们。
6.3.1 权重衰减
权重衰减 (Weight Decay / L2 Regularization/ ridge penalty) 几乎是最古老也最常用的正则化方法。在损失上增加了一项:
\[ L_{total} = L_{original} + \frac{\lambda}{2} \sum_{j} w_j^2 \]
公式符号说明:
- \(L_{original}\): 原始的损失函数(例如 MSE 或 Cross Entropy)。
- \(\lambda\): 正则化强度超参数。在
Luz中设置的weight_decay参数。 - \(w\): 神经网络中的权重参数(一般不对偏置项 \(b\) 进行正则化)。
当我们对 \(L_{total}\) 求导并使用梯度下降更新权重时,你会看到“衰减”是如何发生的。权重的梯度:
\[ \frac{\partial L_{total}}{\partial w} = \frac{\partial L_{original}}{\partial w} + \lambda w \]
参数更新规则 (其中 \(\eta\) 是学习率):
\[ w_{new} = w - \eta \left( \frac{\partial L_{original}}{\partial w} + \lambda w \right) \]
整理后:
\[ w_{new} = \underbrace{(1 - \eta \lambda) w}_{\text{权重衰减}} - \eta \frac{\partial L_{original}}{\partial w} \]
也就是说每次更新时,权重 \(w\) 会先乘以一个小于 1 的系数 \((1 - \eta \lambda)\) 进行收缩(衰减),然后再沿着原始梯度的方向移动。这就是它被称为 Weight Decay 的原因。
无论回归还是深度学习,从贝叶斯统计的角度看,L2 正则化都等价于为参数 \(w\) 引入了一个均值为 0 的高斯分布(正态分布)先验。
- 我们假设权重 \(w\) 不应该太大,大部分应该聚集在 0 附近。
- \(\lambda\) 越大,对应的高斯分布方差越小,对大权重的惩罚越重。
R 用户初学 Torch 时经常找不到 L2 Regularization,是因为权重衰减放到了优化器 (Optimizer) 里。
optimizer <- optim_adam(
model$parameters,
lr = 1e-3,
weight_decay = 1e-5
)weight_decay 越大,正则越强,参数被压得更小。一般取值范围:1e-5 到 1e-3。
6.3.2 Dropout
Dropout (随机失活) 是深度学习中最天才的正则化发明之一。在每次训练迭代中,随机地将一部分神经元的输出置为 0(比如丢弃 50%)。这强迫网络不能依赖任何某一个特定的神经元(因为它随时可能罢工)。网络必须学会利用多个神经元的组合特征来做判断。这相当于在训练过程中训练了成千上万个不同的“子网络”并进行了集成(Ensemble)1。
利用 nn_dropout 函数就可以加进去:
self$net <- nn_sequential(
nn_linear(100, 50),
nn_relu(),
# p = 0.5 表示有 50% 的概率丢弃神经元
nn_dropout(p = 0.5),
nn_linear(50, 1)
)注意:Dropout 只能在训练时开启,预测时必须关闭。
- 调用
model$train():开启 Dropout。 - 调用
model$eval():关闭 Dropout,且 Torch 会自动缩放权重以保持期望值一致。
6.3.3 批归一化
在数据预处理阶段,我们通常会对输入数据进行标准化(Center & Scale),使其符合 \(\mu=0, \sigma=1\) 的分布。这能让模型在训练初期走得更稳。
然而,随着训练的进行,网络参数不断更新。对于深层网络来说,第 2 层的输入分布完全取决于第 1 层的输出。如果第 1 层的参数变了,第 2 层的输入分布就会发生剧烈抖动。每一层都在试图适应上一层不断变化的分布,这种现象被称为内部协变量偏移 (Internal Covariate Shift)。
批归一化 (Batch Normalization) 的作用就是强行将每一层的输入拉回到一个标准的正态分布,把这个偏移的趋势固定住。
Batch Normalization 的计算可以分为两步:
第一步,标准化 (Normalization):利用当前 Batch 的均值 \(\mu_{\mathcal{B}}\) 和方差 \(\sigma_{\mathcal{B}}^2\),将输入 \(x\) 拉回到标准正态分布。为了数值稳定性,我们在分母中加入了一个极小的常数 \(\epsilon\)(通常为 \(1e-5\)):
\[ \hat{x} = \frac{x - \mu_{\mathcal{B}}}{\sqrt{\sigma_{\mathcal{B}}^2 + \epsilon}} \]
此时,\(\hat{x}\) 的均值为 0,方差为 1。
第二步,仿射变换 (Affine Transformation):为了防止标准化破坏了特征原本的表达能力(比如某些特征可能需要非零均值才能激活后续的 ReLU),BN 引入了两个可学习的参数:缩放因子 \(\gamma\) 和 平移因子 \(\beta\)。
\[ x_{out} = \gamma \cdot \hat{x} + \beta \]
- \(x_{out}\):这是 BN 层最终处理完传给下一层的输出。
- \(\gamma\) :对应为 weight 参数。
- \(\beta\) :对应为 bias 参数。
怎么理解这两个可学习的参数呢?我们可以做一个很简单的实验:
x <- torch_randn( 1000, 1) * 2 + 10,均值为 10,标准差为 2 的 1000 个数- 输出 y 等于这个输入 x
- 构建一个 net 结构,只包含一个批归一化层
- 求解批归一化层的 \(\gamma\) 和 \(\beta\) 参数
因为 x 整体被强行 Normalization 了,所以均值为 0,标准差为 1。 但又要求 y = x,所以被 Normalization 的 x 会被强行“仿射变换”回去,也就是放大 \(\gamma=2\) 倍,再做 \(\beta=10\) 的平移。
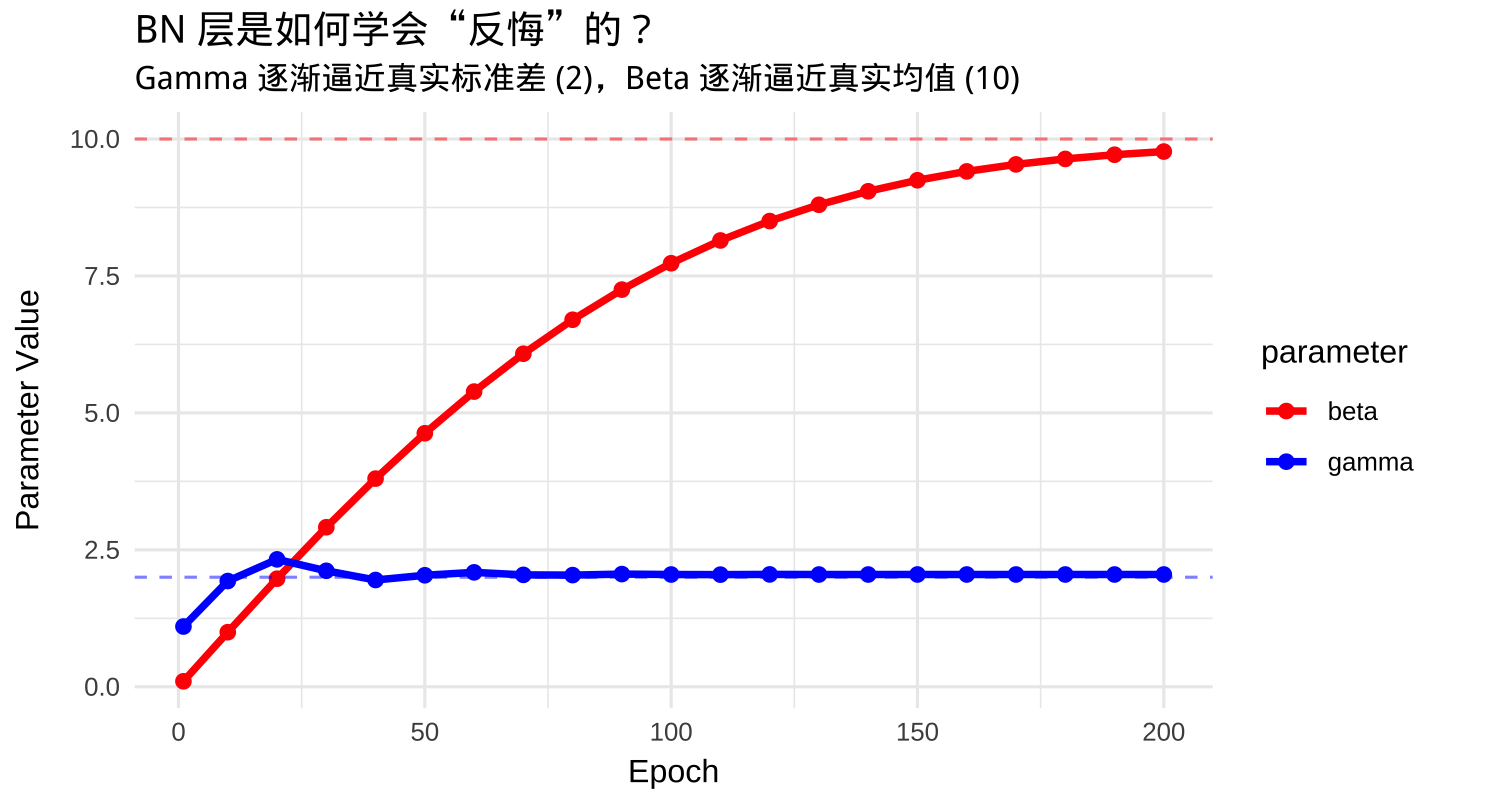
通过上述机制,BN 带来了两个立竿见影的效果:
- 平滑损失地形:它让损失函数曲面变得更加平滑,不再坑坑洼洼。
- 允许更大的学习率:优化器可以放心大胆地大步往前走,而不用担心梯度爆炸或消失。
正如我们在下图中看到的(蓝色线 vs 红色线),加入 BN 后,Loss 就像从悬崖跳水一样迅速下降,而没有 BN 的模型则在初期挣扎了很久。
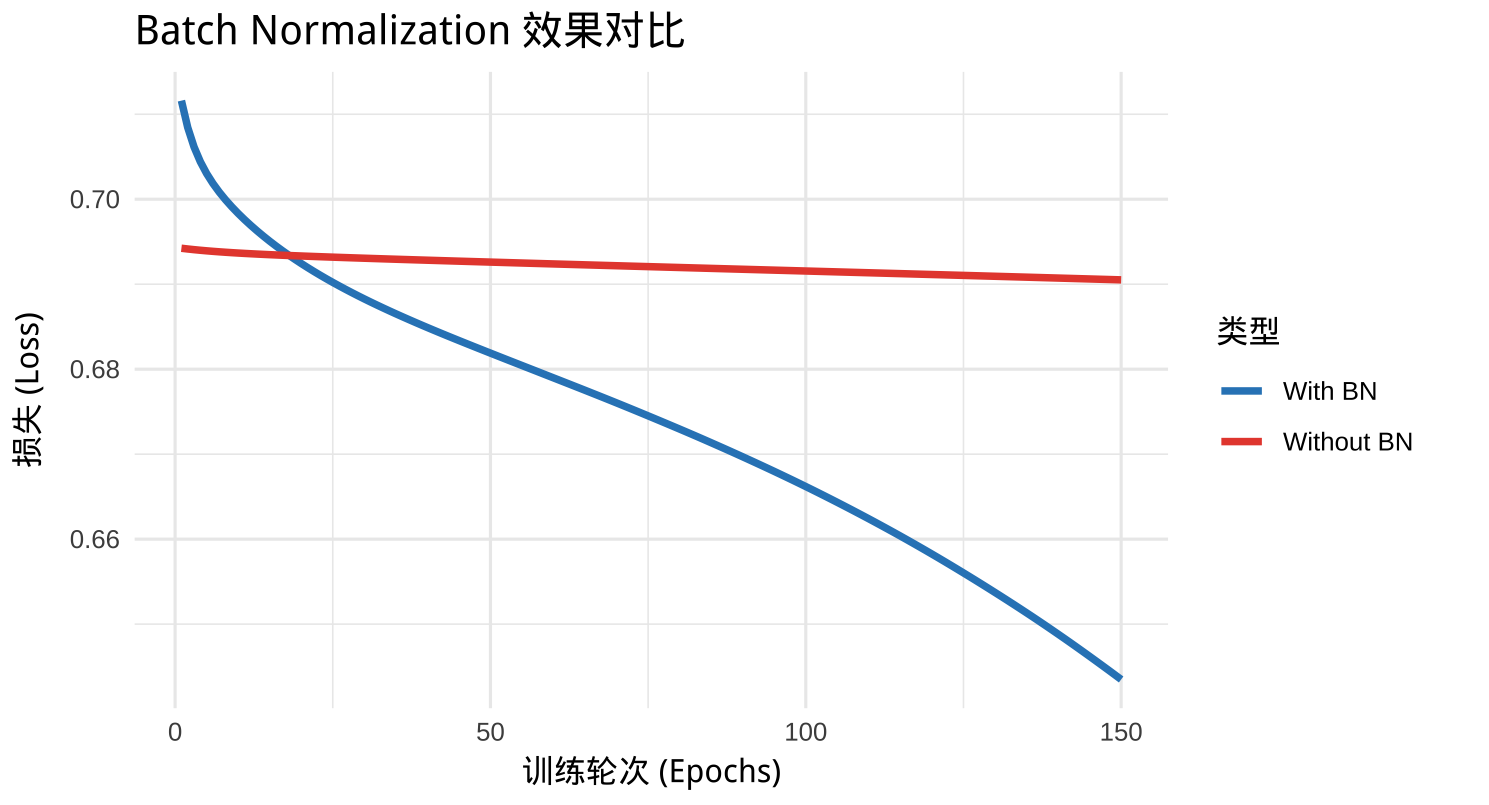
由于 \(\mu_{\mathcal{B}}\) 和 \(\sigma_{\mathcal{B}}\) 是基于当前 Batch 计算的(是真实分布的有噪声估计),这给网络引入了随机性。这种随机噪声迫使模型不过分依赖某个特定的神经元,从而在一定程度上起到了类似 Dropout 的正则化效果,防止过拟合。
在全连接网络(MLP)中,我们使用 nn_batch_norm1d。
注意:虽然名字里带有 1d,但它不仅适用于 1D 卷积,也标准用于处理形状为 \((N, \text{Features})\) 的全连接层输出。
通常建议将 BN 层放在线性层之后、激活函数之前(虽然放在激活函数后有时也有效,但经典论文推荐前者):
net <- nn_sequential(
nn_linear(100, 50),
# 插入 BN 层,参数为特征数量 (50)
# 此时数据的形状是 (Batch, 50)
nn_batch_norm1d(num_features = 50),
nn_relu(), # 激活函数
nn_dropout(0.5),
nn_linear(50, 1)
)预告:当我们在下一章处理图像数据(2D 结构)时,BN 的计算方式会有细微但重要的变化,届时我们将介绍 nn_batch_norm2d。
6.4 拥抱 luz 框架
还记得你依旧“手写循环”的痛处吗?
- 不仅要管理
optimizer$zero_grad()和backward(),还要手动计算每个 epoch 的平均 Loss。 - 忘记把数据
$to(device)移动到 GPU,忘记在验证阶段调用model$eval(),每个问题发生都会带来无穷无尽的 debug。 - 不停的在
model$train()和model$eval()中切换。 - 想要实现 Early Stopping(早停),想保存验证集表现最好的模型,想动态调整学习率,这些都需要你自己写大量的辅助代码。
我们希望能像 dplyr 处理数据一样,将前面提到的优化方法,都能够优雅地放进训练流程。
6.4.1 什么是 luz?
luz(Falbel 2025) 是一个用于 torch 的高级 API,它的名字来源于西班牙语的“光(Light)”,寓意着照亮深度学习的黑盒。它将训练过程分解成一系列可重用的代码片段,减少了使用 torch 训练模型所需的冗长代码,有效规避了在调用
zero_grad() - backward() - step()
序列时产生的错误倾向,并简化了在 CPU 和 GPU 之间迁移数据和模型的过程。luz 的设计非常灵活,它提供了一个分层 API,无论需要对训练循环进行何种级别的控制,它都能满足需求。 它就像 dplyr 之于数据处理,ggplot2 之于绘图,能让你用极其优雅的“管道”语法,完成标准化的深度学习训练。
luz 的设计灵感来源于其他一些高级的深度学习框架,例如:FastAI、Keras、PyTorch Lightning、HuggingFace Accelerate 等,包括 R 的 tidymodels。
6.4.2 优雅的工作流
细心的读者可能已经发现,在第四章 ames 房价预测的手写循环中,我们虽然划分了测试(验证)集,但在训练过程中我们并没有实时监控它。我们是像“盲跑”一样跑完了 1000 个 Epoch,最后才看了一眼测试(验证)集分数。
按照本章第二节的理论讨论,我们需要同时监测测试(验证)集的 loss 变化,来判断模型拟合状态。
基于这个考虑,我们对原有建模逻辑做 luz 改造。首先要对两个数据集做一个小小的升级。在手写循环训练逻辑中,我们是直接把整个 x_train 塞进了模型。luz 强制要求我们使用 dataset 或 dataloader 来管理数据。
ames_dataset <- dataset(
name = "ames_ds",
initialize = function(x, y) {
self$x <- torch_tensor(x, dtype = torch_float32())
self$y <- torch_tensor(y, dtype = torch_float32())
},
.getitem = function(i) {
list(x = self$x[i, ], y = self$y[i, ])
},
.length = function() {
self$x$size(1)
}
)
train_ds <- ames_dataset(x_train, y_train)
test_ds <- ames_dataset(x_test, y_test)
train_dl <- dataloader(train_ds, batch_size = 128, shuffle = TRUE)
test_dl <- dataloader(test_ds, batch_size = 128)对于已经存在内存里的张量,可以使用 tensor_dataset 函数一键封装。
train_ds <- tensor_dataset(
torch_tensor(x_train, dtype = torch_float()),
torch_tensor(y_train, dtype = torch_float())
)
train_dl <- dataloader(train_ds, batch_size = 128, shuffle = TRUE)
# 同理测试集的构建模型依然使用原有模型结构
输入层 ncol(x_train) -> 隐藏层 (128, ReLU) -> 隐藏层 (64, ReLU) -> 输出层 (1)
但改造成 nn_module 形态,方便 luz 框架调用
AmesNet <- nn_module(
"AmesNet",
initialize = function(input_dim) {
self$net <- nn_sequential(
nn_linear(input_dim, 128),
nn_relu(),
nn_linear(128, 64),
nn_relu(),
nn_linear(64, 1)
)
},
forward = function(x) {
self$net(x)
}
)接下来使用 luz 框架来训练模型:这个框架下,原本复杂的训练循环、梯度清零、反向传播、状态切换,全部被压缩在以下三个标准化的管道中,管道通过 tidyverse 体系的 %>% 或者 R 原生管道符 |> 进行传递。
- 组装
setup() - 配置
set_hparams()和set_opt_hparams - 训练
fit()
AmesNet_fitted <- AmesNet %>%
# 1. 建立 (Setup): 指定损失函数和优化器
setup(
loss = nn_mse_loss(),
optimizer = optim_adamw, # AdamW 通常比 Adam 更稳健
metrics = list(
luz_metric_rmse() # 监控 RMSE
)
) %>%
# 2. 设置超参数 (Set Hparams): 传递给 initialize 的参数
set_hparams(input_dim = ncol(x_train)) %>%
set_opt_hparams(lr = 0.002) %>% # 学习率与权重衰减
# 3. 训练 (Fit)
fit(
train_dl,
epochs = 50,
valid_data = test_dl,
verbose = TRUE # 显示进度条
)因为在 metrics 声明了要追踪 RMSE,所以在执行过程控制台会出现一个动态更新的进度条。它不仅显示当前的 Training Loss(rmse),还会自动在一个 Epoch 结束后计算 Validation Loss(rmse)。
参数说明:
setup()可以配置 loss function,训练模型的优化器 optimizer(任意在 torch 中存在的,或者通过optimizer()函数创建的),或者传递一个训练过程中跟踪的指标列表,luz会自动在训练和验证过程中计算它们,无需手动编写数学公式。set_hparams()将模型的超参数传递给预先定义nn_module的方法initialize(),模型定义与具体参数分离。在本例中h1和h2两个超参数传到了前面定义的 net。set_opt_hparams()用来传递优化器函数使用的超参数。例如,函数optim_adam()可以接受参数 lr 来指定学习率。fit()是luz最强大的地方。当你运行这段代码时,luz在后台默默完成了以下工作:- 接受
setup()提供的模型规范,并使用指定的训练和验证 Dataloader 进行训练和验证。在训练循环中自动开启train()模式,在验证循环中自动切换到eval()模式并关闭梯度计算。 - 通过
accelerator自动检测是否有 GPU,并将数据和模型移动到正确的设备上,默认无需特殊声明。 - 提供了一个实时的、带有预计剩余时间的进度条。
- 如果在训练中途出错(比如内存溢出),它会尝试安全退出并保存当前状态。
- 接受
训练结束后,fit 函数返回一个对象,这里命名为 AmesNet_fitted,它保存了所有的训练历史。
在 R 语言中,我们要看历史数据,第一反应自然是 plot(),你的直觉是对的:
plot(AmesNet_fitted)获得优化目标和 epochs 的关系图:
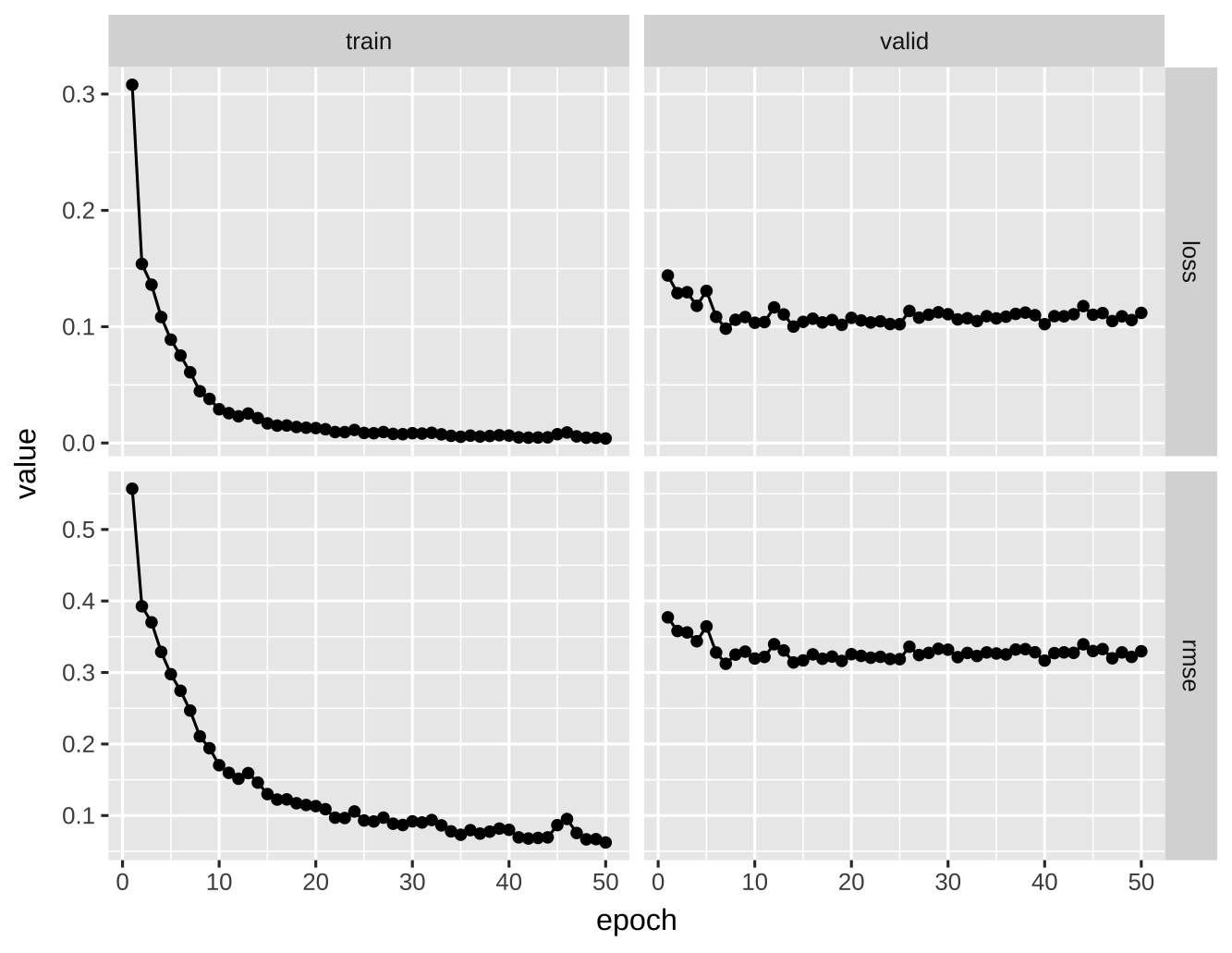
从这张图上我们可以看到非常典型的过拟合现象:
- 训练集 loss 持续在下降,验证集的 loss 在 10 epoch 之后几乎不怎么变化。
- 训练集 在 50 个 epoch 以后 loss 已经接近 0 , 但验证集的 Loss 还有 0.3+。
要观察模型最后一个 epoch 的 loss 和 RMSE 值,我们可以使用 evaluate() 和 get_metrics()
AmesNet_fitted |> evaluate(test_dl) |> get_metrics()
# # A tibble: 2 × 2
# metric value
# <chr> <dbl>
# 1 loss 0.116
# 2 rmse 0.330细心的读者肯定发现了一个有趣的现象。虽然这个版本存在过拟合的现象,但是 RMSE (0.3297) 比第 4 章手写循环的版本 (0.3632) 低很多!
模型结构、优化器和数据都是完全相同的,仅因为训练方式不同,luz 版本的预测误差降低了约 10%。这并非偶然,而是“训练动力学”直观体现:
- 手写循环实际执行的是 Full Batch 梯度下降,它将几千条数据一次性喂给模型。计算出的梯度非常精确,但也非常“平滑”,泛化能力差。luz 版本执行的是 Mini-batch 随机梯度下降,每个 batch 128 个样本,容易跳出糟糕的局部最优解。
- 手写循环的数据顺序不变,但 luz 版增加了 shuffle,这强迫模型必须关注特征本身的规律,而非数据的排列顺序。
- 手写循环的训练了 1000 轮,迭代次数太多了,loss 几乎降到了 0。luz 仅训练 50 轮,模型学会了通用规律,但还没有来得及死记硬背。“恰到好处的停止”本质上就是一种隐式的正则化。
6.4.3 引入正则化
既然模型存在过拟合情况,原始的模型定义就需要大刀阔斧的改造一下2。使用 nn_module 做一个封装,同时定义一些关键参数。比如
- 第一个隐藏层神经元数量
h1。 - 第二个隐藏层神经元数量是
h1的一半(体现漏斗结构)。 - 两个隐藏层均使用 batch norm。
- 在两个隐藏层的 relu 后各增加一个随机失活层,共享参数为
dr。
FlexibleMLP <- nn_module(
"FlexibleMLP",
initialize = function(in_features, h1 = 128, dr = 0.3) {
self$fc1 <- nn_linear(in_features, h1)
self$bn1 <- nn_batch_norm1d(h1)
self$fc2 <- nn_linear(h1, floor(h1 / 2))
self$bn2 <- nn_batch_norm1d(floor(h1 / 2))
self$fc3 <- nn_linear(floor(h1 / 2), 1)
self$act <- nn_relu()
self$dropout <- nn_dropout(dr)
},
forward = function(x) {
x %>%
self$fc1() %>% self$bn1() %>% self$act() %>% self$dropout() %>%
self$fc2() %>% self$bn2() %>% self$act() %>% self$dropout() %>%
self$fc3()
}
)接下来是训练,和前面的内容基本一样 (weight_decay 通过 set_opt_hparams 传递到了模型里):
input_dim <- ncol(x_train)
FlexibleMLP_fitted <- FlexibleMLP %>%
setup(
loss = nn_mse_loss(),
optimizer = optim_adamw, # AdamW 通常比 Adam 更稳健
metrics = list(
luz_metric_rmse() # 监控 RMSE
)
) %>%
set_hparams(in_features = input_dim, h1 = 128, dr = 0.3) %>%
set_opt_hparams(lr = 0.002, weight_decay = 1e-5) %>% # 学习率与权重衰减
fit(
train_dl,
epochs = 50,
valid_data = test_ds,
verbose = TRUE # 显示进度条
)再观察模型训练的过程:
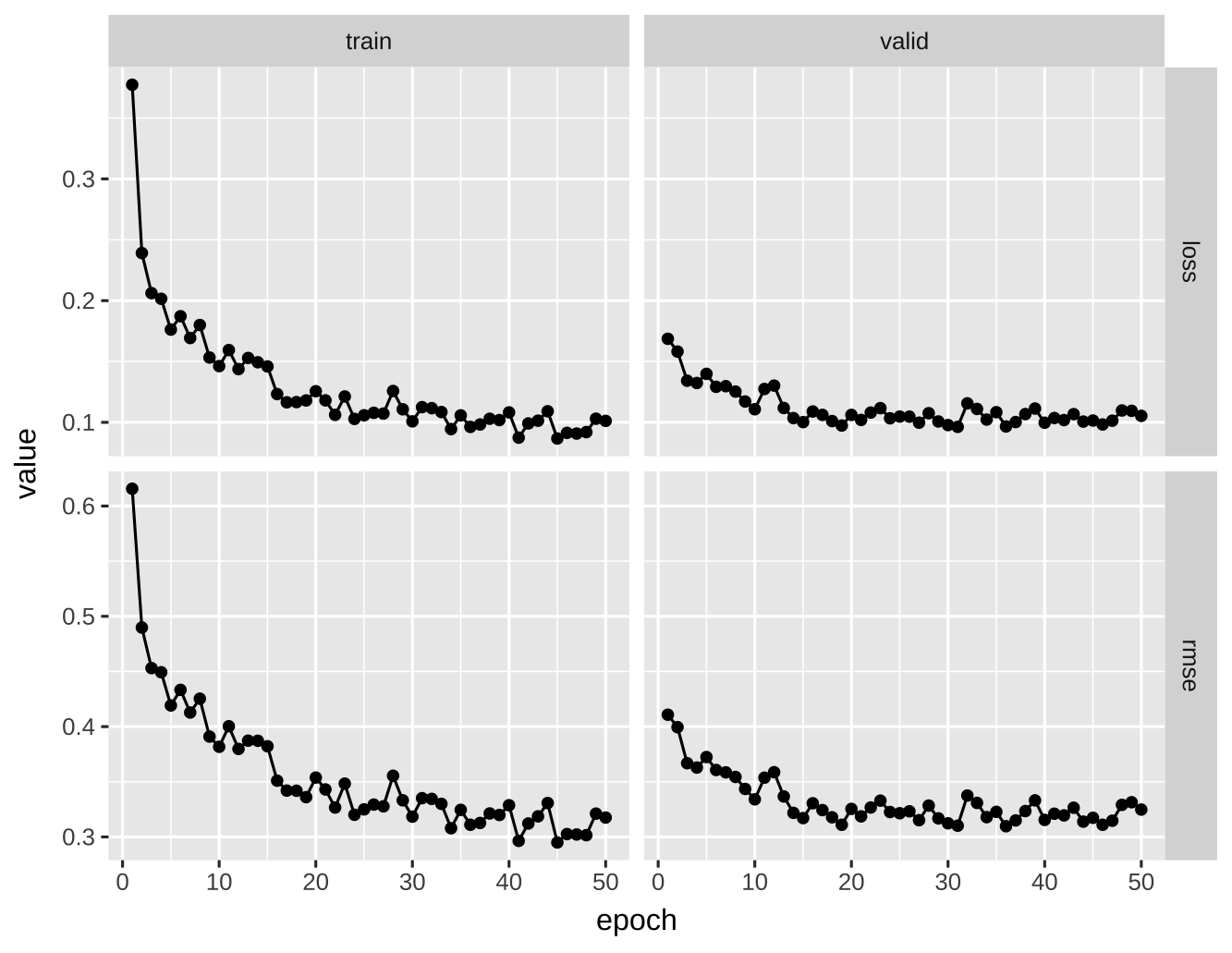
有几个有趣的现象:
- 之前的训练集 Loss 是 0.00,现在增加到了 0.10。通过正则化的方式,模型不能通过强行记忆的方式来降低 loss,而只能困难地学习规律。虽然训练集的 loss 不那么好看了,但更加真实。
- 曲线的锯齿状比之前要厉害很多,这正是 dropout 的副作用:每个 batch 随机扔掉的神经元不同,所以会有波动。
- 剪刀差闭合了!训练集和验证集的表现一致,模型的泛化能力变得更强。
但我们也发现了一个问题,验证集的 loss 在 20 个 epoch 之后就不怎么变了,再训练下去没有意义。是否有什么自动机制提前停止训练呢?
接下来引入的回调函数就是处理类似情况的 luz 模块。
6.4.4 回调函数
luz 的强大之处在于其回调系统(Callbacks)。回调函数允许我们在训练周期的特定时间点(如每个 Batch 结束、每个 Epoch 结束、训练开始前等)插入自定义逻辑。
最常用的两个工程化回调是:早停法和模型检查点。
一、早停法 (Early Stopping)
如果模型在第 20 轮就已经收敛,强行训练到 100 轮不仅浪费计算资源,还可能导致过拟合(验证集 Loss 反升)。luz_callback_early_stopping 就像一个监工,一旦发现验证集指标不再改善,就强制停止训练。
early_stop_cb <- luz_callback_early_stopping(
monitor = "valid_loss", # 监控验证集损失
patience = 5, # 如果连续 5 轮 Loss 都没有改善
min_delta = 0.001, # 且改善幅度小于 0.001
mode = "min" # 对于 Loss,我们要越小越好
)二、模型检查点
早停法有一个小缺陷:它是在第 N 次变差后才停止的。这意味着训练结束时的那个模型,其实并不是表现最好的模型(通常是 N 个 Epoch 之前的那个最好)。
模型检查点的作用就是:时刻盯着验证集 Loss,只要发现了目前的“历史最佳”成绩,就立刻把这一刻的模型参数保存到硬盘上(覆盖旧的存档)。这样,无论训练在哪里停止,你硬盘里存的那个文件永远是验证集分数最高的那个。
checkpoint_cb <- luz_callback_model_checkpoint(
path = "checkpoints/ames_model_{epoch:02d}.pt", # 保存路径模板
save_best_only = TRUE, # 只保存表现最好的模型
monitor = "valid_loss",
mode = "min"
)最后,将定义好的回调加入训练管道:
final_fit <- FlexibleMLP |>
setup(
loss = nn_mse_loss(),
optimizer = optim_adamw, # AdamW 通常比 Adam 更稳健
metrics = list(
luz_metric_rmse() # 监控 RMSE
)
) |>
set_hparams(in_features = input_dim, h1 = 128, dr = 0.3) |>
set_opt_hparams(lr = 0.002, weight_decay = 1e-5) |>
fit(
data = train_dl,
valid_data = test_dl,
epochs = 100,
callbacks = list(
early_stop_cb,
checkpoint_cb
)
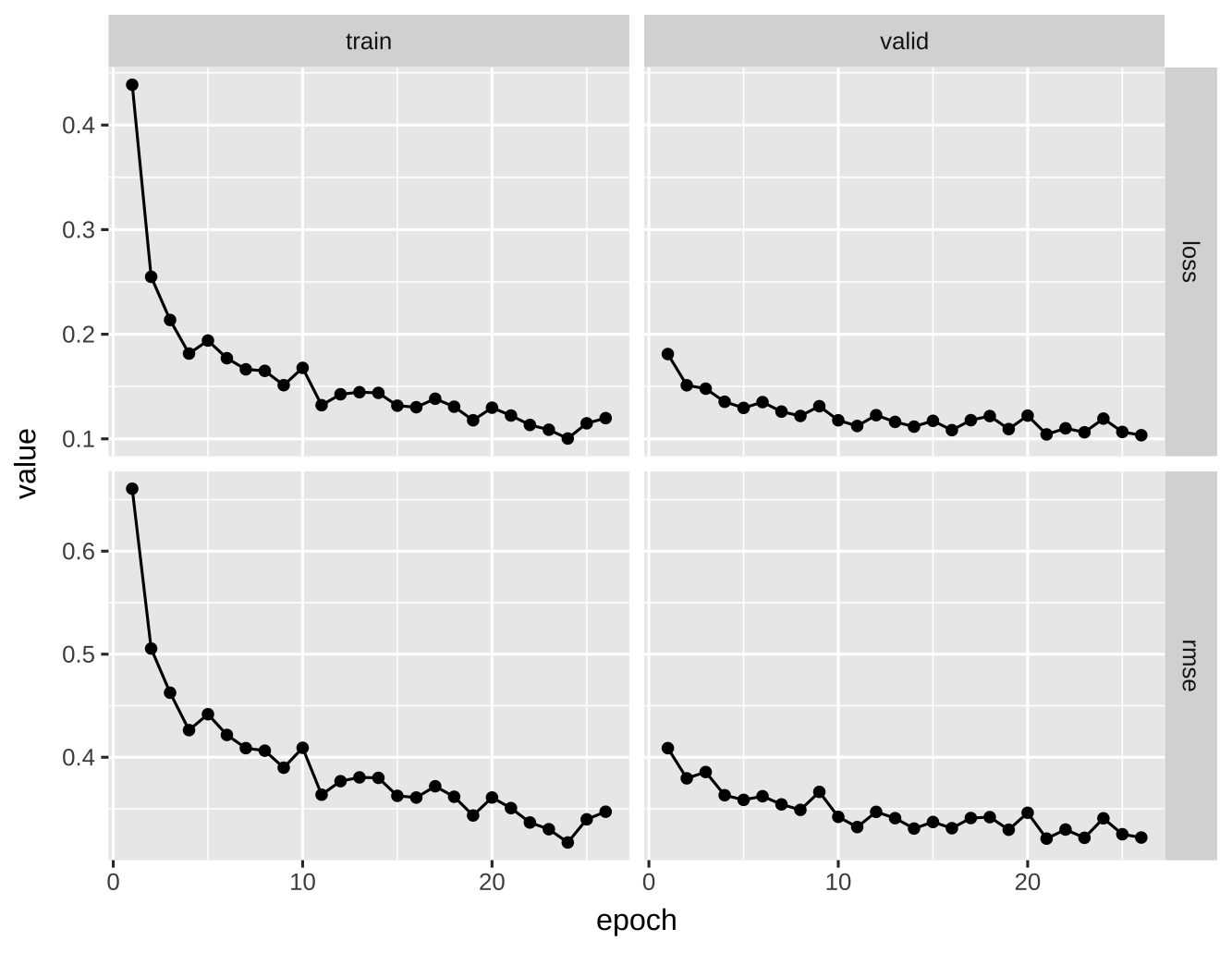
)当你运行这段代码时,请留意控制台的输出
- 虽然我们设置要跑 100 个 Epoch,但第 26 个 Epoch 就自动结束了。最后一行会提示
Early stopping at epoch 26 of 100。 checkpoints目录下多了若干个.pt文件3。
观察训练过程:
6.5 超参数调优
在前面的章节中,我们构建了多层感知机,并使用 luz 简化了训练循环。然而,无论是隐藏层的神经元数量(128 还是 256?)、Dropout 的比例(0.1 还是 0.5?),还是优化器的学习率(Learning Rate),我们似乎都在凭“直觉”或“默认值”行事。
在深度学习社区,这常被戏称为“炼丹”。但工程实践不能依赖运气。本节我们将介绍一套科学的超参数调优(Hyperparameter Tuning)方法论,并利用 R 语言强大的数据处理能力实现自动化搜索。
6.5.1 完美的学习率
学习率(Learning Rate, \(\eta\))是深度学习中最重要的超参数,没有之一。它决定了模型参数更新的步伐大小:
- 若 \(\eta\) 太小:模型收敛如蜗牛爬行,甚至陷入局部极小值无法自拔。
- 若 \(\eta\) 太大:损失函数会在极小值附近剧烈震荡,甚至直接飞出“峡谷”,导致模型发散(Loss 变为 NaN)。
在 Cyclical Learning Rates (Smith 2017) 提出之前,人们通常通过“盲猜”来设定学习率(如 0.1, 0.01, 0.001)。这种方法既耗时又依赖运气。luz 内置了更先进的 LR Finder 工具,它不再依赖猜谜,而是通过一次科学的实验来探测模型的“底线”。
其原理是对模型进行“压力测试”,它的工作流程如下:
- 从一个极小的学习率(如 \(10^{-7}\))开始。
- 在每一个 Batch(而非每一个 Epoch)迭代结束后,指数级增加学习率。
- 记录下每一步的学习率与对应的 Loss 值。
- 当 Loss 不再下降反而开始剧烈上升(发散)时,立即停止测试。
在 R 中,我们可以直接对定义好的模型管道调用 lr_finder()。注意,这里不需要调用 fit(),因为 lr_finder 内部已经封装了一个特殊的训练循环。
trained_lr <- FlexibleMLP %>%
setup(
loss = nn_mse_loss(),
optimizer = optim_adamw
) %>%
set_hparams(in_features = input_dim) %>%
lr_finder(data = train_dl, verbose = FALSE)
plot(trained_lr)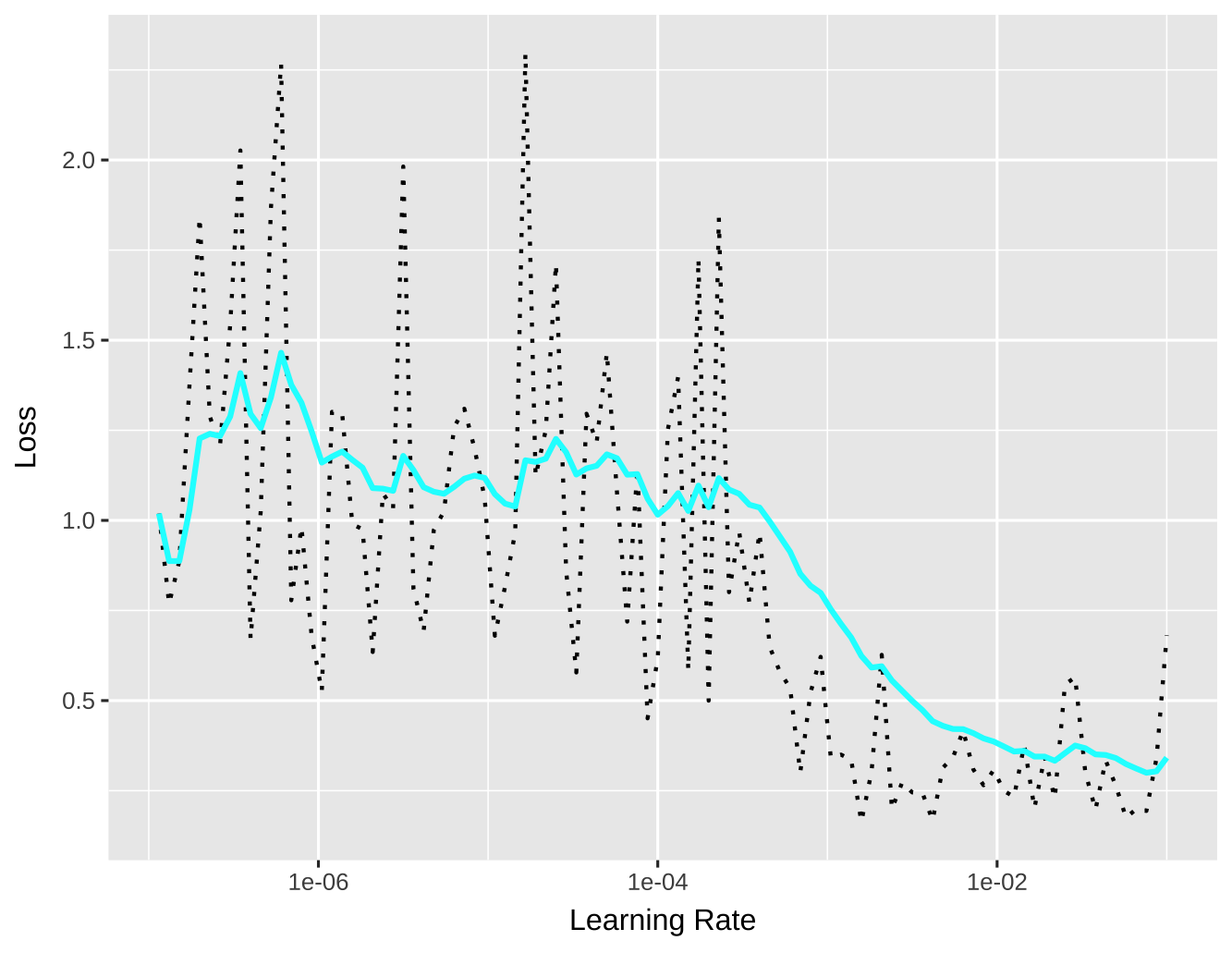
初学者最容易犯的错误是直接选择图中的“Loss 最低点”。然而,正确的读图逻辑应该关注变化率而非绝对值。
请注意那条平滑的青色实线,它是剧烈波动 loss 的指数加权移动平均结果:
- 从左边直到 \(10^{-4}\) 附近,Loss 都在 1.0 到 1.5 之间震荡,没有明显的下降趋势。这说明在这个区间内,学习率太小,模型还没“醒”过来。
- 从 \(10^{-4}\) 开始,曲线出现了一个明显的拐点,然后开始了一路顺畅的下坡。这说明梯度更新开始起作用了。
- 在 \(10^{-2}\) 到 \(3 \times 10^{-2}\) 之间,Loss 达到了最低点(大约 0.3 左右)。
- 图最右端,黑色虚线开始再次剧烈跳动,且青色线没有进一步下降的趋势,甚至有抬头的迹象。这说明学习率已经过大,模型开始不稳定了。
寻找平滑曲线(青色线)下降最陡峭的中点,或者找到 Loss 的最低点,然后除以 10。
因此,我们建议为 lr 为 0.003。
6.5.2 搜索策略
确定了学习率的范围后,我们还需要确定网络结构参数(如 hidden_units)和正则化参数(如 dropout_rate, weight_decay)。在高维空间中搜索最优组合,主要有两种策略:
一、网格搜索 (Grid Search):
- 设定每个参数的候选列表(如 Dropout: [0.1, 0.3, 0.5]),尝试所有排列组合。
- 存在“维数灾难”。如果有 4 个参数,每个取 5 个值,就需要训练 \(5^4 = 625\) 次。且对于不重要的参数,网格搜索会浪费大量计算资源在重复的有效维度上。
二、随机搜索 (Random Search):
- 为每个参数定义一个统计分布(如 Dropout 服从 \(U(0.1, 0.5)\)),随机采样 \(N\) 组配置进行训练。
- 有研究表明 (Bergstra 和 Bengio 2012),在相同的计算预算下,随机搜索通常比网格搜索更有效。因为在多维空间中,有效的超参数只有 1-2 个,随机采样能探索出每个参数更多的独特取值。
先在大范围内进行随机搜索(Coarse),通过可视化找到 Loss 较低的参数聚集区域,然后在该区域内进行精细的网格搜索(Fine)。这种策略是相对靠谱的逻辑。
随机搜索比网格搜索的效果会更好?有点反直觉,但看完这个例子你就明白了:
set.seed(123)
# 假设模型性能只依赖 x,最佳点在 x = 0.7
true_score <- function(x, y) {
-(x - 0.7)^2 + rnorm(1, sd = 0.01) # y 完全无关
}
# Grid Search(10x10 网格)
grid_x <- seq(0, 1, length.out = 10)
grid_y <- seq(0, 1, length.out = 10)
grid_points <- expand.grid(x = grid_x, y = grid_y)
grid_points$score <- mapply(true_score, grid_points$x, grid_points$y)
best_grid <- grid_points[which.max(grid_points$score), ] # grid 最佳值
# 2. Random Search(100 次)
rand_points <- data.frame(
x = runif(100),
y = runif(100)
)
rand_points$score <- mapply(true_score, rand_points$x, rand_points$y)
best_rand <- rand_points[which.max(rand_points$score), ] # random 最佳值Grid Search 找到的最佳 x = 0.667;Random Search 找到的最佳 x = 0.721
6.5.3 基于 luz 的调优
我们将使用原生的 for 循环来驱动 luz 进行随机搜索,读者也可以考虑 tidyverse 生态的 purrr。
第一步:定义单次实验函数
我们需要一个函数,它接受一组超参数,训练模型,并返回验证集上的最佳评估指标。
fit_one_trial <- function(hparams, train_dl, valid_dl) {
# 打印当前尝试的参数(可选)
message(sprintf("Testing: Units=%d, Drop=%.2f, LR=%.4f, Decay=%.4f",
hparams$units, hparams$drop, hparams$lr, hparams$decay))
fitted <- FlexibleMLP %>%
setup(
loss = nn_mse_loss(),
optimizer = optim_adamw,
metrics = list(luz_metric_rmse())
) %>%
set_hparams(
in_features = input_dim,
h1 = hparams$units,
dr = hparams$drop
) %>%
set_opt_hparams(
lr = hparams$lr,
weight_decay = hparams$decay
) %>%
fit(
train_dl,
epochs = 10, # 搜索阶段 Epoch 可以设少一点以节省时间
valid_data = test_dl,
verbose = FALSE, # 关闭进度条,避免刷屏
callbacks = list(
luz_callback_early_stopping(patience = 3) # 表现不好尽早掐断
)
)
valid_rmse <- get_metrics(fitted) |> filter(
metric == 'rmse' & set == 'valid'
) # 返回验证集上最好的 RMSE
best_metric <- min(valid_rmse$value)
return(best_metric)
}第二步:生成参数空间
我们使用随机搜索策略,生成 24 组候选参数,并增加一列放置 valid 数据集的 RMSE。
LR Finder 为我们指明了 learning rate 的大致方位,0.003 附近。在随机搜索时,我们不再需要满世界乱跑,只需要在 0.001 到 0.006 这个高概率区间内进行地毯式搜索,就能以最小的代价找到全局最优解。
n_trials <- 24
search_grid <- tibble(
trial_id = 1:n_trials,
# 随机采样
units = sample(c(64, 128, 256, 512), n_trials, replace = TRUE),
drop = runif(n_trials, min = 0.0, max = 0.5),
lr = runif(n_trials, min = 0.001, max = 0.006),
decay = 10^runif(n_trials, min = -5, max = -3)
)
search_grid$val_rmse <- numeric(n_trials)第三步:执行搜索
这里我们使用简单的 for 循环,以便我们可以实时看到进度并在每一轮后保存结果(防止程序中途崩溃导致前功尽弃)。
for (i in 1:nrow(search_grid)) {
current_params <- list(
units = search_grid$units[i],
drop = search_grid$drop[i],
lr = search_grid$lr[i],
decay = search_grid$decay[i]
)
try({
score <- fit_one_trial(current_params, train_dl, test_dl)
search_grid$val_rmse[i] <- score
})
gc()
}接着利用 search_grid 训练一颗决策树来拟合超参数与最终 Loss 的关系:
library(rpart)
library(rpart.plot)
fit_tree <- rpart(
val_rmse ~ units + drop + lr + decay,
data = search_grid,
control = rpart.control(cp = 0.05, minsplit = 8)
)
rpart.plot(fit_tree, type = 2, extra = 101)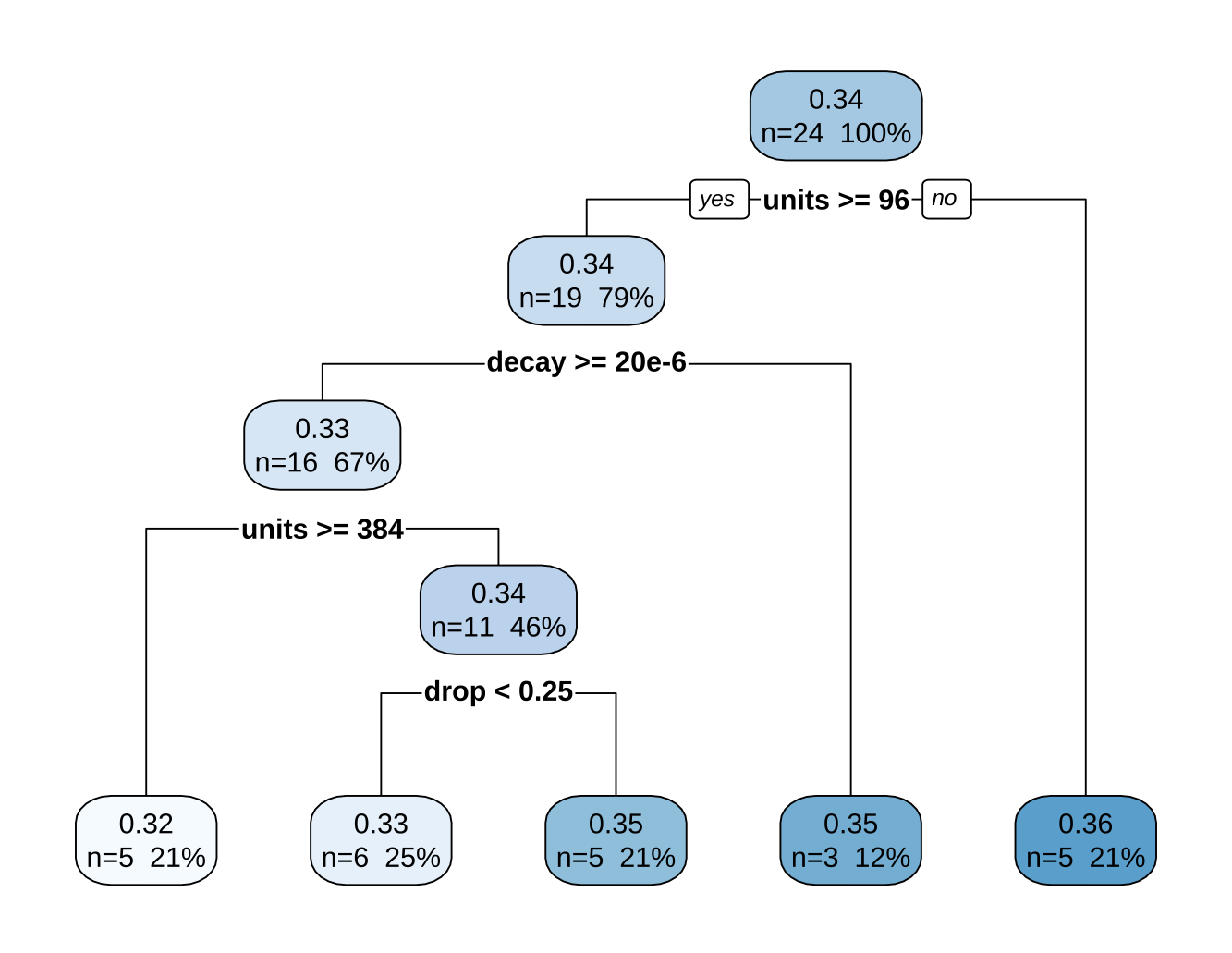
解读分析结果:
- 第一刀 (Units >= 96):决策树告诉我们,只要隐藏层单元数太小(比如 64),验证集误差就会高达 0.36(最右边的分支)。这意味着模型容量不足(Underfitting)。要想获得好成绩,第一步必须加大模型容量。
- 第二刀 (Decay >= 20e-6):在模型够大的前提下,如果没有施加足够的正则化(Weight Decay < 20e-6),误差是 0.35(中间分支)。这意味着模型虽然大了,但开始过拟合(Overfitting)。
- 最佳区域 (Units >= 384):当我们既保证了模型足够大(Units >= 384),又施加了正则化,我们不仅获得了验证集上的最佳成绩(RMSE 0.32),而且这个结果非常稳定(占所有试验的 21%)。
而且有个现象很有意思:
理论上 lr 应该是最重要的因素。但我们前置使用了 lr_finder 确定了学习率的范围。果然在后续的参数空间内找规律,学习率本身没有成为主要的分叉点,侧面说明 lr_finder 策略非常成功,已经消除了最大的不确定性。
lr 大于 0.0045 就不用看了,dropout rate 主要搜索 0.37 以下,
fine_grid <- expand.grid(
# 既然 units 没出现,说明不敏感,直接选一个适中的
units = c(256),
# lr 必须小于 0.0045
lr = c(0.001, 0.002, 0.004),
# drop 必须小于 0.37
drop = c(0.1, 0.2, 0.3),
# Decay 有用,但左分支没用到它,可以设个默认小值
decay = 1e-4
)执行网格搜索结果,最小的参数空间为:
| units | lr | drop | decay | val_rmse |
|---|---|---|---|---|
| 256 | 0.001 | 0.3 | 1e-04 | 0.3190549 |
放大迭代次数,在第 16 步提前停止,RMSE 优化到最优,为 0.3169
xgboost 可以轻松做到 0.3062
虽然 MLP 很强,但面对图像(如 1024x1024 像素),它的参数量会爆炸(100万输入节点),且忽略了像素之间的空间关系。
在第三部分:进阶篇,我们将开启深度学习最辉煌的篇章。