12 GAN
“用简单的词,描述你脑海中浮现的美好事物。”
—— 《银翼杀手》 (1982)
在昏暗的房间里,测试员对里昂进行 Voight-Kampff 测试。他观察瞳孔的微小收缩,试图分辨眼前这个完美的人形生物,究竟是人类,还是人造的复制人。
12.1 什么是 GAN?
GAN(Goodfellow 等 2014) 是生成对抗网络 Generative Adversarial Networks 的英文简写。 在深度学习的发展史上,极少有模型像生成对抗网络这样引发过如此广泛而持久的震荡。它不依赖显式的概率密度建模,也无需手工设计复杂的似然函数,而是以一种近乎“博弈论式”的优雅方式,让两个神经网络在对抗中共同进化:一个负责“造假”,一个负责“识假”。这种极小极大的动态博弈,使得模型能够从无到有地学习数据分布,最终生成逼真到足以以假乱真的样本。
GAN 的魅力不仅在于它能生成图像,更在于它揭示了深度学习的一种全新可能性——模型不再只是“拟合”数据,而是能够“创造”数据。它让我们第一次意识到,神经网络可以在高维空间中塑造复杂的分布结构,甚至能在潜在空间中学会艺术风格、面部特征、纹理结构等抽象概念。然而,GAN 的训练也以“难以稳定”而闻名:梯度消失、模式崩塌、判别器过强或过弱等问题,使得它既令人着迷,又令人挠头。
本章将一个正态分布生成案例讲起,让大家理解我们在解决什么问题。再从 GAN 的数学基础出发,循序渐进地揭示其背后的博弈论思想与优化难点,并进一步引入 Wasserstein GAN(WGAN)等稳定训练的关键改进方法。最后,我们将以 DCGAN 生成动漫头像为综合案例,让读者在真实项目中体验 GAN 的创造力与挑战性。
GAN 是深度学习中最具创造性的分支之一,也是理解现代生成模型(包括扩散模型与大语言模型)不可或缺的基石。希望通过本章的学习,你不仅能掌握 GAN 的数学与工程方法,更能体会到深度学习模型在“生成”这一方向上的无限潜能。
12.1.1 分布的变换
我们先用一个很小的案例解释面临的问题是什么,尽量避免晦涩的公式和术语:
假如有一个未知的目标分布(这里为了演示,设定为 \(N(2, 1)\)),我们希望构造一个函数(生成器),能够将简单的噪声分布(如均匀分布)映射成目标分布,而不需要显式地去写出目标分布的概率密度函数。
未知分布用 torch_randn 来模拟:
get_real_data <- function(n) {
torch_randn(n, 1) * 1 + 2
}预先定义一个简单的生成器网络,它接收一个 5 维的噪声1向量 \(z\),并输出一个标量 \(x\):
Generator <- nn_module(
initialize = function() {
self$net <- nn_sequential(
nn_linear(5, 64),
nn_leaky_relu(0.2),
nn_linear(64, 1)
)
},
forward = function(x) { self$net(x) }
)比如随便给 10 个维度为 5 的均匀分布噪声向量 \(z\),我们可以通过生成器得到长度为 10 的标量 \(x\):
z <- torch_rand(10, 5)
netG <- Generator()
(x <- netG(z))Generator 网络的网络参数是随机初始化的,所以返回的 \(x\) 也都是随机的,显然不可能逼近目标分布 \(N(4, 1)\)。我们希望通过训练,更新 Generator 网络网络参数,使它能够输出的 \(x\) 越来越接近 \(N(4, 1)\)。
12.1.2 判别函数和博弈
为了这个目的,需要再构建一个判别器网络,它接收一个样本 \(x\),并输出一个标量 \(D(x)\),表示“该样本来自真实数据分布”的概率估计:
Discriminator <- nn_module(
initialize = function() {
self$net <- nn_sequential(
nn_linear(1, 64),
nn_leaky_relu(0.2),
nn_linear(64, 1)
# 依然没有 Sigmoid (LSGAN)
)
},
forward = function(x) { self$net(x) }
)
netD <- Discriminator()假如这个判别函数靠谱的话,会出现两种情况:
- 如果 \(x\) 来自真实数据分布 \(N(2, 1)\),那么 \(D(x)\) 应该接近于 1。
- 如果 \(x\) 来自生成器 \(G(z)\),那么 \(D(x)\) 应该接近于 0。
\[ D(x) \approx \begin{cases} 1, & x \sim p_{\text{data}} \\ 0, & x \sim p_g \end{cases} \]
如果使用 MSE 来衡量总体损失的话,判别器的优化目标是:
\[ L(G, D) = \frac{1}{2} \underbrace{\text{MSE} [(D(x), 1)]}_{\text{希望真数据得分是1}} + \frac{1}{2} \underbrace{\text{MSE} [(D(G(z)), 0)]}_{\text{希望假数据得分是0}} \]
R torch 使用均方误差 nn_mse_loss(也就是 \(L_2\) 范数)实现2:
real_data <- get_real_data(batch_size)
fake_data <- netG(torch_rand(batch_size, 5))
criterion <- nn_mse_loss()
a = criterion(netD(real_data), torch_ones(batch_size, 1))
b = criterion(netD(fake_data$detach()), torch_zeros(batch_size, 1))
loss_d <- (a + b)/2如果生成器已经非常厉害了,能够“骗过”判别器,这就是我们期待的情况,生成器已经完成了自身参数的更新,可以模拟未知的目标分布了,即 \(D(G(z)) \approx 1\)。也就是说生成器对应的损失函数是:
\[ L(G) = \frac{1}{2} \underbrace{\text{MSE} [(D(G(z)), 1)]}_{\text{G 希望假数据被 D 判为 1}} \]
R torch 实现就是:
loss_g <- criterion(netD(fake_data), torch_ones(batch_size, 1))生成器 \(G\) 的目的是骗过判别器 \(D\)。它希望自己生成的假数据 \(G(z)\) 输入到 \(D\) 之后,判别器给出的打分是 1(即被误认为是真的)。注意这里 \(D\) 和 \(G\) 的目标是矛盾的。\(D\) 想把假数据压向 0,\(G\) 想把假数据推向 1。两者不断交替更新参数,不断对抗,寻找纳什均衡点。
具体实现上,因为 GAN 有两个损失函数,所以不能用前几章常用的 luz 来优化。只能用原始的 SGD 来优化。
## 初始化
optG <- optim_adam(netG$parameters, lr = 0.0002, betas = c(0.5, 0.999))
optD <- optim_adam(netD$parameters, lr = 0.0002, betas = c(0.5, 0.999))
## 循环更新
optD$zero_grad(); loss_d$backward(); optD$step()
optG$zero_grad(); loss_g$backward(); optG$step()迭代完成后,生成器 \(G\) 会学习到一个映射 \(G(z) \approx p_{\text{data}}(x)\),我们只要投喂一个 5 维的均匀分布数据,即可模拟源自于真实数据分布的样本3。
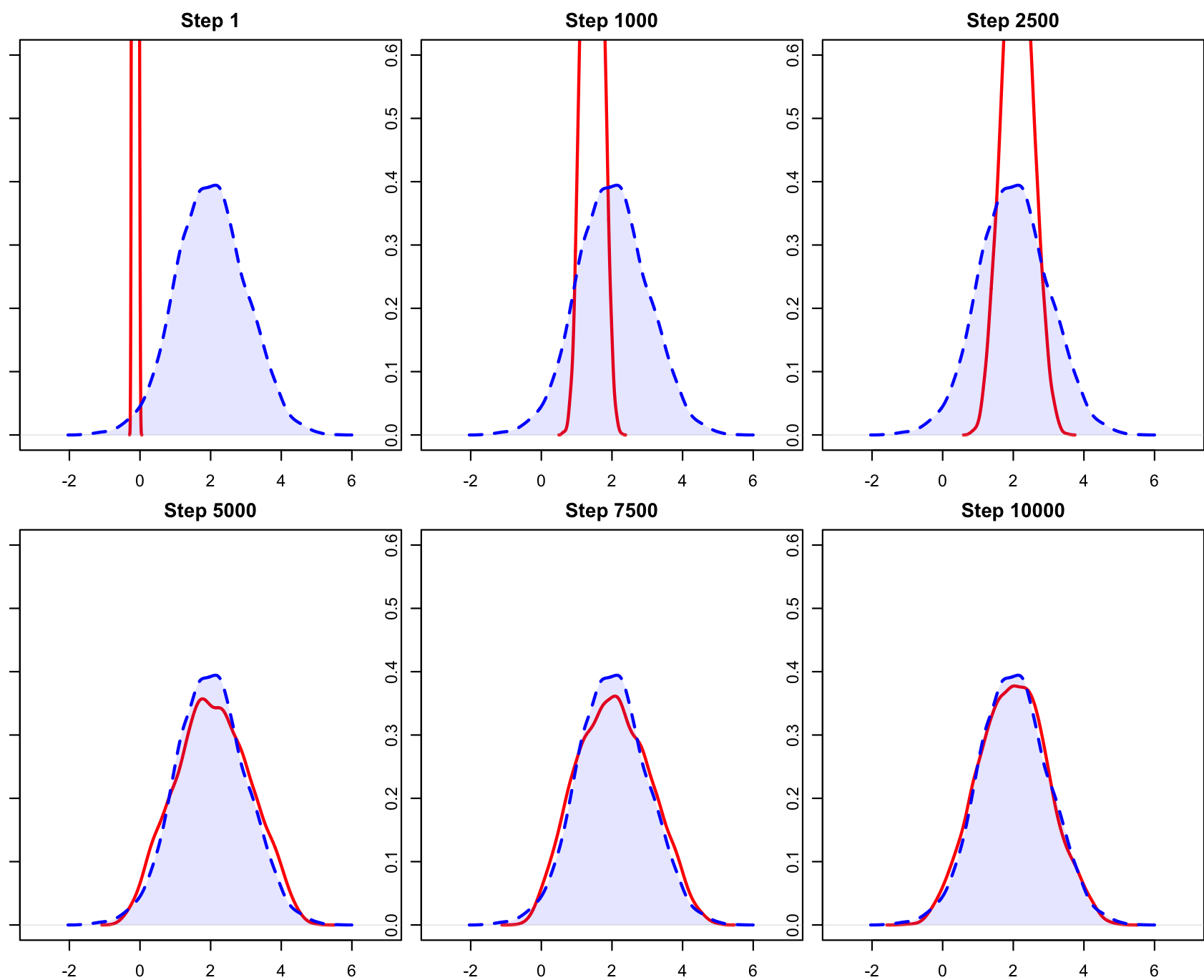
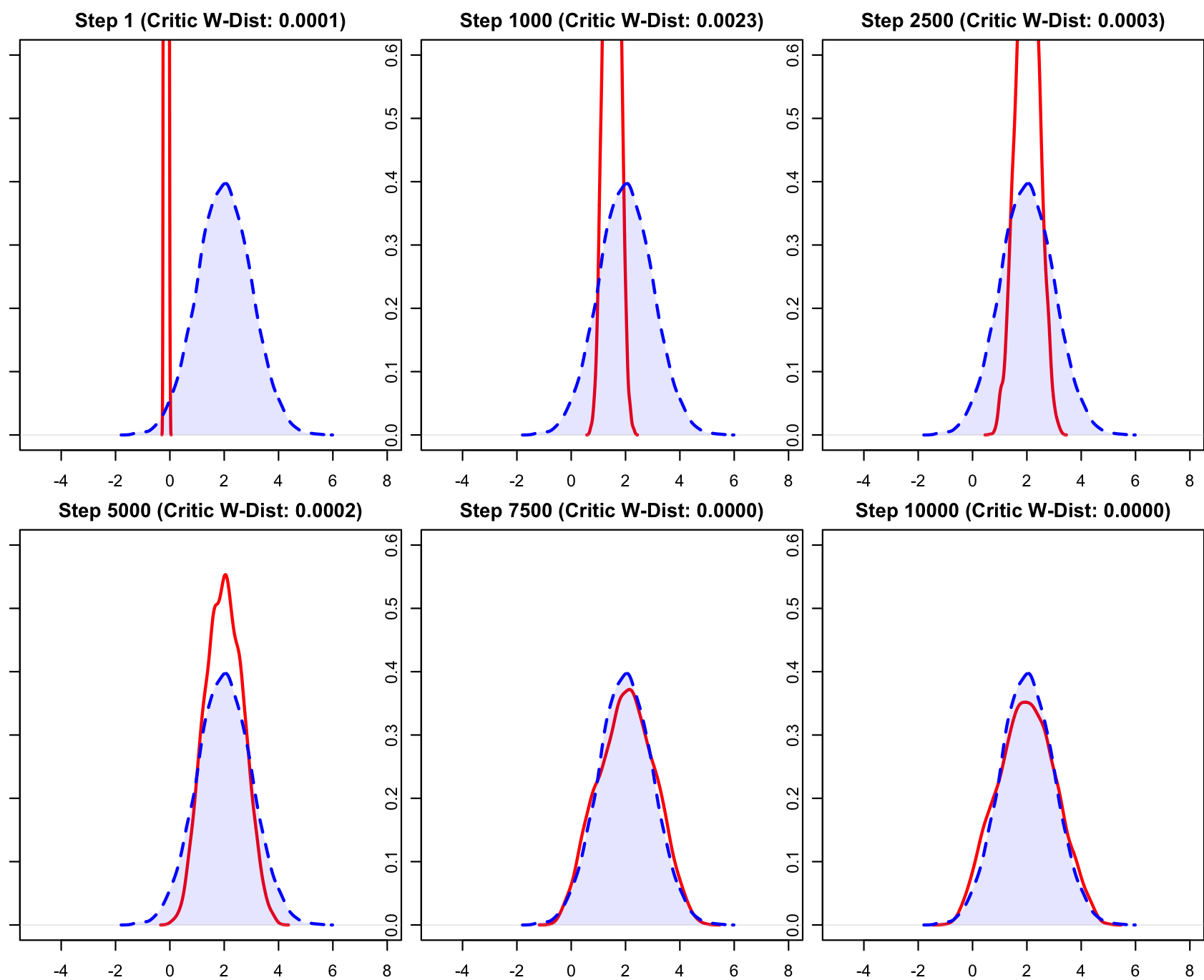
- Step 1:红线(生成数据)是一条位于 0 附近的细线,完全偏离蓝线(真实数据)。模型刚初始化,权重是随机的,生成器处于“瞎猜”阶段。
- Step 1000-2500:红线逐步移动到了 \(x=2\) 附近,方差也开始变大了。这是一个非常典型的 GAN 早期特征。生成器通过梯度下降,最先学到的是“数据在哪儿”(一阶矩/均值)。它发现只要把数据都堆在 2 附近就能骗过早期的判别器,但还没学会“数据长什么样”(二阶矩/方差)。
- Step 2500 - Step 10000:红线逐渐变宽、变矮,开始拥有了弧度。到 Step 5000 时,红线和蓝虚线已经大部分重合。到 Step 10000 时,生成器 (\(G\)) 生成的数据分布 \(P_g\) 几乎等同于真实分布 \(P_{data}\)。此时判别器已经很难区分真假。
实际上我们实现的是 LSGAN(Least Squares GAN),它的判别器最后一层没有 Sigmoid 函数。原因在于 Sigmoid 函数在两端导数趋近于 0,当生成器生成的数据“错得离谱”(outliers)时,传统 GAN 会因为梯度消失而停止学习。
如果你推导 LSGAN 的目标函数,会发现当判别器达到最优时,生成器实际上是在最小化真实分布 \(P_d\) 与生成分布 \(P_g\) 之间的 Pearson \(\chi^2\) 散度。
12.2 GAN 的数学基础
从上一节的小案例中我们看到,GAN 不直接估计数据的概率密度函数,而是采用了一种“博弈论”的视角:通过两个神经网络之间的对抗来学习数据的分布。这种设计虽然在生成质量上取得了突破性的进展,但也带来了出了名的训练不稳定性。理解这种不稳定性,必须先从它的数学定义说起。
从统计学习的角度看,生成模型的终极目标是学习一个分布 \(P_g\),使其尽可能逼近真实数据的分布 \(P_{data}\)。GAN 引入了两个核心组件:
- 生成器 (Generator, \(G\)):它的输入是随机噪声 \(z\)(通常采样自高斯分布或均匀分布),输出是生成样本 \(G(z)\)。它的目标是让 \(G(z)\) 的分布骗过判别器。
- 判别器 (Discriminator, \(D\)):它的输入是数据 \(x\),输出是一个标量概率值(0 到 1),表示 \(x\) 属于真实数据的可能性。
12.2.1 极小极大博弈
GAN 的训练过程可以被形式化为一个“极小极大”博弈问题(Minimax Game)。我们需要同时优化 \(G\) 和 \(D\),但它们的目标是相反的。定义价值函数 \(V(D, G)\) 如下:
\[ \min_G \max_D V(D, G) = \mathbb{E}_{x \sim P_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim P_{z}(z)}[\log(1 - D(G(z)))] \]
对于判别器 \(D\)(最大化部分):\(D\) 希望能够精准分类。
- 当输入是真实数据 \(x\) 时,\(D(x)\) 应趋近于 1,\(\log D(x)\) 趋近于 0(最大值)。
- 当输入是生成数据 \(G(z)\) 时,\(D(G(z))\) 应趋近于 0,\(\log(1 - D(G(z)))\) 趋近于 0(最大值)。
- 因此,\(D\) 会尽力最大化上述公式。
对于生成器 \(G\)(最小化部分):\(G\) 希望欺骗 \(D\)。
- \(G\) 无法控制第一项(因为它只与真实数据有关)。
- \(G\) 只能影响第二项。它希望 \(D(G(z))\) 趋近于 1(即让判别器误以为它是真的),从而使 \(\log(1 - D(G(z)))\) 趋向于负无穷(最小值)。
- 因此,\(G\) 会尽力最小化上述公式。
在实际的 torch 代码实现中,我们通常采用交替训练的方式:固定 \(G\) 训练 \(D\),然后固定 \(D\) 训练 \(G\)。
在博弈论中,纳什均衡指的是这样一种状态:在所有其他参与者不改变策略的前提下,任何单个参与者都无法通过改变自己的策略来获得更大的收益。
对于 GAN 而言,理论上的纳什均衡发生在以下情况:
- 生成分布拟合完美:\(P_g = P_{data}\)。此时生成器产生的数据在统计规律上与真实数据完全一致。
- 判别器失效:由于真假数据分布重合,判别器无法区分,对于任何输入 \(x\),都有 \(D(x) = \frac{1}{2}\)(即乱猜)。
Ian Goodfellow 在其原始论文中证明了,当且仅当 \(P_g = P_{data}\) 时,博弈达到全局最优解。这在数学上是优雅的,但在工程实践中,达到这个均衡点极其困难。
12.2.2 训练不稳定的根源
GAN 经常出现训练发散、梯度消失或“模式崩塌”(Mode Collapse),这与选用的损失函数有关。如果我们将判别器 \(D\) 训练到最优(即针对当前的 \(G\), \(D\) 能完美区分真假),此时再来观察 \(G\) 的目标函数,会发现 \(G\) 实质上是在最小化 \(P_{data}\) 和 \(P_g\) 之间的 Jensen-Shannon (JS) 散度4。
\[ JS(P_{data} || P_g) = \frac{1}{2} KL(P_{data} || \frac{P_{data}+P_g}{2}) + \frac{1}{2} KL(P_g || \frac{P_{data}+P_g}{2}) \]
# 计算 KL 散度 (离散近似)
calc_kl <- function(p, q) {
epsilon <- 1e-10 # 添加微小量防止 log(0)
# 归一化确保是合法的概率分布
p <- p / sum(p)
q <- q / sum(q)
sum(p * log((p + epsilon) / (q + epsilon)))
}
# 计算 JS 散度
calc_js <- function(p, q) {
m <- 0.5 * (p + q)
0.5 * calc_kl(p, m) + 0.5 * calc_kl(q, m)
}
x_vals <- seq(-5, 15, length.out = 1000)
y_p <- dnorm(x_vals, mean = 0, sd = 0.5)
y_p <- y_p / sum(y_p)
y_q <- dnorm(x_vals, mean = 6, sd = 0.5)
y_q <- y_q / sum(y_q)
calc_js(y_p, y_q) # 约等于 log(2)KL 散度 (Kullback-Leibler Divergence) 是衡量“当我们用一个近似模型(Q)去模拟真实分布(P)时,损失了多少信息”的指标(注意它不是距离)。
如果真实情况发生了,而你的模型觉得这事“根本不可能发生”,KL 散度就会给你一个巨大的惩罚。公式里两项的含义:
\[ \text{KL散度} = \sum P(x) \cdot \log\left( \frac{P(x)}{Q(x)} \right) \]
我们可以把它拆解为:“真实发生的概率” \(\times\) “预测偏差倍数”
JS 散度作为一种距离度量,在 GAN 的训练初期有一个致命缺陷:当两个分布完全不重叠(或重叠部分可忽略)时,JS 散度是一个常数。
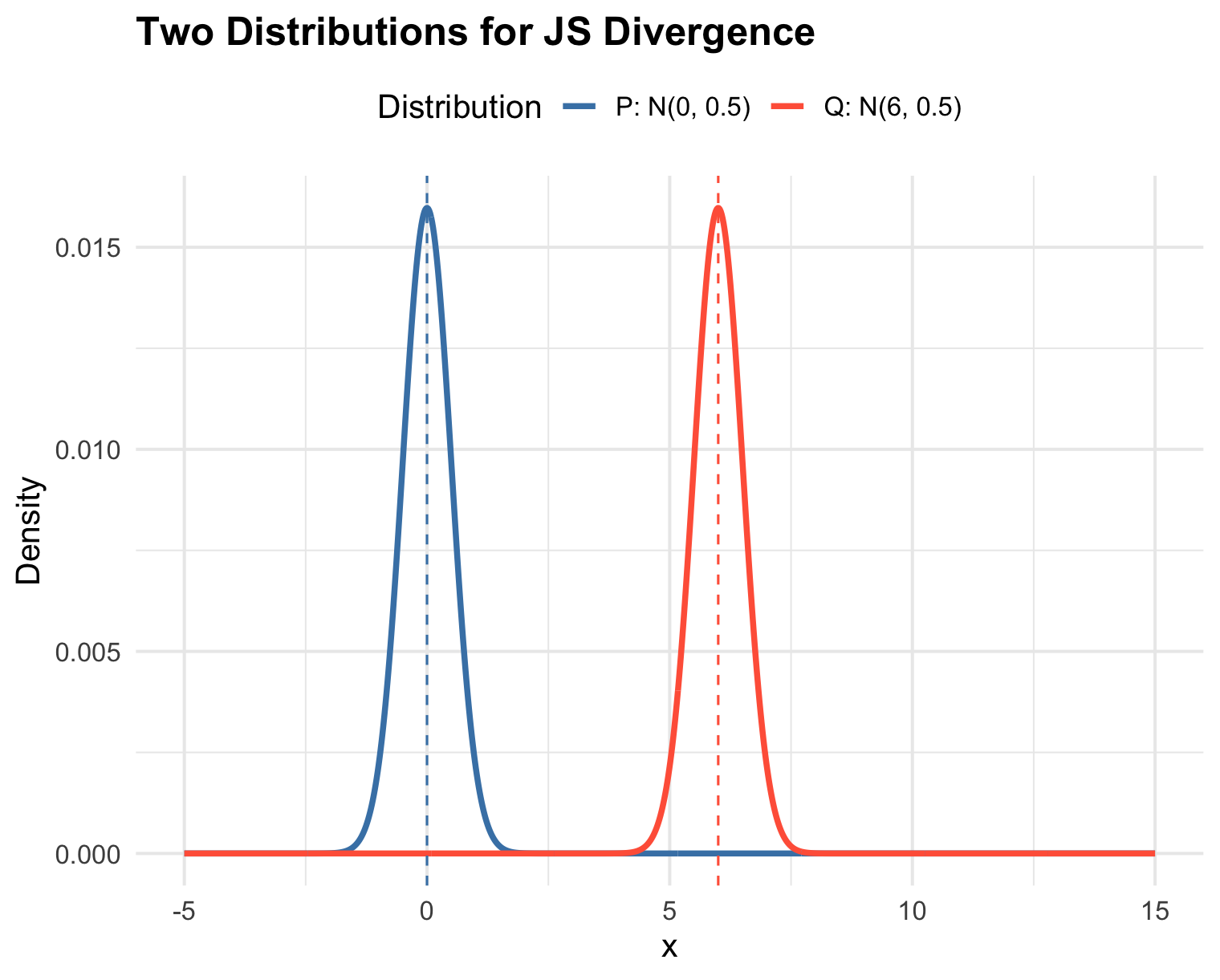
均值为 0,6,标准差为 0.5 的两个正态分布几乎没有重叠的部分,这时他们的 JS 散度值约等于 log(2)
在高维空间中(例如高清图片),生成的分布 \(P_g\) 和真实分布 \(P_{data}\) 在训练初期往往是完全不重叠的。此时,JS 散度等于 \(\log 2\)。
这意味着什么?意味着无论生成器 \(G\) 怎么微调参数,只要生成的图像依然很假(分布不重叠),损失函数的值就不变。损失函数不变,梯度就是 0。
这就是著名的 梯度消失 (Gradient Vanishing) 问题。
- 如果判别器 \(D\) 训练得太好,它能完美把 \(P_g\) 和 \(P_{data}\) 分开,导致 \(G\) 得到的梯度消失,无法学习。
- 如果判别器 \(D\) 训练得不够好,\(G\) 的梯度又是不准确的垃圾信息。
这使得 GAN 的训练变成了一种微妙的“走钢丝”:我们既需要 \(D\) 提供指导,又不能让 \(D\) 过于强大。这种内在的矛盾,正是传统 GAN 难以训练的数学根源。
为了解决这个问题,我们需要一种新的距离度量,即使在两个分布完全不重叠的情况下,也能提供有意义的梯度指引。这正是下一节我们将要介绍的 Wasserstein 距离 以及 WGAN 的核心动机。
12.3 从 GAN 到 WGAN
当生成分布与真实分布互不重叠时,JS 散度是一个常数,导致梯度消失,生成器无法获得更新方向。为了解决这一问题,2017 年 Arjovsky 等人提出了 Wasserstein GAN (WGAN)。这不仅仅是对网络结构的微调,而是从根本上替换了衡量两个分布之间距离的度量方式。
12.3.1 Wasserstein 距离
Wasserstein 距离,又被称为推土机距离 (Earth Mover’s Distance, EMD)。直观上的理解是:假设我们有两个分布 \(P\) 和 \(Q\)。我们可以把 \(P\) 想象成一堆土,把 \(Q\) 想象成我们要堆成的目标形状。Wasserstein 距离就是把土从 \(P\) 的形状移动变成 \(Q\) 的形状所需要消耗的最小“功”(即:土的质量 \(\times\) 移动距离)。
数学上的定义如下:
\[ W(P_r, P_g) = \inf_{\gamma \in \Pi(P_r, P_g)} \mathbb{E}_{(x, y) \sim \gamma} [\|x - y\|] \]
其中 \(\Pi(P_r, P_g)\) 是 \(P_r\) 和 \(P_g\) 组合起来的所有可能的联合分布集合。
统计学和计算机视觉中,一维情况下的 EMD 等同于两个分布的累积分布函数 (CDF) 之间的面积(也就是 Wasserstein-1 距离)。
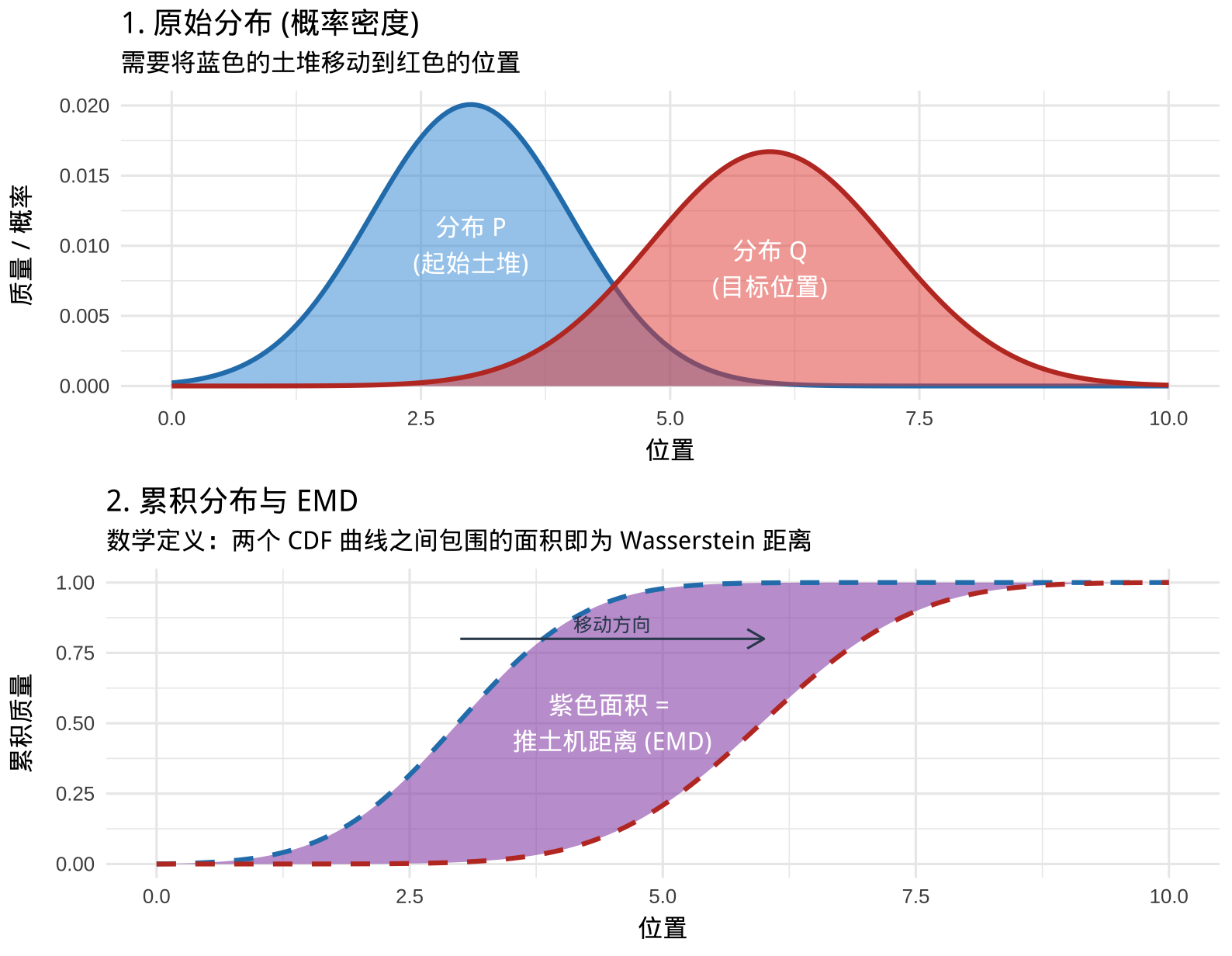
蓝色的山峰5代表当前的土堆 \(P\)。红色的山峰代表你想把土堆移到的位置 \(Q\)。推土机距离就是要把这堆蓝色的土完全铲起来,运送到红色位置并堆成那个形状所需的最小工作量(质量 \(\times\) 距离)。下图 (累积分布与面积):这是计算一维 EMD 的经典几何方法。紫色阴影区域的面积在此数学上严格等于 EMD(也称为 Wasserstein-1 距离)。
为什么它比 JS 散度更好?
让我们回到上一节提到的困境:两个分布完全不重叠。
- JS 散度:值为常数 \(\log 2\),梯度为 0。生成器不知道该往哪里挪动才能靠近真实分布。
- Wasserstein 距离:即使两个分布相距很远,距离也是线性的。例如,两个分布中心的距离是 \(d\),Wasserstein 距离通常就正比于 \(d\)。这意味着,无论生成器生成的图像有多糟糕(多偏离真实分布),Wasserstein 距离都能提供一个平滑的、非零的梯度,指引生成器向真实分布靠拢。
这种连续且几乎处处可微的特性,从理论上解决了梯度消失问题。我们也可以将本章提到的三种方式 L2(最小二乘)JS、Wasserstein 放在一起看有什么不同:
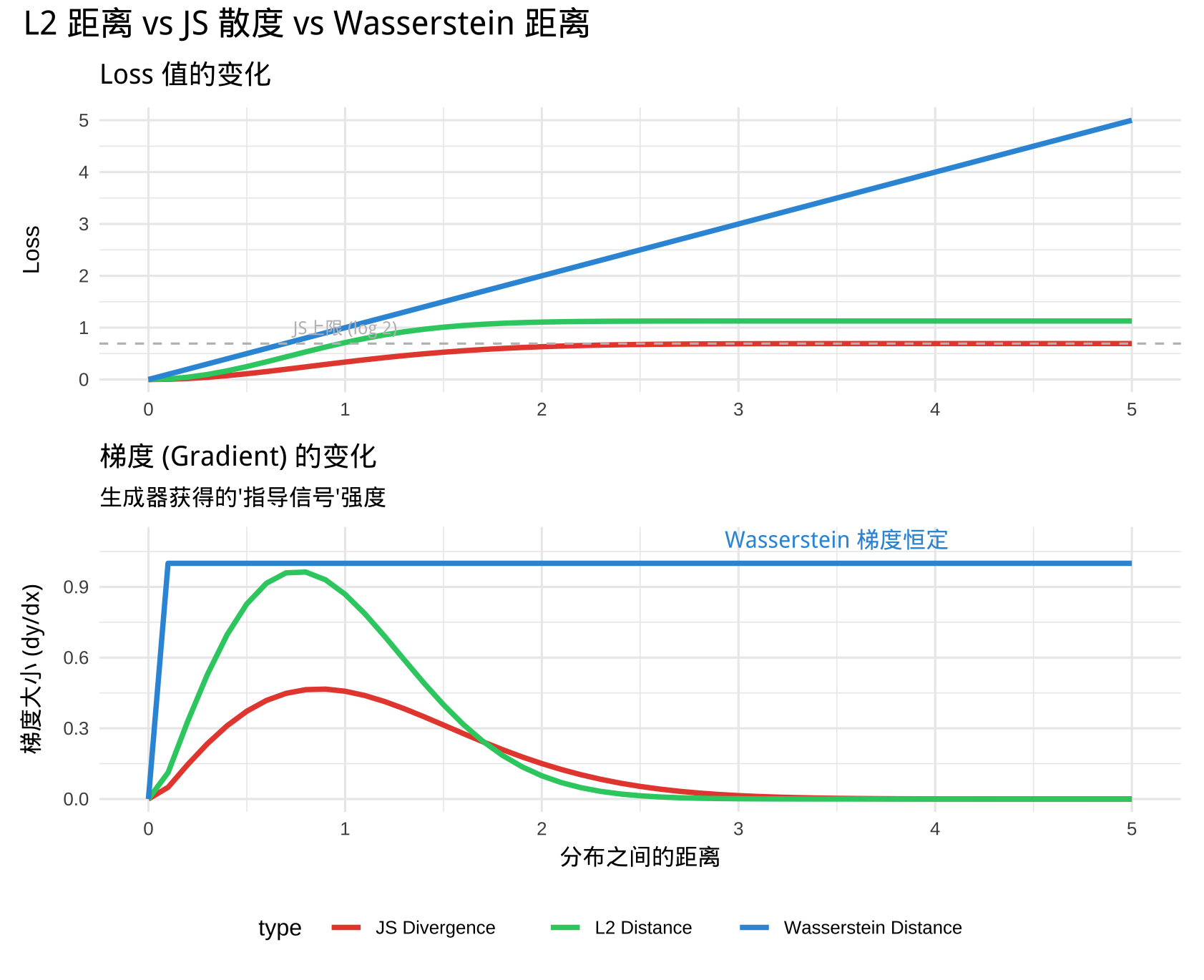
- 在 \(x > 4\) 的区域(完全分离),只有蓝色线(Wasserstein)还活着(有梯度),红色和绿色都已经“死”了(梯度为 0)。
- 虽然 L2 看起来很美好(最小二乘法很常用),但在处理概率分布的几何位移时,它比 JS 散度更早失去指导意义。
- WGAN 把衡量标准从“重叠度”(概率视角)变成了“搬运成本”(几何视角),从而彻底解决了梯度消失问题。
12.3.2 距离的对偶形式
为了求解 Wasserstein 距离,我们需要从繁琐的“运输方案”中跳出来,利用线性规划的对偶性(Duality),将其转化为一个更易求解的形式。
原始问题(怎么做最划算): 工厂要安排生产桌椅。
- 资源限制:有 100 单位木材,80 小时工时。
- 产品消耗:做一张桌子需:4 单位木材,2 小时工时。做一把椅子需:2 单位木材,4 小时工时。
- 利润:卖一张桌子赚 50 元,卖一把椅子赚 40 元。
即求解线性规划问题:
- 目标:Maximize \(Z = 50x_1 + 40x_2\)
- 约束:
- \(4x_1 + 2x_2 \le 100\)
- \(2x_1 + 4x_2 \le 80\)
对偶问题(资源值多少钱):现在假设有人要收购工厂的资源(木材和工时),你需要给资源定价。
- 目标:Minimize \(W = 100y_1 + 80y_2\)
- 约束:
- \(4y_1 + 2y_2 \ge 50\)
- \(2y_1 + 4y_2 \ge 40\)
约束的含义:如果资源的打包卖价还不如做成桌子赚得多,那我就不卖资源,直接做桌子了。
这里的资源单价(对偶变量)在经济学上被称为“影子价格” (Shadow Price)。它衡量的不是市场价,而是资源在系统内部的边际价值。
我们将这个思想应用到最优传输问题上。
原始问题 (Primal)
假设有一位大老板(Discriminator 的前身),由于数据生成器(Generator)造出的分布和真实分布不重合,他面临着把“土堆”搬运到“土坑”的任务:
- \(P_r\) (真实数据/产地):有 \(n\) 个仓库(位置 \(x_i\)),存有货物 \(a_i\)。
- \(P_g\) (生成数据/销地):有 \(m\) 个商店(位置 \(y_j\)),需求货物 \(b_j\)。
- \(C_{ij}\) (路费):从 \(x_i\) 运到 \(y_j\) 的距离(通常是欧氏距离 \(\|x_i - y_j\|\))。
需要找到一个运输方案 \(\gamma_{ij}\)(从 \(i\) 运多少到 \(j\)),把所有货物都运过去,让总运费最少。
\[ \text{Min} \sum_{i,j} \gamma_{ij} C_{ij} \]
对偶问题 (Dual)
现在,来了一个聪明的中间商(也就是 WGAN 里的 Critic)。中间商不按“路线”收费,而是搞了一套“一口价”系统:
- 收购价 \(u_i\):我在仓库 \(i\) 直接把货买走(您获得 \(u_i\))。
- 销售价 \(v_j\):我在商店 \(j\) 把货卖给您(您支付 \(v_j\))。
如果老板想把一吨货从 \(i\) 运到 \(j\):
- 自己运的成本:\(C_{ij}\)。
- 找中间商的成本:买入价 \(v_j\) - 卖出价 \(u_i\)(净支出)。
当中间商的收费 \(\le\) 自己运的成本时,可以给中间商,否则自己运(对偶约束)。
\[ v_j - u_i \le C_{ij} \]
(即:商店售价 - 仓库收购价 \(\le\) 物理距离成本)
中间商的目标中间商想赚最多的钱(最大化利润):
\[ \text{Maximize: } \underbrace{\sum_{j} b_j v_j}_{\text{在销地卖货的总收入}} - \underbrace{\sum_{i} a_i u_i}_{\text{在产地收货的总支出}} \]
合并与 Lipschitz 约束
现在我们把这个问题放到深度学习的语境下。
第一步:函数合并在 WGAN 的场景里,产地(真实样本)和销地(生成样本)都在同一个高维特征空间里。既然在同一个空间,就没必要维护两张价目表(\(u\) 和 \(v\)),我们可以定义一个通用的“价值评价函数” \(f(\cdot)\)。
令 \(v_j = f(y_j)\),令 \(u_i = f(x_i)\)。
此时,中间商的约束条件 \(v_j - u_i \le \|y_j - x_i\|\) 变成了:
\[ f(y_j) - f(x_i) \le \|y_j - x_i\| \]
即:
\[ \frac{f(y_j) - f(x_i)}{\|y_j - x_i\|} \le 1 \]
这意味着:任意两点间 \(f\) 的变化幅度(斜率),不能超过这两点间的物理距离。这就是 1-Lipschitz 连续性条件的数学定义!
第二步:最终的 WGAN 目标将 \(f\) 代回中间商的目标函数:
\[ \text{Maximize: } \sum_{j} b_j f(y_j) - \sum_{i} a_i f(x_i) \]
在深度学习中,我们处理的不是离散的仓库,而是连续的概率分布;我们不再一个个算求和,而是从分布中采样一个 Batch(比如 \(N=512\))。此时,加权求和变成了数学期望:
- \(\sum b_j f(y_j) \rightarrow \mathbb{E}_{y \sim P_g} [f(y)]\) (生成数据的平均得分)
- \(\sum a_i f(x_i) \rightarrow \mathbb{E}_{x \sim P_r} [f(x)]\) (真实数据的平均得分)
于是,WGAN 的 Critic (即中间商) 的终极目标就是:
\[ \max_{f: \|f\|_L \le 1} \left( \mathbb{E}_{y \sim P_g} [f(y)] - \mathbb{E}_{x \sim P_r} [f(x)] \right) \]
求解的目标变得非常简单,就是要把真实数据和生成数据的评分拉开差距。
real_data <- get_real_data(batch_size)
noise <- torch_randn(batch_size, 5) # 推荐用 randn
fake_data <- netG(noise)$detach()
d_loss <- torch_mean(netC(fake_data)) - torch_mean(netC(real_data))12.3.3 强制 Lipschitz 约束
目标有了,如何在训练神经网络时,让它满足 Lipschitz 连续性?
方案一:权重剪裁 (Weight Clipping)
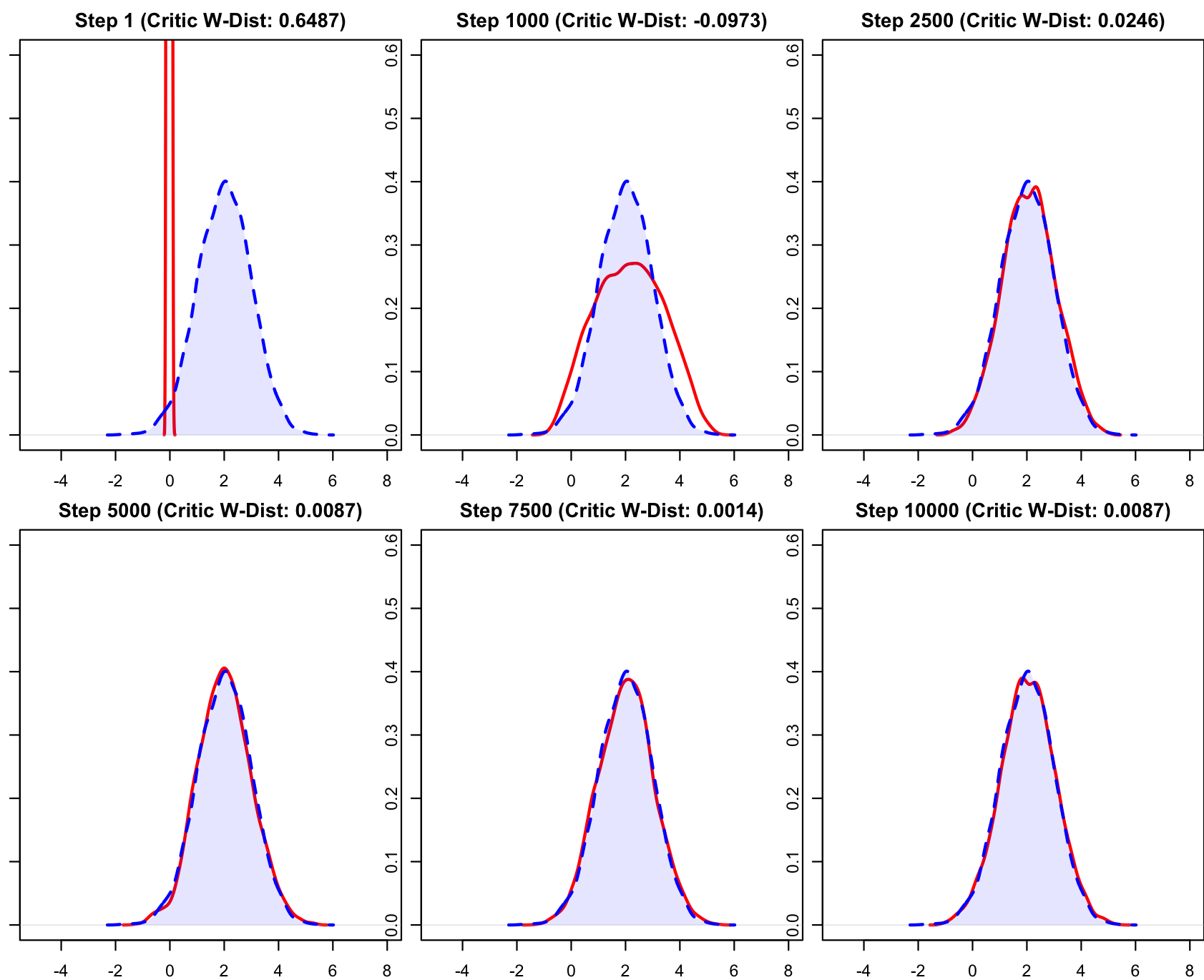
最早的 WGAN 论文采用了一种简单粗暴的方法:在每次参数更新后,强制把 Critic 的所有权重截断到 \([-c, c]\) 之间(例如 c=0.01)。在 R torch 中只需要把 Critic 更新时的所有参数强制 clamp_ 到一个范围即可。
clip_value <- 0.01
## ...
for (p in netC$parameters) {
p$data()$clamp_(-clip_value, clip_value)
}
## ...这种方法虽然能跑通,但副作用明显:容量限制:极端的参数截断限制了神经网络的表达能力。梯度问题:实验表明,经过长时间训练,权重往往会集中在 \(c\) 和 \(-c\) 两个极值上,导致梯度要么消失要么爆炸。
当然,在我们这么小的数据集上表现也还行。
方案二:梯度惩罚 (Gradient Penalty)
为了解决剪裁的问题,Gulrajani 等人提出了 WGAN-GP。他们的思路是:既然 Lipschitz 连续限制的是梯度的模长(norm),那我们直接在损失函数里对梯度的模长进行惩罚即可。
根据微分性质,一个可微函数是 1-Lipschitz 的充分必要条件是其梯度的范数处处不超过 1。WGAN-GP 引入了一个软约束:
\[ L = \underbrace{\mathbb{E}[D(G(z))] - \mathbb{E}[D(x)]}_{\text{原始 WGAN 损失}} + \underbrace{\lambda \mathbb{E}_{\hat{x}} [(\|\nabla_{\hat{x}} D(\hat{x})\|_2 - 1)^2]}_{\text{梯度惩罚项}} \]
其中:\(\hat{x}\) 是真实数据 \(x\) 和生成数据 \(G(z)\) 之间的随机插值点。\(\lambda\) 是惩罚系数,通常设为 10。
calc_gradient_penalty <- function(netC, real_data, fake_data) {
alpha_dims <- c(batch_size, rep(1, length(real_data$shape) - 1))
alpha <- torch_rand(alpha_dims, device = real_data$device)
interpolates <- (alpha * real_data + (1 - alpha) * fake_data)$requires_grad_(TRUE)
d_interpolates <- netC(interpolates)
fake <- torch_ones_like(d_interpolates)
gradients <- autograd_grad(
outputs = d_interpolates,
inputs = interpolates,
grad_outputs = fake,
create_graph = TRUE,
retain_graph = TRUE,
)[[1]]
gradients <- gradients$view(c(batch_size, -1))
gradients_norm <- gradients$norm(2, dim = 2)
gradient_penalty <- ((gradients_norm - 1)^2)$mean()
return(gradient_penalty)
}定义函数之后,在迭代过程 loss 需要增加这个 penalty,其余步骤完全一样。
在原论文建议的 \(\lambda=10\) 是针对高维图像数据的。在高维空间中,Critic 需要维持复杂的 Lipschitz 约束,且生成分布(Fake)和真实分布(Real)在早期往往在高维空间中互不重叠,中间的插值区域非常广阔。我们的这个小案例仅仅是一个 1d 空间,当 \(\lambda=10\) 时,梯度惩罚项在总 Loss 中占据了绝对主导地位。会消耗绝大部分的学习能力去“修整”梯度的模长,而忽略了最大化 Wasserstein 距离这一关键任务。
lambda_gp <- 0.1
gradient_penalty <- calc_gradient_penalty(netC, real_data, fake_data)
d_loss <- d_loss_original + (lambda_gp * gradient_penalty)WGAN-GP 是目前训练 GAN 最稳定的基准方案之一。它允许 Critic 学习更复杂的特征,同时保持了 Wasserstein 距离带来的训练稳定性。
12.4 动漫头像的生成
在本节中,我们将利用 R torch 实现一个完整的深度卷积生成对抗网络(DCGAN)。我们将使用一个动漫头像数据集作为训练目标,通过代码演示从数据加载、网络构建到训练循环的完整流程。
DCGAN (Deep Convolutional GAN) 由 Alec Radford 等人在 2015 年提出,它首次将卷积神经网络(CNN)成功应用于 GAN 的架构中,并提出了一系列对于维持训练稳定性至关重要的架构规范。
虽然经典的 DCGAN 定义了基本的卷积架构,但原始的 GAN 损失函数(JS 散度)容易导致训练不稳定和模式崩溃。因此,我们将采用上一小节介绍的拥有极高训练稳定性的 WGAN-GP方案。
12.4.1 参数与数据加载
WGAN-GP 对超参数极其敏感。与普通 GAN 不同,我们需要较低的学习率,并将 Adam 优化器的 \(\beta_1\) 设为 0。此外,为了满足 Lipschitz 约束,判别器的更新频率通常要高于生成器。
以下是经过验证的配置参数:
library(torch)
library(torchvision)
# --- 1. 配置参数 (WGAN-GP 专用配置) ---
opt <- list(
dataroot = "path/to/AnimeFaces", # 请替换为实际路径
workers = 0, # 调试建议设为 0,生产环境可增加
batch_size = 64, # WGAN 建议保持较小 Batch
image_size = 64,
nz = 100, # 噪声维度 (Latent Vector)
ngf = 64, # 生成器特征图基础深度
ndf = 64, # 判别器特征图基础深度
num_epochs = 40,
lr = 0.0001, # 学习率较低
beta1 = 0.0, # 关键:WGAN 的 Adam beta1 设为 0
beta2 = 0.9,
n_critic = 5, # 关键:判别器每轮训练 5 次,生成器训练 1 次
lambda_gp = 10 # 梯度惩罚系数
)设备选择优先支持 MPS (Apple Silicon) 和 CUDA,最以后是 CPU。
关于 ngf 和 ndf,全称是 Number of Generator(Discriminator) Filters,以 ngf 举例:
- 决定了每一层有多厚,即多少个通道/特征图。
- 比如,第一层是 ndf*8,那就是 512 层。
- 每一层都会负责绘制某种特征,比如有个眼睛,有个纹理,光线朝下等
- 最后将通道数变为 3,即我们肉眼能理解的彩色照片。
ndf 类似,不过是反向操作,左右返回概率。
device <- if (torch_is_installed()) {
if (torch_device("mps")$type == "mps") torch_device("mps")
else if (cuda_is_available()) torch_device("cuda")
else torch_device("cpu")
} else {
torch_device("cpu")
}
cat("Using device:", device$type, "\n")数据预处理遵循 DCGAN 标准:将图像 Resize 并 CenterCrop 到 64x64,并归一化到 [-1, 1] 区间。
# --- 2. 数据管道 ---
transforms <- function(img) {
img %>%
torchvision::transform_to_tensor() %>%
torchvision::transform_resize(opt$image_size) %>%
torchvision::transform_center_crop(opt$image_size) %>%
torchvision::transform_normalize(mean = c(0.5, 0.5, 0.5),
std = c(0.5, 0.5, 0.5))
}
dataset <- image_folder_dataset(root = opt$dataroot,
transform = transforms)
dataloader <- dataloader(
dataset,
batch_size = opt$batch_size,
shuffle = TRUE,
num_workers = opt$workers,
drop_last = TRUE
)12.4.2 模型定义
权重初始化
我们将沿用 DCGAN 的初始化策略,对卷积层使用正态分布初始化(std=0.02)。
weights_init <- function(m) {
classname <- class(m)[1]
if (grepl("conv", classname, ignore.case = TRUE)) {
nn_init_normal_(m$weight, mean = 0.0, std = 0.02)
} else if (grepl("batch_norm", classname, ignore.case = TRUE)) {
nn_init_normal_(m$weight, mean = 1.0, std = 0.02)
nn_init_constant_(m$bias, val = 0)
}
}生成器 (Generator)
生成器负责将 \(1 \times 1 \times 100\) 的噪声向量通过转置卷积(Transposed Conv)逐步放大为 \(64 \times 64\) 的图像。每一层后接 BatchNorm 和 ReLU,输出层使用 Tanh。
Generator <- nn_module(
"Generator",
initialize = function(nz, ngf) {
self$main <- nn_sequential(
# 输入: nz x 1 x 1 -> 4x4
nn_conv_transpose2d(nz, ngf * 8, 4, 1, 0, bias = FALSE),
nn_batch_norm2d(ngf * 8),
nn_relu(TRUE),
# 4x4 -> 8x8
nn_conv_transpose2d(ngf * 8, ngf * 4, 4, 2, 1, bias = FALSE),
nn_batch_norm2d(ngf * 4),
nn_relu(TRUE),
# ... (中间层省略,保持结构一致) ...
nn_conv_transpose2d(ngf * 4, ngf * 2, 4, 2, 1, bias = FALSE),
nn_batch_norm2d(ngf * 2),
nn_relu(TRUE),
nn_conv_transpose2d(ngf * 2, ngf, 4, 2, 1, bias = FALSE),
nn_batch_norm2d(ngf),
nn_relu(TRUE),
# 输出层: 64x64
nn_conv_transpose2d(ngf, 3, 4, 2, 1, bias = FALSE),
nn_tanh()
)
},
forward = function(input) self$main(input)
)在这个 nn_sequential 序列中,每一个模块(Block)通常由以下三个部分组成(除了输出层):
nn_conv_transpose2d:转置卷积层,是生成器的“引擎”。普通卷积是将图片变小(提取特征),而转置卷积是将特征图(Feature Map)放大(Upsampling)。kernel_size = 4, stride = 2, padding = 1是一个经典的配置,用于将特征图的长宽正好扩大 2 倍。nn_batch_norm2d:批归一化层,用于稳定训练,防止梯度消失或爆炸。在卷积层中设置了bias = FALSE,是因为 Batch Norm 层已经包含了一个偏置项(beta),如果卷积层再加 bias 就多余了。nn_relu:激活函数,以防止梯度饱和。
假设输入的随机噪声向量 nz 维度为 \(100\),基础滤波器数量 ngf 为 \(64\)。输入数据的形状通常被视为 \((N, nz, 1, 1)\)。
输入和输入尺寸为 Channels × H × W
| 操作 | 输入尺寸 | 输出尺寸 | 作用 |
|---|---|---|---|
| Project & Reshape | 100×1×1 | 512×4×4 | 将一维噪声投影并重塑为 4×4 的特征块。 |
| Upsample ×2 | 512×4×4 | 256×8×8 | 通道数(512→256),特征图长宽翻倍(4→8)。 |
| Upsample ×2 | 256×8×8 | 128×16×16 | 通道数减半,长宽翻倍。 |
| Upsample ×2 | 128×16×16 | 64×32×32 | 通道数减半,长宽翻倍。 |
| To RGB | 64×32×32 | 3×64×64 | 还原为 RGB 3 通道图像,长宽达到目标 64×64。 |
最后一步用 Tanh 可以让输出的数据分布更加中心化和标准化,这与将训练图片预处理归一化到 \([-1, 1]\) 区间是相呼应的,有助于判别器(Discriminator)的学习。
判别器 (Critic) 的特殊设计
在 WGAN-GP 中,判别器严禁使用 Batch Normalization,因为 BN 会破坏样本之间的独立性,导致梯度惩罚计算失效。此外,我们在每一层使用 LeakyReLU 并在最后移除了 Sigmoid 激活函数,因为 Critic 输出的是无界的 Wasserstein 距离评分,而非概率。
整体结构直观上像个倒金字塔,它将一张 \(64 \times 64\) 的 RGB 图片不断压缩,直到提取出一个数值。
Discriminator <- nn_module(
"Discriminator",
initialize = function(ndf) {
self$main <- nn_sequential(
# 第 1 层 (无 BN)
nn_conv2d(3, ndf, 4, 2, 1, bias = FALSE),
nn_leaky_relu(0.2, inplace = TRUE),
# 第 2-4 层 (移除 GroupNorm/BatchNorm 以兼容 MPS 并满足 GP 要求)
nn_conv2d(ndf, ndf * 2, 4, 2, 1, bias = FALSE),
nn_leaky_relu(0.2, inplace = TRUE),
nn_conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias = FALSE),
nn_leaky_relu(0.2, inplace = TRUE),
nn_conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias = FALSE),
nn_leaky_relu(0.2, inplace = TRUE),
# 输出层: 输出标量分数,不接 Sigmoid
nn_conv2d(ndf * 8, 1, 4, 1, 0, bias = FALSE)
)
},
forward = function(input) self$main(input)
)梯度惩罚 (Gradient Penalty)
为了满足 1-Lipschitz 连续性约束,我们需要计算梯度惩罚。这部分是 WGAN-GP 的数学核心。
compute_gradient_penalty <- function(netD, real_samples, fake_samples, device) {
# 1. 随机插值
alpha <- torch_rand(c(real_samples$size(1), 1, 1, 1), device = device)
interpolates <- (alpha * real_samples + (1 - alpha) * fake_samples)$requires_grad_(TRUE)
# 2. 计算插值图的判别分数
d_interpolates <- netD(interpolates)
# 3. 计算梯度 (相对于输入图像)
fake_grad <- torch_ones(d_interpolates$shape, device = device)
gradients <- autograd_grad(
outputs = d_interpolates,
inputs = interpolates,
grad_outputs = fake_grad,
create_graph = TRUE,
retain_graph = TRUE
)[[1]]
# 4. 计算惩罚项: (||\nabla D||_2 - 1)^2
gradients <- gradients$view(c(gradients$size(1), -1))
gradient_penalty <- ((gradients$norm(2, dim = 2) - 1) ^ 2)$mean() * opt$lambda_gp
return(gradient_penalty)
}12.4.3 训练循环
训练过程采用了嵌套循环结构。对于每个 batch 的生成器更新,判别器需要先行训练 n_critic (默认为 5) 次。
# 初始化
netG <- Generator(opt$nz, opt$ngf)$to(device = device)
netD <- Discriminator(opt$ndf)$to(device = device)
netG$apply(weights_init); netD$apply(weights_init)
optimizerD <- optim_adam(netD$parameters,
lr = opt$lr, betas = c(opt$beta1, opt$beta2))
optimizerG <- optim_adam(netG$parameters,
lr = opt$lr, betas = c(opt$beta1, opt$beta2))
fixed_noise <- torch_randn(64, opt$nz, 1, 1, device = device)
cat("Starting WGAN-GP Training...\n")
for (epoch in 1:opt$num_epochs) {
iter_loader <- dataloader$.iter()
i <- 0
while(TRUE) {
i <- i + 1
# --- (1) 判别器训练循环 (n_critic 次) ---
critic_loop_break <- FALSE
for (nc in 1:opt$n_critic) {
batch <- iter_loader$.next()
if (coro::is_exhausted(batch)) { critic_loop_break <- TRUE; break }
real_imgs <- batch[[1]]$to(device = device)
netD$zero_grad()
# 真实样本得分 (试图最大化,Loss取负)
output_real <- netD(real_imgs)$view(-1)
loss_real <- -torch_mean(output_real)
# 假样本得分
noise <- torch_randn(real_imgs$size(1),
opt$nz, 1, 1, device = device)
fake_imgs <- netG(noise)$detach() # Detach 避免梯度传回 G
output_fake <- netD(fake_imgs)$view(-1)
loss_fake <- torch_mean(output_fake)
# 梯度惩罚
gp <- compute_gradient_penalty(netD,
real_imgs, fake_imgs, device)
# Critic 总 Loss: D(fake) - D(real) + GP
loss_D <- loss_real + loss_fake + gp
loss_D$backward()
optimizerD$step()
}
if (critic_loop_break) break
# --- (2) 生成器训练循环 ---
netG$zero_grad()
noise <- torch_randn(opt$batch_size, opt$nz, 1, 1, device = device)
fake_imgs_g <- netG(noise)
output <- netD(fake_imgs_g)$view(-1)
# Generator Loss: -D(fake) (试图让 Critic 打高分)
loss_G <- -torch_mean(output)
loss_G$backward()
optimizerG$step()
if (i %% 50 == 0) {
cat(sprintf("[%d/%d] Loss_D: %.4f Loss_G: %.4f\n",
epoch, opt$num_epochs, loss_D$item(), loss_G$item()))
}
}
# --- 结果可视化 ---
with_no_grad({
fake_check <- netG(fixed_noise)
grid <- vision_make_grid(fake_check, scale = TRUE, nrow = 8, padding = 2)
# 此处可添加保存 grid 到 png 的代码
})
}通过本节的代码,我们实现了一个工业级强度的 WGAN-GP 模型。与标准 DCGAN 相比,这个实现最大的区别在于:
- Loss 函数:直接最大化真假样本的得分差,而非分类概率。
- 网络结构:判别器移除了 BatchNorm,保证了梯度惩罚的数学有效性。
- 训练动态:判别器训练得比生成器更多,这在 WGAN 理论中是必要的,以保证 Critic 能提供准确的梯度方向。
迭代 40 轮,我们抽取了其中的一些轮次,看同样的参数下生成图片的变化情况:

12.5 GAN 演进方向
GAN 的演进主要沿着两条主线进行:稳定性改进与条件可控性增强。
架构优化 (DCGAN & StyleGAN): DCGAN(第 4 节已实践)确立了卷积网络在生成任务中的地位。随后,NVIDIA 提出的 StyleGAN 系列通过引入“风格”控制和多尺度渐进式训练,实现了极高分辨率(如 1024x1024)的人脸生成,彻底解决了早期 GAN 图像模糊的问题。
目标函数改良 (WGAN & WGAN-GP): 正如我们在第 2 节讨论的,WGAN 通过引入 Wasserstein 距离解决了传统 GAN 训练中梯度消失和模式崩塌(Mode Collapse)的数学根源。目前,WGAN-GP(带梯度惩罚的 WGAN)已成为许多生成任务的默认起点。
从无监督到有监督 (Conditional GAN): 原生 GAN 无法控制生成的类别。Conditional GAN (cGAN) 通过在生成器和判别器中同时输入类别标签,实现了指定目标的生成(例如:指定生成“数字 5”)。
跨域转换 (CycleGAN): 这是 R 用户在风格迁移中常用的模型。它不需要成对的数据集(例如:不需要同一张照片的油画版和实拍版),仅通过循环一致性损失(Cycle Consistency Loss)即可实现“马变斑马”或“卫星图转地图”的转换。