| crim | zn | indus | chas | nox | rm | age |
|---|---|---|---|---|---|---|
| -0.406 | 0.260 | -1.279 | -0.288 | -0.123 | 0.432 | -0.119 |
| -0.337 | -0.505 | -0.425 | -0.288 | -0.123 | -0.261 | 0.560 |
| -0.291 | -0.505 | -0.425 | -0.288 | -0.123 | -0.494 | -1.384 |
| -0.318 | -0.505 | -0.425 | -0.288 | -0.123 | -1.187 | -1.127 |
| -0.302 | -0.505 | -0.425 | -0.288 | -0.123 | -0.332 | 0.712 |
14 解释性与诊断
“抹去人与机器的界限,就是模糊人与神的界限。”
—— 《机械姬》 (E2014)
程序员迦勒受邀对 AI 艾娃进行图灵测试。但他很快发现,单纯的对话已经不够了。他开始质疑:艾娃表现出的情感,究竟是自我意识的觉醒,还是仅仅为了逃脱而计算出的最佳策略?
14.1 打开黑盒
我们需要打开黑盒(Black Box)。 模型给出一个结果(预测)是不够的,我们更想知道它“为什么”这么做。是真聪明还是假聪明?可解释性 AI(XAI)就是要像迦勒一样,通过特征重要性与归因分析,剖析模型的决策逻辑,建立人类对 AI 的信任。
在 R 语言的生态中,统计学家和领域专家往往更关注模型的可信度与因果逻辑,而不仅仅是预测精度。因此,建立一套完善的模型诊断与解释体系,是模型从实验室走向生产环境的必经之路。
在深度学习的早期,提升准确率(Accuracy)是首要目标。但在许多高风险或严谨的领域,单纯的高准确率并不足以支撑决策。我们需要解释性的理由通常基于以下三个维度:
1. 金融合规与公平性 (Financial Compliance)
在金融风控领域,模型决定着贷款审批或信用卡额度。如果一个基于深度学习的模型拒绝了一位用户的申请,根据许多国家和地区的法律法规(如 GDPR 中的“解释权”),金融机构必须提供拒绝的具体理由(例如:“因为您的近期负债率过高”,而不是“因为模型的输出值为 0.2”)。此外,我们需要审查模型是否利用了种族、性别等敏感特征作为决策依据,从而避免算法歧视。
2. 医疗诊断的安全性 (Safety in Medical Diagnosis)
在医疗影像分析中,准确率高达 99% 的模型也可能存在致命缺陷。一个著名的案例是,某个检测皮肤癌的模型在训练数据上表现完美,但经过诊断分析后发现,模型实际上是在识别图片中是否出现了“尺子”。因为只有病变严重的皮肤照片中才会放置尺子进行测量。这种“捷径学习”(Shortcut Learning)在测试集上可能无法被发现,只有通过解释性工具(如热力图)才能揭示模型关注的是病灶还是背景噪音。
3. 科研发现与因果推断 (Scientific Discovery)
对于使用 R 语言的科研工作者而言,深度学习不仅是预测工具,更是探索工具。例如,在生物信息学中,如果我们训练了一个预测蛋白质功能的模型,我们更关心的是:模型关注了氨基酸序列中的哪一段?这可能暗示了某种未知的生物学机制。在这种场景下,模型的可解释性能够辅助人类构建新的科学假设。
14.2 错误分析
从宏观入手看 bad case 是最快捷的途径。当我们训练完模型并在验证集上得到一个准确率(例如 92%)时,工作并没有结束。剩下的 8% 错误样本中往往隐藏着比那 92% 正确样本更有价值的信息。
模型效果为 86.9% 准确率,损失为 0.416。
> get_metrics(evaluation)
# A tibble: 2 × 2
metric value
<chr> <dbl>
1 loss 0.416
2 acc 0.869混淆矩阵为:
> table(as.numeric(test_pred), as.numeric(test_ds$y))
1 2 3 4 5 6 7 8 9 10
1 804 2 23 5 0 0 1 2 16 2
2 10 942 1 1 0 1 0 0 11 34
3 18 2 806 35 12 16 16 7 3 1
4 35 7 40 785 40 147 21 34 12 12
5 11 0 57 21 875 24 11 19 2 0
6 6 0 20 77 12 777 3 35 0 1
7 11 2 30 51 27 15 939 2 5 3
8 10 1 19 18 31 19 8 899 0 3
9 50 7 3 4 1 1 1 1 936 15
10 45 37 1 3 2 0 0 1 15 929但我们需要具体的 case 分析,才能知道模型在哪些样本上出错。
错误分析 (Error Analysis) 是一套系统性的检查流程,旨在通过剖析模型失败的案例来定位其弱点。最高效的切入点就是分析 Top-N 高损失样本。
在分类任务中,损失函数(Loss)衡量了预测分布与真实标签的差异。一个样本的 Loss 越高,意味着模型对该样本的判断错得越离谱(或者模型虽然预测对了类别,但置信度极低)。
在 torch 中,标准的损失函数(如 nn_cross_entropy_loss)默认会返回一个标量(Scalar),即所有样本损失的平均值。为了进行错误分析,我们需要获取 batch 中每一个样本的独立损失值。
我们可以通过设置 reduction = 'none' 来实现这一点。以下是 R torch 的实现逻辑:
analyze_top_losses <- function(
model, dataloader, device, top_k = 5
) {
model$eval() # 务必切换到评估模式 (关闭 Dropout 等)
# 用于收集结果的列表
results_list <- list()
batch_counter <- 1
# 定义不进行平均的损失函数
criterion_no_reduce <- nn_cross_entropy_loss(reduction = "none")
coro::loop(for (batch in dataloader) {
# 1. 数据迁移 (cifar10_dataset 返回的是 list(x, y))
inputs <- batch[[1]]$to(device = device)
targets <- batch[[2]]$to(device = device)
# 2. 前向传播
with_no_grad({
outputs <- model(inputs)
# 3. 计算逐样本损失 (关键步骤)
# 结果是一个形状为 (batch_size) 的向量,而不是标量
individual_losses <- criterion_no_reduce(outputs, targets)
})
# 4. 收集结果
results_list[[batch_counter]] <- as.numeric(individual_losses$cpu())
batch_counter <- batch_counter + 1
})
# 5. 整合所有 Batch 的 Loss
all_losses <- unlist(results_list)
# 6. 找出 Loss 最高的 Top-N 索引
sorted_indices <- order(all_losses, decreasing = TRUE)
top_n_indices <- head(sorted_indices, top_k)
top_n_values <- head(all_losses[sorted_indices], top_k)
return(list(indices = top_n_indices, losses = top_n_values))
}
# 假设 raw_model 是提取出的 torch 模型,test_dl 是验证集 DataLoader
diagnosis <- analyze_top_losses(
model = fitted$model,
dataloader = test_dl,
device = "mps"
)以 CIFAR-10 数据集为例,我们提取出 Top 6 高损失样本的索引为 [5512, 7275, 8744, 1686, 3786, 5418]:

注意
CIFAR-10 数据集本来是 32x32 的图像,为了适配 MobileNetV2 模型强行将其放大了 4 倍。虽然显示为 128x128,但是视觉上感觉不太清晰。笔者实际观察,图像 1、4、5 虽然 loss 很高,但也并不好分辨。
一旦我们提取出这些高 Loss 样本,通常会将它们可视化出来,并进行人工审查。你会发现错误通常归为以下几类:
- 标注错误 (Label Errors):图像其实是“猫”,但数据集标签错误地标记为“狗”。这种情况下,模型其实是“对”的。发现这类错误可以帮助我们清洗数据集。
- 模糊与遮挡 (Ambiguity & Occlusion):图像本身非常模糊,或者主体被严重遮挡。这提示我们需要在数据增强环节加入更多的高斯模糊或随机遮挡(Random Erasing),以提升模型的鲁棒性。
- 困难负样本 (Hard Negatives):某些样本极其相似但属于不同类别(例如哈士奇与狼)。如果模型在这些样本上频繁出错,说明模型未能捕捉到细微的特征差异。这可能需要我们调整网络结构,引入注意力机制,或者使用对比学习(Contrastive Learning)来拉大类间距离。
- 分布外数据 (OOD Data):验证集中可能混入了训练集中从未出现过的场景(例如训练集全是白天的车,验证集出现了一张夜晚的车)。这揭示了模型的泛化边界。
通过这种“透视”黑盒的方式,我们不再是盲目地调参(炼丹),而是基于证据对数据处理管道或模型架构进行有针对性的修正。这是从“跑通代码”进阶到“掌控模型”的关键一步。
14.3 宏观机制分析
我们使用第 5 章波士顿房价预测这个案例说明。
在深入分析某一套特定房产的预测结果之前,我们需要先退后一步,审视模型的全局行为。我们需要回答两个核心问题:
- 哪些特征主导了模型的决策?
- 模型学到的函数关系长什么样?是简单的直线,还是复杂的曲线?
14.3.1 置换重要性
在深度神经网络中,参数(Weights)多达数万个且高度纠缠,我们无法像线性回归那样直接通过系数大小(Coefficient)来判断特征的重要性。
为此,我们采用置换重要性 (Permutation Importance) 的方法。其逻辑非常朴素:“如果我把这个特征弄乱,模型的预测性能会下降多少?”
如果在验证集上随机打乱 lstat(低收入人口比例)这一列,导致模型的 RMSE 误差翻倍,说明模型极度依赖这个特征。反之,如果打乱 chas(是否临河),误差纹丝不动,说明模型压根没把它放在眼里。
DALEX 可以自动帮我们完成这个繁琐的计算并绘图。
创建通用解释器:
explainer <- DALEX::explain(
model = model,
data = df_test_x, # X 是标准化的,即标准化后的特征变动
y = y_test_vec, # 真实标签
predict_function = custom_predict,
label = "Boston MLP", # 模型名称
type = "regression", # 任务类型:回归
verbose = FALSE # 不显示进度条
)绘制图形:
vi <- model_parts(explainer, B = 50)
print(plot(vi) + ggtitle("特征重要性"))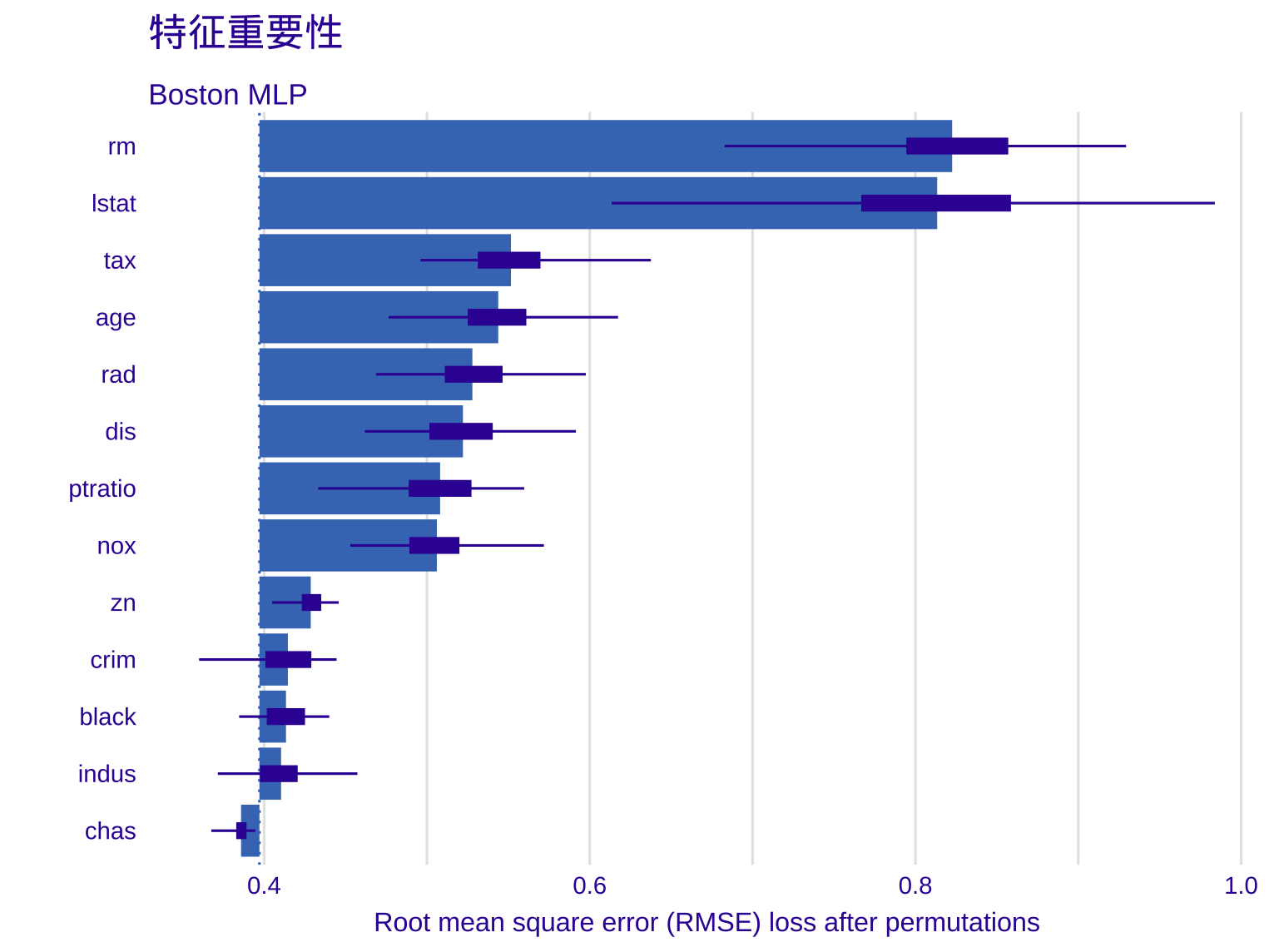
图表解读:
- 条形的长度代表了 RMSE 损失的增加量。条形越长,特征越重要。
- lstat (低收入人口比例) 和 rm (房间数) 稳居前两名。这与我们的直觉高度一致:地段和面积是决定房价的核心因素。
- 那些条形极短的特征(可能是 zn 或 chas),提示我们在后续的模型压缩或特征筛选中可以将它们剔除,以降低模型复杂度。
14.3.2 局部依赖图
知道“谁重要”还不够,我们更想知道它是“怎么起作用的”。
在线性回归中,特征的影响是固定的(斜率)。但在神经网络中,特征的影响往往是非线性的。例如,房间数从 1 间变 2 间,与从 10 间变 11 间,对房价的提升幅度显然是不同的。
局部依赖图 (Partial Dependence Plot) 能够帮我们画出这种关系曲线。它展示了在保持其他特征平均水平不变的情况下,目标特征的变化如何影响预测值的期望。绘制 lstat 变量的依赖:
pdp_lstat <- model_profile(explainer, variables = "rm")
plot(pdp_lstat) +
labs(title = "PDP: rm vs Price", subtitle = "")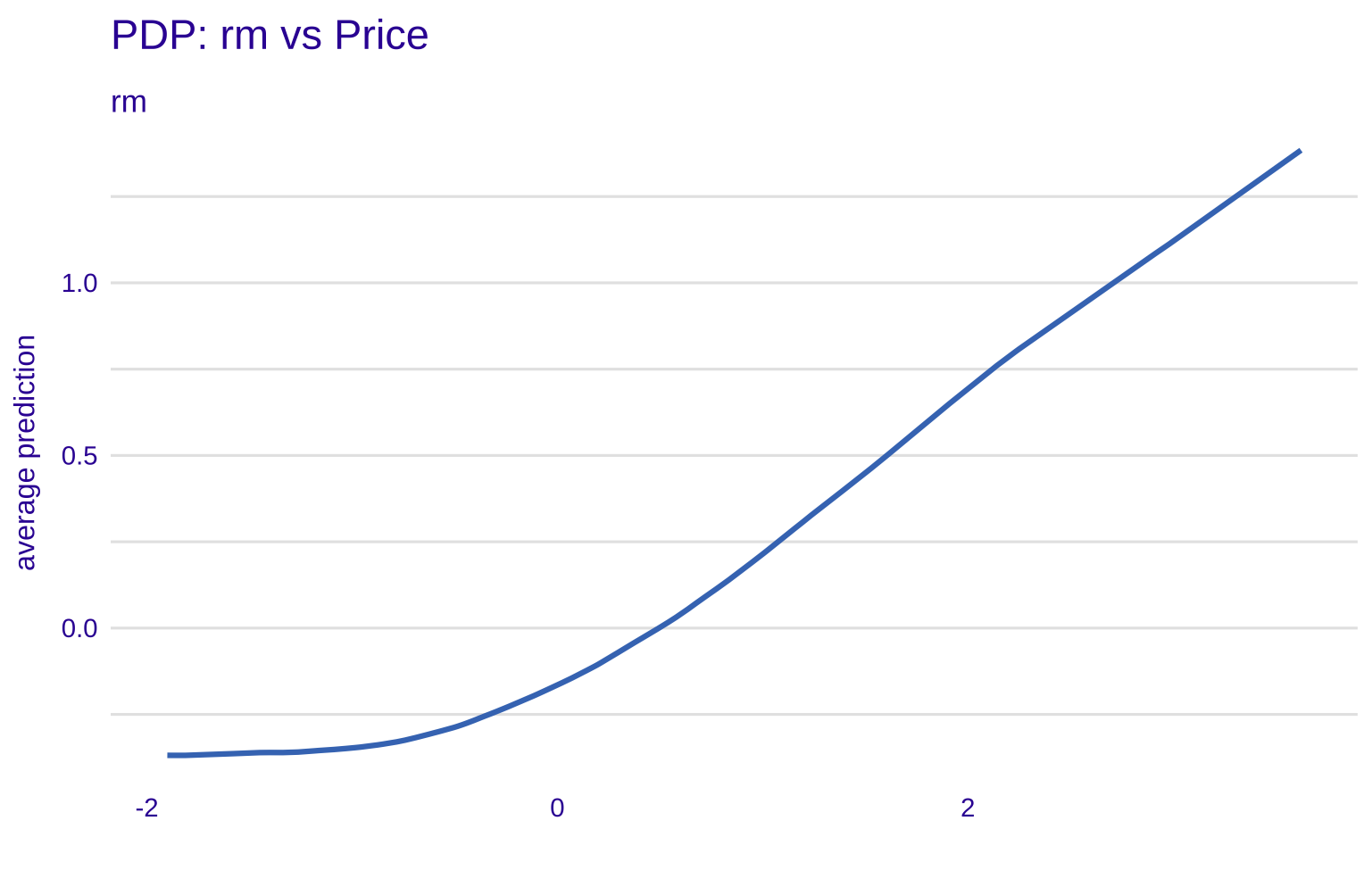
这正是我们使用深度学习(R torch)而不是线性回归(lm)的原因。请观察生成的曲线,它揭示了房间数与房价之间微妙的非线性关系:
- 曲线并非一条贯穿始终的直线。如果是线性回归,它会强制画出一条斜线,这可能会导致对小户型房价的低估(甚至预测出负数),或者对豪宅价格的误判。
- 分段的物理意义 (Regime-Switching):神经网络敏锐地捕捉到了不同区间内截然不同的市场逻辑:
- 左侧的“地板效应” (\(x < -1\)):注意看 \(x\) 轴左侧(代表房间数很少的小户型),曲线几乎是平的。模型“学会”了一个常识:房子本身的地皮和基础配套是有底价的。即使房间数再减少(比如从 2 间变成 1 间),房价也不会无限下跌,而是维持在一个基础水平。这是线性模型很难自动捕捉到的“价格刚性”。
- 右侧的“高敏感区” (\(x > -0.5\)):当房间数超过某个阈值(接近平均水平)后,曲线开始呈现陡峭的上升趋势。这意味着在正常及改善型住房市场中,房间数是硬通货——每增加一个房间,房价都会显著提升。
- 在 \(x \approx -1\) 到 \(x \approx 0\) 之间,曲线完成了一次平滑的转折。这暗示模型学到了市场的“分水岭”:房子是从什么时候开始从“仅满足基本居住(不敏感)”跨越到“追求舒适度(高敏感)”的。
这种对复杂现实世界的非线性拟合能力,正是神经网络的魅力所在。通过 PDP,我们得以验证模型是否学到了符合业务逻辑的规律(如房价的底线逻辑),而不是单纯地过拟合噪声。
14.4 特征贡献
对于表格数据,尤其是涉及大量特征的房价预测模型,我们最想知道的是:“为了得到这个预测结果,模型究竟最看重哪个特征?”
为了回答这个问题,我们需要深入到数据的微观层面。我们将介绍两种方法:一种是直观的Break Down(逐步拆解法),另一种是更严谨的SHAP 值(沙普利值)。
14.4.1 Break Down
在进行归因之前,我们需要一个“参照系”,即所有的测试集数据 x_test。我们选定测试集中的第一条数据(Case 1)作为我们的主角,解释为什么它的预测结果是那样。我们的主角数据 x_test 的前 5 行(7 列)如下所示。请注意,数据已经经过了标准化(Standardization),所以 0 代表平均水平,负数代表低于平均,正数代表高于平均。
第一行(Case 1)就是我们要解释的对象。它的 rm(房间数)是 0.432,crim(犯罪率)是 -0.406。
逐步替换法
Break Down 的核心思想是:将预测结果看作是从“平均值”出发,经过一个个特征的“修正”,最终到达“预测值”的过程。
它的计算逻辑非常像控制变量法。我们假设有一个背景数据集(Reference Data),通常就是整个训练集或验证集。
计算步骤详解:
- 计算基线 (Baseline):首先,我们计算模型在整个背景数据集上的预测平均值。假设平均房价预测值为 \(v_{avg}\)。这就是我们的起点。
- 第一步替换:我们将背景数据集中所有样本的第一个变量(比如 rm),全部强制替换为 Case 1 的对应值(即全部改成 0.432)。
- 此时,数据集中只有 rm 这一列和 Case 1 一样,其他列还是原来的。
- 让模型对这个“半修改”的数据集进行预测,计算新的平均值 \(v_{rm}\)。
- 贡献归因:\(v_{rm} - v_{avg}\) 就是 rm 这个特征带来的贡献。
- 第二步替换:保持 rm 已经是 0.432 不变,我们再将第二个变量(比如 lstat)在背景数据集中全部替换为 Case 1 的值。
- 此时,数据集中 rm 和 lstat 两列都变成了 Case 1 的样子。
- 计算新的预测平均值 \(v_{rm+lstat}\)。
- 贡献归因:\(v_{rm+lstat} - v_{rm}\) 就是 lstat 在 rm 已知基础上的额外贡献。
- 重复上述步骤,直到所有变量都被替换为了 Case 1 的值。
- 当所有变量都替换完后,此时的数据集其实就是无数个 Case 1 的副本。预测的平均值自然就等于 Case 1 本身的预测值。
这个过程完美地将总差距(预测值 - 平均值)分配给了每一个特征。
瀑布图 (Waterfall Plot)
构建 break down 对象:
new_house <- df_test_x[2, , drop = FALSE]
bd <- predict_parts(explainer,
new_observation = new_house,
type = "break_down")
print(plot(bd) + ggtitle("单样本归因 (Break Down)"))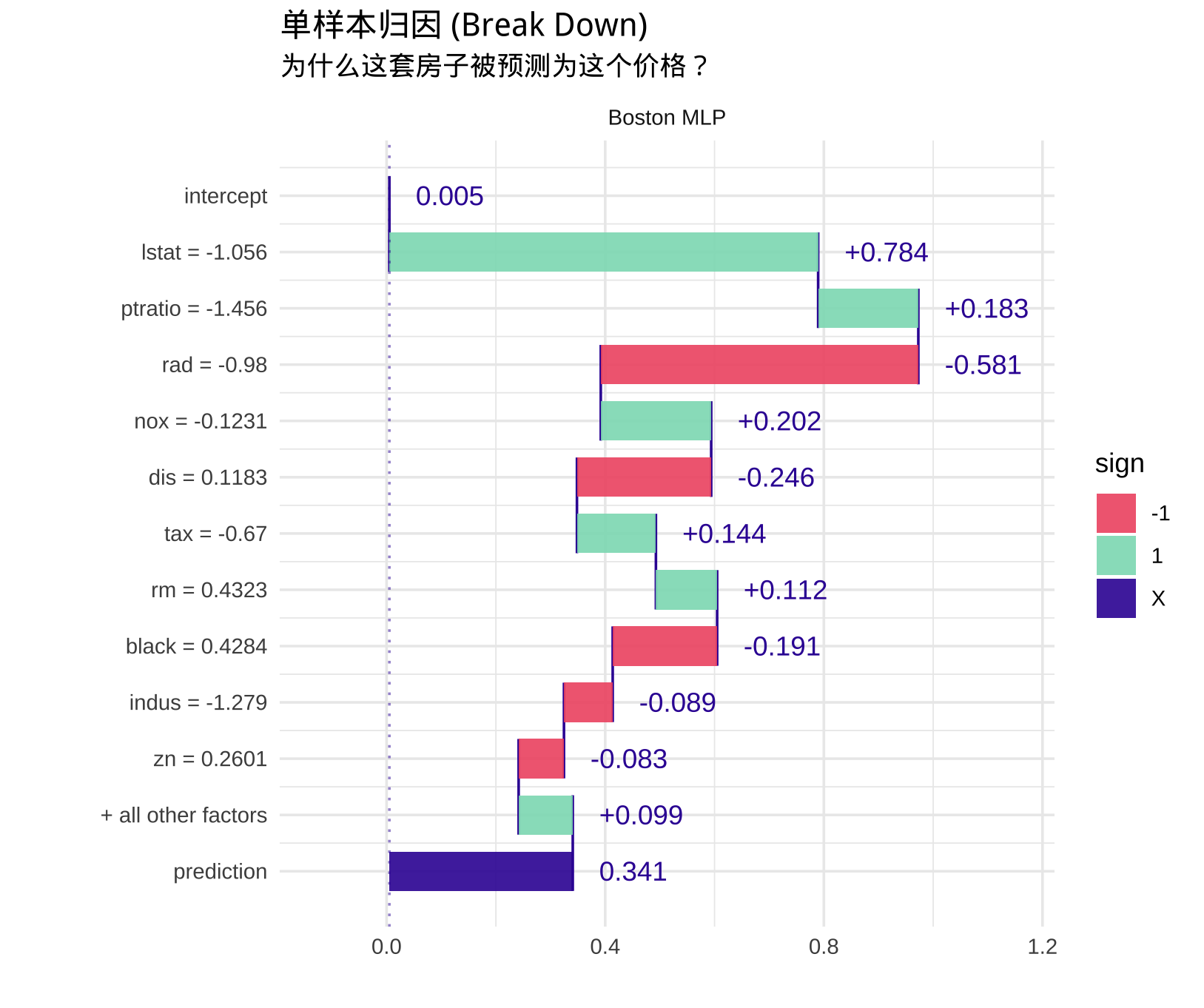
图表解读:
- Intercept (基准):所有房子的平均预测价。
- lstat (绿色条 +0.784):这是贡献最大的正向因子。数据表明该社区的 lstat(低收入人口比例)远低于平均值(负数)。业务解读为:“因为这里是富人区,所以房价大幅上涨。”
- ptratio (绿色条 +0.183):这也起到了正向作用。该地区生师比低(教育资源好),进一步推高了房价。
- rad (红色条 -0.581):这是主要的负向因子。rad 代表高速公路通达度。模型认为该房产的交通便利程度不足,或者该区域的交通特征不符合高价房标准,因此对房价打了折扣。
- Prediction:最终,基准值加上所有特征的增减,得出了最终的预测值 0.341(标准化后的价格)。
通过这种方式,我们不仅得到了一个预测数字,还得到了一个完整的故事。
14.4.2 SHAP 值
细心的读者可能发现了一个问题:顺序重要吗?
在 Break Down 中,我们是按照某种顺序(比如先替换 rm,再替换 lstat)进行计算的。但是,如果特征之间存在相关性(例如房间数多往往意味着富人区),那么谁先被替换,谁就会“抢占”大部分贡献。
- 如果先替换 rm,模型可能会觉得房价涨了是因为房间多。
- 如果先替换 lstat(低收入比例低),模型可能会觉得房价涨了是因为社区好。
也就是说,Break Down 的结果依赖于变量排序,这在统计学上是不稳定的。
为了解决“顺序偏见”,诺贝尔经济学奖得主 Lloyd Shapley 提出了博弈论中的解决方案:既然顺序有影响,那我们就把所有可能的顺序都算一遍,然后求平均!
- SHAP 值不仅计算 rm -> lstat 的贡献,也计算 lstat -> rm 的贡献,以及所有其他排列组合。
- 对于 \(N\) 个特征,全排列有 \(N!\) 种情况,计算量是爆炸的。
- 在实际应用中,我们通常使用蒙特卡洛采样(Sampling)或专门针对树模型的优化算法(TreeSHAP)来近似计算。
在 DALEX 中,切换这两种方法只需要修改 type 参数:
对于严谨的科研或金融合规报告,我们强烈建议使用 SHAP 值,因为它能经得起关于“公平性”的数学推敲。
另外 predict_parts 还封装了其他方法:
| 方法 | 核心逻辑 | 缺点 |
|---|---|---|
Break Down |
把预测结果拆解开,最终结果 = 基准 + A的贡献 + B的贡献… | 顺序不同结果不同 |
SHAP |
把所有可能的排列组合都算一遍,然后求平均值 | 算的慢,且通常是采样估计 |
KernelSHAP |
通过构建一个加权线性回归模型来“反推”出 SHAP 值 | 比穷举快,比贪心准,也是估计 |
Oscillations |
变量的潜力。保持其他特征不变,只改变这个特征的值,预测值会发生多大变动 | 不具备可加性 |
14.5 视觉解释
在上一节的错误分析中,我们找出了模型“认错”的图片。但更深层的问题是:模型是如何看着一张图片并做出判断的?比如说这张图

对于图像数据,像素级的“特征重要性”没有意义(我们不想知道第 3 行第 5 列的像素有多重要)。我们需要的是语义级的解释:模型是看着“耳朵”还是“背景”来判断这是一只猫的?
这需要利用深度学习特有的性质:梯度。
1. 积分梯度 (Integrated Gradients)
直接看梯度 \(\frac{\partial y}{\partial x}\) 往往是不够的,因为在深度神经网络中存在梯度饱和现象(例如 Sigmoid 函数在极值处梯度接近 0)。积分梯度 (IG) 提出了一种公理化的归因方法。它计算从基准点(通常是全黑图片)变化到当前输入图片的过程中,梯度的平均值。
\[ IG_i(x) = (x_i - x'_i) \times \int_{\alpha=0}^{1} \frac{\partial F(x' + \alpha(x-x'))}{\partial x_i} d\alpha \]
其中 \(x\) 是输入,\(x'\) 是基准(如零向量)。这就像是记录了一张图片从“无”到“有”的过程中,每个像素对分类结果的累积贡献。
2. Grad-CAM:CNN 的听诊器
在卷积神经网络(CNN)中,我们有一个更好的切入点:最后一个卷积层。这里是空间信息(Spatial Info)与语义信息(Semantic Info)的最佳平衡点。
Grad-CAM (Gradient-weighted Class Activation Mapping) 的核心逻辑是:
- 计算目标类别对最后一个卷积层特征图的梯度(关注度)。
- 利用这个梯度对特征图进行加权求和。
- 通过 ReLU 过滤掉负贡献,只保留正向激活区域。
14.5.1 实现 Grad-CAM
在 R torch 中,为了节省显存,中间层的特征图和梯度在计算完后会被立刻释放。为了实现 Grad-CAM,我们需要使用 Hook (挂钩) 技术,或者封装一个“间谍模块 (SpyModule)”来截获这些稍纵即逝的信息。
为了演示这一过程,我们将使用预训练好的 ResNet18 模型:
library(torchvision)
model <- model_resnet18(pretrained = TRUE)这个网络模型的结构如下:

第一阶段 Stem:
一个 \(7 \times 7\) 的大卷积层(Stride=2) + 一个 \(3 \times 3\) 的最大池化层(Max Pooling)。快速降低图片的分辨率(从 \(224 \times 224\) 降到 \(56 \times 56\)),同时将通道数从 3 (RGB) 升到 64。
第二阶段 Layer 1-4:
ResNet18 的核心,由 4 个“层级”(Layer)组成,每个层级包含 2 个基础残差块(Basic Block)。随着层级加深,特征图(Feature Map)越来越小,但“厚度”(通道数)越来越大。
| 层级 (Layer) | 残差块数量 | 卷积核大小 | 输出尺寸 | 输出通道数 |
|---|---|---|---|---|
| Layer 1 | 2个 Blocks | 3×3 | 56×56 | 64 |
| Layer 2 | 2个 Blocks | 3×3 | 28×28 | 128 |
| Layer 3 | 2个 Blocks | 3×3 | 14×14 | 256 |
| Layer 4 | 2个 Blocks | 3×3 | 7×7 | 512 |
主干路的路径:Conv -> Batch Norm -> ReLU -> Conv -> Batch Norm,旁路有个 Skip Connection。
第三阶段 Head1:
全局平均池化 (Global Average Pooling) + 全连接层 (Fully Connected Layer)。将 \(7 \times 7 \times 512\) 的特征图压扁成 \(1 \times 1 \times 512\) 的向量,最后通过全连接层输出 1000 个分类概率(对应 ImageNet 的 1000 类)。
初始化时,它把原来的卷积层 (original_layer) 存为自己的属性。Forward (前向传播) 时,它先让数据通过原始层,得到结果 out,并存在 self$stored_features 里,然后再把 out 返回给下一层。外界看来,数据流没有任何变化,但实际上中间产生的特征图已经被我们“截获”了一份。
SpyModule <- nn_module(
"SpyModule",
initialize = function(original_layer) {
self$layer <- original_layer
self$stored_features <- NULL # 用于存储特征图
},
forward = function(x) {
# 1. 运行原始层
out <- self$layer(x)
# 2. 偷偷保存输出 (特征图)
self$stored_features <- out
return(out)
}
)接下来截获位置的定位,ResNet18 的结构很深,Grad-CAM 通常需要最后一个卷积层的特征,因为那里的语义信息最丰富(能识别出“耳朵”、“鼻子”等高级特征,而不是线条)。所以我们需要将代码定位到了 layer4 -> block 2 -> conv2。这是 ResNet18 特征提取部分的最后一站。
model <- model_resnet18(pretrained = TRUE)
model$eval()
model$to(device = device)
target_conv <- model$layer4[[2]]$children$conv2
# 创建间谍层,把原始卷积层包进去
spy_layer <- SpyModule(target_conv)
# 将间谍层塞回模型,替换掉原来的 conv2
# add_module 会用新名字覆盖旧模块
model$layer4[[2]]$add_module("conv2", spy_layer)R torch 的机制中,为了节省显存,非叶子节点(中间层)的梯度在反向传播后会被立刻释放。我们需要中间层的梯度来计算权重,所以必须显式调用 retain_grad()。
反向传播 (backward) 过程中,我们构造了一个 one_hot_output。假设模型预测是第 208 类(金毛),我们就只把第 208 个位置设为 1,其他为 0。这样反向传播回来的梯度,代表的是:“为了让‘金毛’的分数变高,这个特征图的像素该怎么变?” 这就是所谓的“关注度”。
output <- model(input_tensor)
pred_idx <- torch_argmax(output, dim = 2)$item()
cat("预测类别索引:", pred_idx, "\n")
spy_layer$stored_features$retain_grad() # 开启录像
model$zero_grad()
one_hot_output <- torch_zeros_like(output)
one_hot_output[1, pred_idx] <- 1
output$backward(gradient = one_hot_output)
features <- spy_layer$stored_features
gradients <- spy_layer$stored_features$grad
# 计算 Grad-CAM (优化归一化逻辑)
weights <- torch_mean(gradients, dim = c(3, 4), keepdim = TRUE)
cam <- torch_sum(weights * features, dim = 2, keepdim = TRUE)
# 先转为 R 的 numeric 向量,再求 range
cam_vec <- as.numeric(cam$detach()$cpu())
raw_range <- range(cam_vec)
# 应用 ReLU:负贡献(抑制)清零
cam <- nnf_relu(cam)
# 这样保留了绝对强度的概念。如果整体响应弱,图就会淡,而不是强行变红。
cam <- cam / (torch_max(cam) + 1e-8)将生成的 Grad-CAM 热力图叠加回原始图片,我们能看到令人兴奋的结果:


结果分析:
- 虽然我们在训练时只给了“类别标签”(这是狗),没有给框,但 Grad-CAM 热力图精准地覆盖了狗的头部。这证明 CNN 自发学会了物体定位。
- 对比 Layer 4 和 Layer 3 的热力图,可以清晰地看到网络越深,关注的特征越抽象、越完整。
14.6 文本解释
在训练模型时,我们通过反向传播更新权重(Weights)来最小化损失;而在模型解释时,我们将权重固定,计算输出相对于输入的梯度,以此来推断哪些输入特征最“活跃”。但对于 NLP 任务,这里存在一个数学上的阻碍。
14.6.1 原理简述
在图像识别中,输入像素是连续数值,计算 \(\frac{\partial y}{\partial <pixel>}\) 是顺理成章的。但在 NLP 中,模型的输入是单词索引(Token Indices)。
- 索引是离散整数(如 425, 998, 12…)。
- 对整数求导在数学上没有定义(不可微)。
因此,我们必须将计算层面“下沉”到 Embedding 层(词嵌入层)。Embedding 将离散的索引映射为连续的实数向量,这使得微分成为可能。
我们采用一种经典且高效的归因方法:Input \(\times\) Gradient。 对于输入序列中的第 \(i\) 个单词,其重要性分数 \(S_i\) 计算如下:
\[ S_i = \sum_{j=1}^{d} (e_{ij} \times \frac{\partial y}{\partial e_{ij}}) \]
其中:
- \(y\):模型对目标类别的预测输出(即 Logits)。
- \(e_{ij}\):第 \(i\) 个单词的词向量在第 \(j\) 维的数值。
- \(\frac{\partial y}{\partial e_{ij}}\):梯度(Gradient)。它代表了敏感度——如果该维度数值微小变化,预测结果会发生多大改变。
- \(e_{ij}\):输入值(Input)。它代表了信号强度——该特征实际存在的大小。
单纯看梯度是不够的。如果某个特征梯度很大(模型很敏感),但该特征在当前输入中是 0(或者被 ReLU 抑制),那么它实际上并没有做出贡献。将“信号强度”与“敏感度”相乘,是对特征贡献的一种一阶泰勒展开近似。
14.6.2 代码实现
我们将上述数学原理直接映射到 explain_sentiment 函数的核心代码段中。
第一步:拦截 Embedding 并开启梯度追踪。
通常 Embedding 层的梯度不需要保留,但为了解释,我们需要强制开启它。
# 手动通过 embedding 层获取词向量
embeddings <- raw_model$embedding(input_tensor) * sqrt(d_model_val)
# 告诉 Torch 我们需要对这个张量求导
embeddings$requires_grad_(TRUE)
embeddings$retain_grad()第二步:反向传播计算敏感度。
我们不是计算 Loss 的梯度,而是直接计算预测值(Logits)的梯度。这回答了:“为了增加这个预测得分,Embedding 需要怎么变?”
logits$backward()
gradients <- embeddings$grad # 获取 ∂y / ∂e点积与聚合 (The Attribution Step),这是实现公式 \(S_i = \sum (e \times \nabla e)\) 的地方。
# embeddings * gradients : 对应元素相乘 (Input * Gradient)
# dim = 3 : 在词向量维度 (embedding_dim) 上求和
attributions <- torch_sum(embeddings * gradients, dim = 3)$squeeze(1)- 输入维度:
[Batch, Seq_Len, Embed_Dim] - 点积操作得到同维度的张量,表示每个维度的独立贡献。
- 我们需要的是“这个词”的重要性,而不是“这个词的第 5 个向量维度”的重要性。因此,我们在
Embed_Dim (dim=3)上进行求和,将多维向量的贡献压缩为一个标量分数。
最终得到的 attributions 分数含义如下:
- 正分,该词正向推动了当前的预测结果。
- 负分,该词在抑制当前的预测结果。
- 零分,模型认为该词对判断无关紧要(通常是停用词如 “the”, “a”)。
最后我们来看一个情感分析模型对一条影评的判断案例。
My God, this is so terrible. Didn’t they say Baobote was the bad guy? Then why did they get into his car afterward? What the heck??? Just a pure moe anime.
模型给出的情感打分为负面。为了理解模型为什么这么判断,我们计算了每个 Token 的贡献度,并绘制了如下的归因表(蓝色为正向情感,红色为负向情感):
Group 1
|
Group 2
|
Group 3
|
|||
|---|---|---|---|---|---|
| Token | Score | Token | Score | Token | Score |
| <CLS> | 0.87 | <UNK> | -0.34 | into | 8.62 |
| my | 0.16 | was | 3.37 | his | -0.46 |
| god | -1.72 | the | 0.16 | car | -5.03 |
| this | 0.06 | bad | -1.31 | afterward | 0.35 |
| is | 0.67 | guy | -0.76 | what | 0.40 |
| so | -0.38 | then | -4.90 | the | 0.23 |
| terrible | -1.50 | why | -1.17 | heck | 0.07 |
| <UNK> | -1.92 | did | 0.69 | just | -1.43 |
| they | 0.24 | they | -0.04 | a | 0.09 |
| say | -0.04 | get | 4.88 | pure | 0.29 |
这张图表为我们打开了模型的“黑盒”,揭示了一些非常有趣的细节:
模型非常敏锐地捕捉到了 “terrible” (-1.5) 和 “bad” (-1.31) 这两个明显的强负面词汇。这证明模型学到了语言中基础的情感极性。
“God” (-1.72) 在这里被赋予了极高的负面分。虽然在宗教或中性语境中 “God” 并非贬义词,但在 IMDb 影评的训练语料中,“My God” 这一搭配通常伴随着抱怨、震惊或对烂片的感叹。模型通过大量数据捕捉到了这种共现规律,从而将其标记为负面特征。“then” (-4.9) 也被赋予了负面分,这可能是因为在训练集中,“then” 通常出现在负面评论中。
比较令人惊讶的是 “into” (+8.62) 和 “car” (-5.03) 具有极高的权重,甚至超过了形容词。这可能暗示模型捕捉到了某种特定的叙事结构(例如动作描述往往伴随着某种转折)。或者,这也可能是一种“捷径学习”(Shortcut Learning)的迹象:如果在训练集中,包含 “get into” 的评论恰好大多是某种类别,模型可能会错误地过度依赖这些中性词汇。这也是解释性工具存在的最大意义——它能帮我们发现模型是否在“作弊”或关注了错误的特征,从而指导我们进一步清洗数据或优化模型。