| 词语对 | 实际关系 | 趋势 |
|---|---|---|
| amazing-bad | 相反 | 下降 |
| amazing-excellent | 相似 | 上升 |
| amazing-terrible | 相反 | 下降 |
| bad-excellent | 相反 | 下降 |
| terrible-bad | 相似 | 上升 |
| terrible-excellent | 相反 | 下降 |
8 循环网络
“我必须相信,当我闭上眼睛时,世界依然存在。”
—— 《记忆碎片》 (2000)
8.1 序列建模与 RNN
在深入张量维度的工程细节之前,我们必须先回答一个直击灵魂的问题:既然统计学界早有极其成熟的 ARIMA、GARCH 模型来预测金融与经济走势,机器学习界也有 XGBoost 和 Prophet,我们为什么还要费时费力去了解甚至训练一个极难调参的循环神经网络?
答案在于,当面对真正的序列数据时,传统模型面临着难以逾越的物理限制:
- 经典的 ARIMA 极其优雅,但高度依赖线性假设和数据平稳性。现实世界中,气温的剧变、金融市场的恐慌抛售往往是高度非线性的。一旦面对多变量输入(如同时利用温度、气压、风速进行联合预测),传统模型极易陷入维度灾难。
- XGBoost 预测能力极强,但它天生没有“时间流动”的概念。为了让其处理时间序列,工程师必须手动提取海量的滞后特征(如
lag_1)和滚动统计量(如rolling_mean_7d)。在 XGBoost 的视角里,昨天的数据和前天的数据就像“身高”和“体重”一样,被粗暴地扁平化为相互独立的静态列,时间轴上的因果递进关系被彻底割裂。
RNN 的革命性突破,就是将处理时间的范式从“人工展开特征”变成了“模型内部维持记忆”。只要数据点之间存在严格的先后顺序,无论它是连续的数值(如气温、股价),还是离散的符号(如文本、代码),都属于 RNN 的覆盖范围。
循环神经网络(RNN)的革命性突破在于引入了隐状态(Hidden State)。不仅当前的输入 \(x_t\) 决定输出,上一个时刻的隐状态 \(h_{t-1}\) 也参与当前的计算。这种结构使得信息能够在时间维度上流动,仿佛网络拥有了“短期记忆”。
8.1.1 RNN 架构及定义
假设我们有一个输入序列 \(X = \{x_1, x_2, ..., x_T\}\),其中 \(x_t \in \mathbb{R}^d\) 是 \(t\) 时刻的输入向量。RNN 在 \(t\) 时刻的计算可以表示为两个核心方程:
1. 状态更新方程 (The State Update Equation)
隐状态 \(h_t\) 是网络的“记忆核心”,它由当前输入 \(x_t\) 和上一时刻的隐状态 \(h_{t-1}\) 共同决定:
\[ h_t = \sigma(W_{ih} x_t + b_{ih} + W_{hh} h_{t-1} + b_{hh}) \]
其中:
- \(W_{ih}\):输入到隐藏层的权重矩阵 (Input-to-Hidden)。
- \(W_{hh}\):隐藏层到隐藏层的权重矩阵 (Hidden-to-Hidden),这是捕捉时间依赖的关键。
- \(b_{ih}, b_{hh}\):偏置项。
- \(\sigma\):激活函数,通常是 \(\tanh\) 函数,值在 (-1, 1) 之间,有助于维持梯度的稳定性。
RNN 的关键点在于参数共享(Parameter Sharing)。无论序列有多长,我们在每一个时间步(Time Step)都使用同一个 \(W_{ih}\) 和 \(W_{hh}\)(包括两个偏置项)。这是 RNN 能够泛化到不同长度序列的根本原因。
2. 输出方程 (The Output Equation)
在计算出当前的隐状态 \(h_t\) 后,我们可以计算当前时刻的输出 \(y_t\)(例如预测下一个单词的概率分布): \[ y_t = g(W_{hy} h_t + b_y) \]
最后的全连接层 \(W_{hy}\) 负责将隐藏状态映射到输出空间。其中 g 是输出层的激活函数,如分类任务中的 Softmax,或回归任务中的恒等映射(\(g=1\))。
8.1.2 按时间展开
为了直观理解上述核心方程是如何在时间轴上流动的,我们通常将 RNN 的计算图按时间展开 (Unrolling over Time)。
试想我们需要利用过去几天的数据来预测未来的一个值(典型的 Many-to-One 多对一架构)。在这个视角下,RNN 实际上等价于一个极深的神经网络,每一层代表一个时间步。在这个网络中,信息是这样流转的:
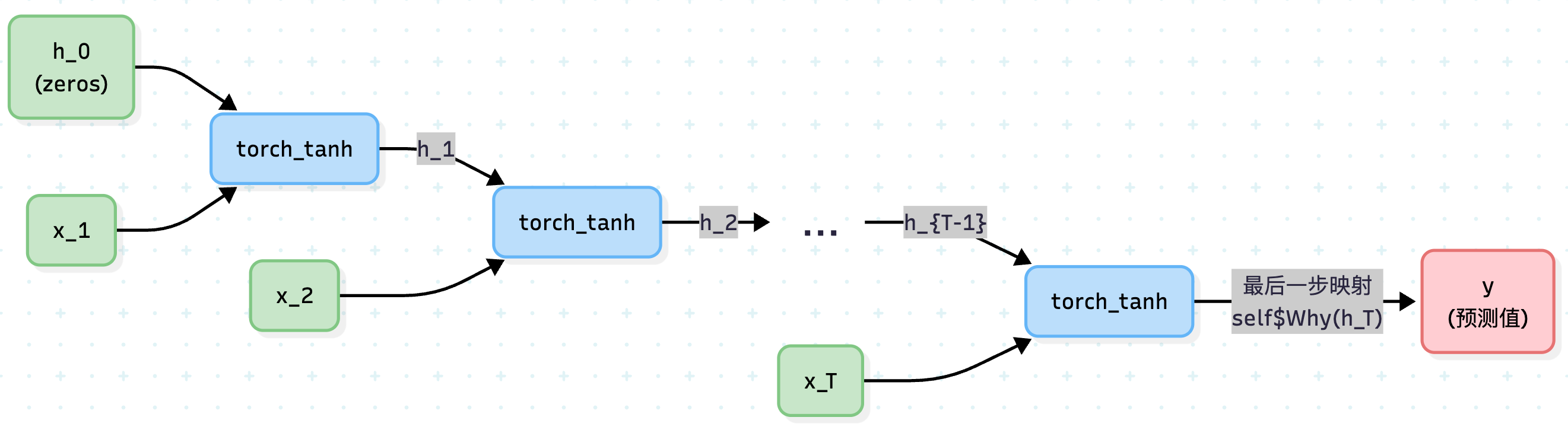
如上图所示,所有的蓝色节点 torch_tanh 在内存中其实是同一个算子。它就像一个循环吞吐的漏斗,不断把新时刻的输入 \(x_t\) 和上一个时刻的记忆 \(h_{t-1}\) 糅合在一起。直到时间轴走向终点(\(T\) 时刻),网络才将饱含整个序列信息的 \(h_T\) 释放出来,映射为最终的预测结果 \(y\)。
8.1.3 代码实现
理解了时间展开图,我们就能非常轻松地用原生的 nn_linear(全连接层)徒手实现一个 RNN:
rnn_model <- nn_module(
"rnn_model",
initialize = function(input_size, hidden_size, output_size) {
self$hidden_size <- hidden_size # 显式存下来,forward 里调用更安全
# 输入到隐藏
self$Wxh <- nn_linear(input_size, hidden_size)
# 隐藏到隐藏 (省略 bias,因为 Wxh 已经带 bias 了)
self$Whh <- nn_linear(hidden_size, hidden_size, bias = FALSE)
# 隐藏到输出
self$Why <- nn_linear(hidden_size, output_size)
},
forward = function(x) {
# x: (batch_size, time_steps, input_size)
batch_size <- x$size(1)
time_steps <- x$size(2)
# 初始化最早的隐藏状态 h_0 为全 0
h <- torch_zeros(batch_size, self$hidden_size, device = x$device)
# 关键步骤:时间步展开 (Unrolling over time)
for (t in 1:time_steps) {
xt <- x[ , t, ]
# 这里就是状态更新方程的代码具象化
h <- torch_tanh(self$Wxh(xt) + self$Whh(h))
}
# 输出方程:最后隐藏状态映射到输出
y <- self$Why(h)
return(y)
}
)从实现上我们会发现,里面有一个时间步循环,为什么叫做循环网络也是由此而来。验证一下
torch_manual_seed(42) # 设定随机数种子,保证复现结果一致
# 实例化:输入 3 维特征,隐藏层设为 10 维,最终输出 1 个预测值
model <- rnn_model(input_size = 3, hidden_size = 10, output_size = 1)
# 模拟:Batch Size = 2(两条样本),时间步 = 5(过去 5 天),输入特征 = 3
x_fake <- torch_randn(2, 5, 3)
x_fake$size() # 输入张量形状: (Batch, Time, Feature)
(y_pred <- model(x_fake))
# torch_tensor
# 0.2123
# 0.4816
# [ CPUFloatType{2,1} ][ grad_fn = <AddmmBackward0> ]你会发现,输出结果变成了一个二维张量 [2, 1]。中间那个代表时间的维度(5)消失了,因为它已经被 for 循环彻底“吃掉”并压缩进了最后的隐藏状态中。
在真正的工程实践中,为了极致的计算效率(如 GPU 算子融合),我们不需要每次都手写 for 循环。R torch 提供了底层由 C++ 高度优化的 nn_rnn API。
假设我们通过每天观测到的天气信息(温度、湿度、风速),利用过去 30 天的数据来预测下一天的温度和降水概率。我们可以直接调用官方算子:
WeatherModel <- nn_module(
"WeatherModel",
initialize = function(input_size, hidden_size, output_size) {
self$rnn <- nn_rnn(
input_size = input_size,
hidden_size = hidden_size,
batch_first = TRUE
)
self$fc <- nn_linear(hidden_size, output_size)
},
forward = function(x) {
out_list <- self$rnn(x)
# nn_rnn 返回的列表中,[[2]] 包含了最后一个时刻的隐状态 (h_T)
# 单层 RNN 形状是 (1, batch, 20),用 squeeze(1) 把它变成 (batch, 20)
last_h <- out_list[[2]]$squeeze(1)
result <- self$fc(last_h)
return(result)
}
)
# 模型实例化:输入 3 维特征,隐藏层 20 维,预测 2 个目标
model_api <- WeatherModel(input_size = 3, hidden_size = 20, output_size = 2)
names(model_api$parameters)
# [1] "rnn.weight_ih_l1" "rnn.weight_hh_l1" "rnn.bias_ih_l1"
# [4] "rnn.bias_hh_l1" "fc.weight" "fc.bias"仔细对比 names(model_api$parameters) 打印出的权重名称与公式,你会发现它们一一对应,底层数学逻辑与我们手写的版本一致。
8.1.4 糟糕的梯度问题
RNN 虽然理论上极其优雅,代码实现也十分简洁,但在早期的深度学习浪潮中,它的训练却是一场噩梦。这主要归因于梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)问题。
根据前面的“按时间展开图”,RNN 每经过一个时间步,隐状态 \(h\) 就要被同一个权重矩阵 \(W_{hh}\) 乘一次,并被激活函数挤压一次。即我们需要在这个按时间展开的“极深网络”上进行数学推导,随时间反向传播(Backpropagation Through Time, BPTT)。
损失函数的梯度计算
假设我们在最后时刻 \(T\) 有一个损失函数 \(L\),我们要计算该损失对序列起点的某个时刻 \(k\) 的隐状态 \(h_k\) 的梯度。根据链式法则:
\[ \frac{\partial L}{\partial h_k} = \frac{\partial L}{\partial h_T} \cdot \frac{\partial h_T}{\partial h_k} \]
这里最关键的一项是 \(\frac{\partial h_T}{\partial h_k}\),它代表了长期依赖的梯度传递。由于 \(h_T\) 是由 \(h_{T-1}\) 决定的,我们可以将其展开为连乘形式:
\[ \frac{\partial h_T}{\partial h_k} = \prod_{t=k+1}^T \frac{\partial h_t}{\partial h_{t-1}} \]
雅可比矩阵与特征值分析
根据状态更新方程 \(h_t = \tanh(W_{ih} x_t + W_{hh} h_{t-1})\),我们可以求出相邻时间步的偏导数(即雅可比矩阵):
\[ \frac{\partial h_t}{\partial h_{t-1}} = \text{diag}(\tanh'(a_t)) \cdot W_{hh} \]
为了简化特征值分析,我们假设激活函数是线性的,并且 \(W_{hh}\) 可以对角化分解为 \(W_{hh} = P \Lambda P^{-1}\)。那么,梯度的连乘项主要由 \(W_{hh}\) 的 \(T-k\) 次幂决定:
\[ W_{hh}^{T-k} = P \Lambda^{T-k} P^{-1} \]
这里 \(\Lambda\) 是包含 \(W_{hh}\) 特征值的对角矩阵。
- 如果 \(W_{hh}\) 的最大特征值 \(\rho < 1\),当时间步跨度 \(T-k\) 很大时,\(\Lambda^{T-k} \to 0\)。这意味着远古时刻 \(k\) 的梯度无法传递到 \(T\),网络彻底“遗忘”了长距离的依赖关系。
- 如果 \(\rho > 1\),当 \(T-k\) 很大时,\(\Lambda^{T-k} \to \infty\)。梯度呈指数级增长,导致权重更新瞬间变为 NaN(Not a Number),训练直接崩溃。
视觉化梯度悬崖
我们可以通过梯度范数(Gradient Norm)来直观地观察这一灾难。梯度范数代表了梯度向量的“总长度”,计算公式为 \(\|g\|_2 = \sqrt{\sum p_i^2}\)。
- 如果范数很大:说明梯度很强,参数更新步子大。
- 如果范数接近 0: 说明梯度消失了,模型“学不动”了。
当我们把纵坐标切换到对数标尺时,可以看到:
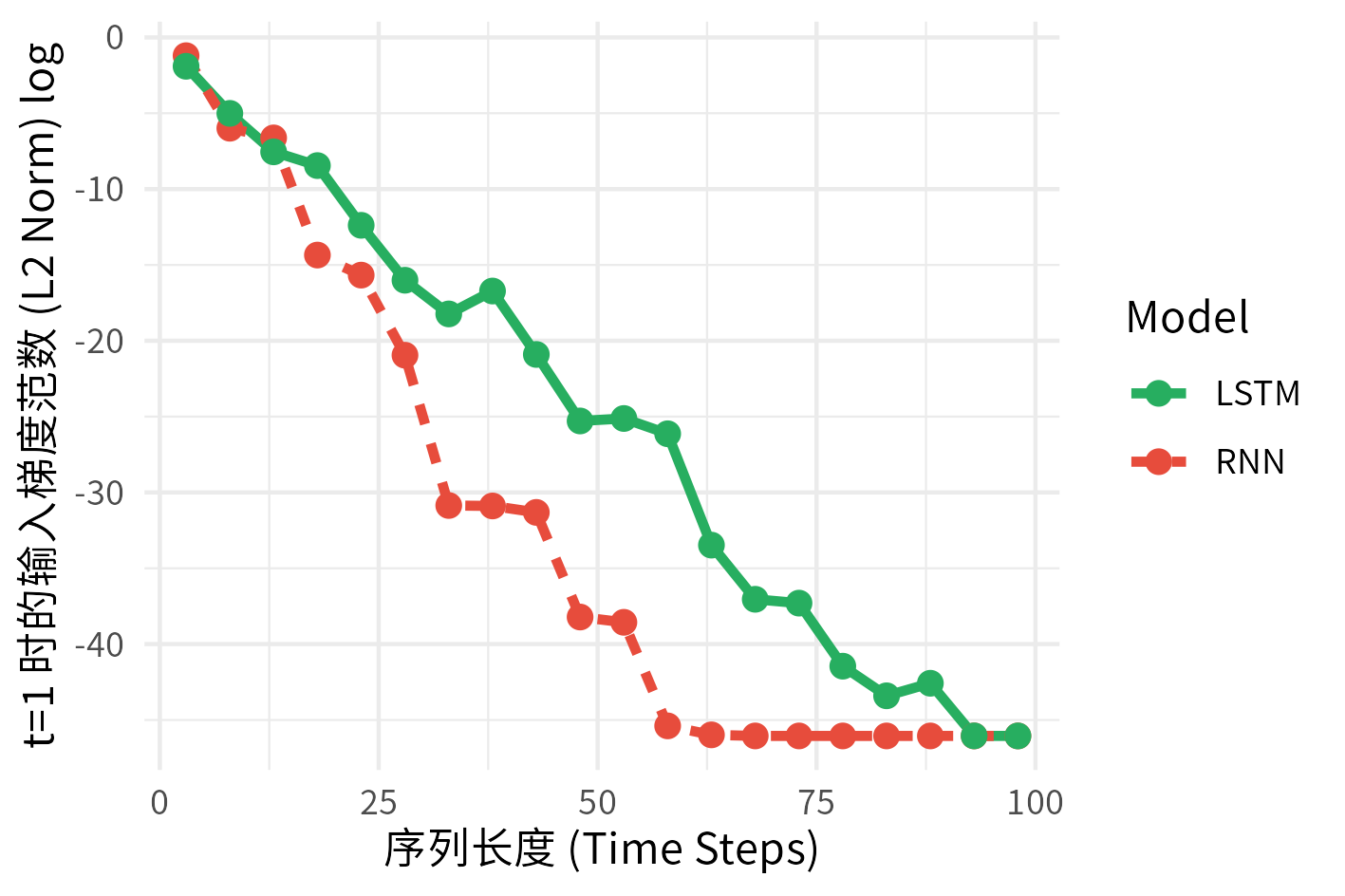
图中清晰地展示了:标准 RNN 的梯度并非缓慢减弱,而是以恒定的速率呈指数级‘坠落’,直到撞上计算机浮点数的精度地板(Underflow),形成了图中的断崖。相比之下,后文将要介绍的 LSTM 得益于特殊的机制,其梯度就像滑翔机一样,能飞越比 RNN 远得多的距离。
针对 BPTT 揭示的连乘灾难,深度学习界提出了以下几种工程与架构上的核心解决方案,这也是我们后续章节将要实践的重点:
| 问题 | 解决方案 | 原理 |
|---|---|---|
| 梯度爆炸 | 梯度裁剪 | 当梯度的范数(Norm)超过阈值时,强行将其缩放。这在 torch 中通过 nn_utils_clip_grad_norm_() 轻松实现。 |
| 梯度消失 | 门控机制 | 引入 LSTM 或 GRU。通过设计特殊的“门”结构(加法更新而非乘法更新),使得 \(\frac{\partial h_t}{\partial h_{t-1}} \approx 1\),从而让梯度能够无损地长距离传播。 |
| 激活函数 | (Leaky)ReLU | 相比 \(\tanh\),ReLU 在正区间的导数恒为 1,有助于缓解梯度消失(但需配合初始化策略防止数值溢出)。 |
注记
可以这样理解:RNN 的损失函数表面(Loss Surface)往往非常陡峭,存在像“悬崖”一样的结构。如果梯度没有裁剪,SGD 可能会迈出巨大的一步(Step size = Learning Rate * Gradient)。这一步可能直接把参数踢出“舒适区”,导致 Loss 瞬间变成 NaN 或者无穷大,之前的训练成果付诸东流。
梯度裁剪(Gradient Clipping)是一种工程上的解决方案,用于防止梯度爆炸。它的基本思想是:在反向传播过程中,计算得到的梯度向量 \(\nabla L\) 可能非常大(爆炸)或非常小(消失)。为了避免这两种情况,我们可以对梯度向量进行归一化,使其长度(范数)不超过一个预定义的阈值 \(\theta\)。
在 torch 中,我们可以使用 nn_utils_clip_grad_norm_() 函数来实现梯度裁剪,这里需要注意裁剪的函数还有一个 nn_utils_clip_grad_value_() 函数,它是简单粗暴地把每个参数的梯度限制在 \([-c, c]\) 之间,会导致向量方向的改变。
8.2 LSTM 与 GRU
在上一节中,我们推导了标准 RNN 的反向传播算法(BPTT),并从数学分析中看到了连乘项 \(\prod \frac{\partial h_t}{\partial h_{k}}\) 导致的梯度消失与爆炸问题。这在本质上限制了标准 RNN 捕捉长距离依赖(Long-Term Dependencies)的能力。
本节我们将深入探讨两种经典的变体:长短期记忆网络 (LSTM) 和 门控循环单元 (GRU)。它们引入了精巧的“门控机制” (Gating Mechanism),从根本上改变了梯度的流动方式。我们将结合 R torch 的实现,解析其背后的数学原理与张量几何。
8.2.1 LSTM
LSTM(Hochreiter 和 Schmidhuber 1997) 是 Long Short-Term Memory(长短期记忆网络)的简写,它不同于标准 RNN 只有一个简单的 \(\tanh\) 层,LSTM 引入了一个核心概念:细胞状态 (Cell State),记为 \(C_t\)。我们可以将细胞状态 \(C_t\) 想象成一条贯穿整个时间链的“传送带”。信息在这条传送带上可以几乎无损地线性流动。LSTM 通过一种称为“门 (Gate)”的结构来去除或增加信息到细胞状态中。
门控的数学定义所有的门都具有相同的数学形式:即一个 Sigmoid 神经网络层。
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]
Sigmoid 函数的输出值在 \((0, 1)\) 之间,描述了信息通过的比例:\(0\) 代表“完全阻断”,\(1\) 代表“完全通过”。
为了直观展示这种“双轨制”的记忆流转,我们同样将 LSTM 按时间步展开。注意观察图中贯穿始终的 \(C_t\) 粗线,这正是 LSTM 区别于标准 RNN 的精髓所在:
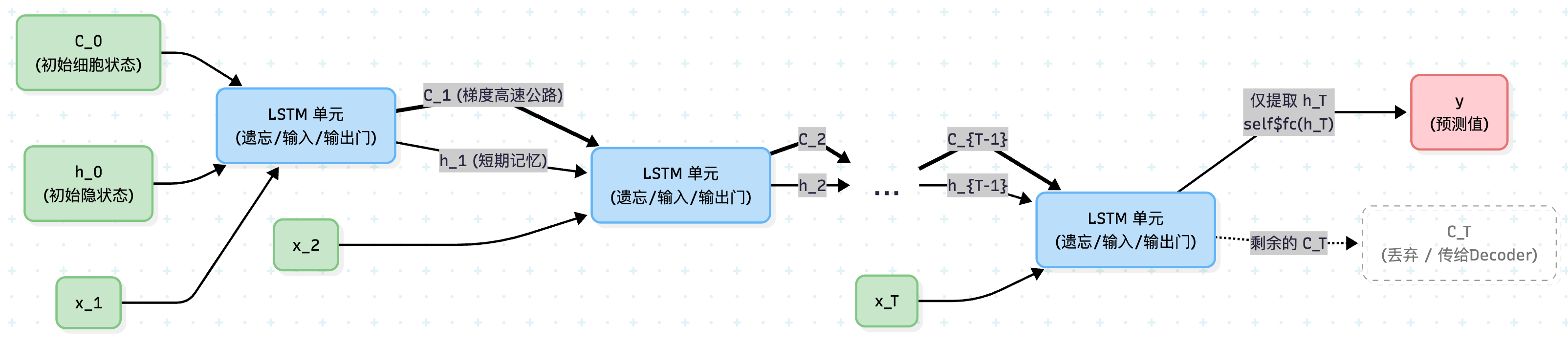
在这张展开图中,你能清晰地看到两个维度的信息流动:
- 长程记忆传送带(粗线 \(C_t\)):这是梯度的“高速公路”,它几乎只发生简单的加法交互。
- 短程记忆与输出(细线 \(h_t\)):它更像是 RNN 中的传统隐状态,负责提取当前的局部特征并用于最终输出。
不仅如此,最右侧的输出结构也揭示了多对一 (Many-to-One) 任务在代码底层的行为:当循环结束时,我们只提取最后一个时间步的隐状态 \(h_T\) 喂给全连接层,而细胞状态 \(C_T\) 则功成身退。
在 \(t\) 时刻,LSTM 接收输入 \(x_t\) 和上一时刻的隐状态 \(h_{t-1}\),通过以下三个步骤更新状态:
第一步:遗忘门 (Forget Gate) —— 决定丢弃什么
首先,网络需要决定从上一时刻的细胞状态 \(C_{t-1}\) 中丢弃哪些信息。这由遗忘门 \(f_t\) 完成:
\[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \]
- \(W_f\): 遗忘门的权重矩阵。
- \([h_{t-1}, x_t]\): 表示张量的拼接 (Concatenation)。
直观理解: 如果 \(f_t\) 的某个分量接近 0,说明对应的 \(C_{t-1}\) 中的记忆应当被遗忘(例如:当读到新的主语时,应当遗忘旧主语的性别信息)。
第二步:输入门 (Input Gate) —— 决定存储什么
这一步包含两个子部分:
- 输入门层 \(i_t\) (Sigmoid):决定更新哪些值。
- 候选记忆层 \(\tilde{C}_t\) (Tanh):创建一个新的候选值向量,准备加入状态中。
\[ \begin{aligned} i_t &= \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \\ \tilde{C}_t &= \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) \end{aligned} \]
为什么候选状态使用 Tanh 而不是 Sigmoid?Tanh 的输出范围是 \((-1, 1)\),这意味着它允许我们在状态中增加或减少信息(正负调整),从而使细胞状态保持中心化,利于优化;而 Sigmoid 只能进行正向缩放。
第三步:细胞状态更新 (核心公式)
这是 LSTM 最关键的一步。我们结合遗忘门和输入门来更新旧状态 \(C_{t-1}\) 到 \(C_t\):
\[ C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t\]
\(\odot\): 哈达玛积 (Hadamard Product),即逐元素相乘。
为什么这能解决梯度消失?请观察 \(C_t\) 对 \(C_{t-1}\) 的偏导数。在标准 RNN 中,\(h_t = \tanh(W h_{t-1} + \dots)\),导数包含 \(W\) 的连乘。而在 LSTM 中:
\[ \frac{\partial C_t}{\partial C_{t-1}} = f_t + \dots (\text{其他相关项}) \]
这种加法更新 (Additive Update) 的形式形成了梯度的“高速公路”。只要遗忘门 \(f_t\) 开启(接近 1),梯度就可以几乎无损地回传到很久以前的时刻,而不会像标准 RNN 那样指数级衰减。
第四步:输出门 (Output Gate) —— 决定输出什么
最后我们需要基于细胞状态 \(C_t\) 确定隐状态 \(h_t\)(即输出)。输出门 \(o_t\) 决定了细胞状态的哪些部分将被输出: \[ \begin{aligned} o_t &= \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \\ h_t &= o_t \odot \tanh(C_t) \end{aligned} \]
这里再次使用 \(\tanh\) 是为了将细胞状态的值重新映射回 \((-1, 1)\) 区间。
我们同样用 nn_linear 实现一下,理解它的各环节的作用:
library(torch)
lstm_model <- nn_module(
"lstm_model",
initialize = function(input_size, hidden_size, output_size) {
self$hidden_size <- hidden_size
# 公式中的 [h_{t-1}, x_t] 是一个拼接操作
# 所以全连接层的输入维度是:隐藏层维度 + 输入特征维度
combined_size <- hidden_size + input_size
# 按照公式的 4 个门,分别定义 4 个独立的线性层 (它们都自带 bias)
self$W_f <- nn_linear(combined_size, hidden_size) # 遗忘门
self$W_i <- nn_linear(combined_size, hidden_size) # 输入门
self$W_C <- nn_linear(combined_size, hidden_size) # 候选细胞
self$W_o <- nn_linear(combined_size, hidden_size) # 输出门
# 用于 Many-to-One 的最后映射输出层
self$Why <- nn_linear(hidden_size, output_size)
},
forward = function(x) {
# x: (batch_size, time_steps, input_size)
batch_size <- x$size(1)
time_steps <- x$size(2)
# 1. 初始化“双轨制”状态:隐状态 h_0 和细胞状态 C_0
h <- torch_zeros(batch_size, self$hidden_size, device = x$device)
C <- torch_zeros(batch_size, self$hidden_size, device = x$device)
# 2. 核心:时间步展开 (Unrolling over time)
for (t in 1:time_steps) {
xt <- x[ , t, ]
# 准备工作:将 h_{t-1} 和 x_t 在特征维度上拼接起来
# 对应公式中的 [h_{t-1}, x_t]
# 拼接后维度变为: (batch_size, hidden_size + input_size)
combined <- torch_cat(list(h, xt), dim = 2)
# 第一步:遗忘门 (决定丢弃什么)
ft <- torch_sigmoid(self$W_f(combined))
# 第二步:输入门与候选细胞 (决定存储什么)
it <- torch_sigmoid(self$W_i(combined))
C_tilde <- torch_tanh(self$W_C(combined))
# 第三步:更新细胞状态 (核心:梯度的加法高速公路)
# 在 R torch 中,星号 * 就是哈达玛积 (逐元素相乘)
C <- ft * C + it * C_tilde
# 第四步:输出门与更新隐状态 (决定输出什么)
ot <- torch_sigmoid(self$W_o(combined))
h <- ot * torch_tanh(C)
}
# 3. 输出方程:循环结束后,提取最后的短期记忆 h_T 映射为预测值
y <- self$Why(h)
return(y)
}
)本质同 RNN 没有区别,只是增加了到了 4 个全连接层,以及数据的拼接。
8.2.2 GRU
虽然 LSTM 很强大,但它每个时间步需要计算 4 个神经网络层,参数量大且计算慢。2014 年,门控循环单元 (Gated Recurrent Unit, GRU) 被提出。
GRU 做出了两个主要改变:
- 将遗忘门和输入门合并为一个更新门 (Update Gate)。
- 合并了细胞状态 \(C_t\) 和隐状态 \(h_t\),不再区分两者。
其核心公式如下:
- 重置门 (Reset Gate) \(r_t\): 决定在计算新候选状态时,这多少程度忽略过去的隐状态。
- 更新门 (Update Gate) \(z_t\): 决定保留多少旧状态,以及引入多少新状态。
\[ \begin{aligned} z_t &= \sigma(W_z \cdot [h_{t-1}, x_t]) \\ r_t &= \sigma(W_r \cdot [h_{t-1}, x_t]) \\ \tilde{h}_t &= \tanh(W \cdot [r_t \odot h_{t-1}, x_t]) \\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \end{aligned} \]
注意最后的 \(h_t\) 公式:它是一个线性插值。当 \(z_t \approx 0\) 时,模型几乎完全保留旧状态 \(h_{t-1}\),这使得 GRU 也能像 LSTM 一样捕捉长距离依赖。
8.2.3 变体结构
在实际工程中,单层的单向 RNN 往往不足以应对复杂任务。
1. 双向 RNN (Bi-directional RNN)
在文本分类或词性标注等任务中,一个词的含义不仅取决于上文,也取决于下文。Bi-RNN 包含两个独立的 RNN 层:
前向层 (Forward Layer): 从 \(t=1\) 读到 \(t=T\)。后向层 (Backward Layer): 从 \(t=T\) 读到 \(t=1\)。最终在 \(t\) 时刻的输出通常是两个方向隐状态的拼接:\(h_t = [h_t^{\rightarrow}, h_t^{\leftarrow}]\)。
2. 堆叠 RNN (Stacked RNN / Multi-layer RNN)
类似于多层感知机 (MLP),我们可以将 RNN 堆叠。第 \(L\) 层的输入是第 \(L-1\) 层的输出序列。深层结构能够提取更抽象的特征(例如底层识别词性,高层识别情感)。
8.2.4 nn_lstm 详解
前文我们手工实现了一个 LSTM,实际上 R torch 中已经封装好了函数 nn_lstm。
在构建模型过程中,最令人头疼的不是原理,而是张量的形状 (Shape)。如果理解错了维度,代码会抛出难以调试的 mismatch 错误。接下来我们将使用 nn_lstm 模块作为示例详解其中的过程,模型定义为:
rnn_layer <- nn_lstm(
input_size = 10, # 输入特征维度 (例如 Word Embedding 的维度)
hidden_size = 20, # 隐状态维度 (网络的"记忆容量")
num_layers = 2, # 堆叠层数
batch_first = TRUE, # 【重要】输入是否为 (batch, seq, feature)
bidirectional = TRUE # 是否双向
)
警告
如果不设置 batch_first = TRUE(默认值是 FALSE),RNN 期待的输入形状是:(seq_len, batch_size, input_size)。这与 CNN 或 MLP 的习惯 (batch, ...) 不同!这是为了在底层 C++ 计算时优化内存访问。但在 R 中,为了符合人类直觉,我们通常建议设置 batch_first = TRUE,这样输入就是:(batch_size, seq_len, input_size)
调用 LSTM 会返回两个对象:output 和 (h_n, c_n)。
output:包含了序列中每一个时间步最后一层隐状态的输出。
- 形状 (设
batch_first=TRUE):(batch_size, seq_len, num_directions * hidden_size) - 用于序列标注(如词性标注)、Seq2Seq 模型的编码器输出。
h_n:包含了序列最后一个时间步的隐状态(如果是双向,则包含正向最后一步和反向第一步)。
- 形状:
(num_layers * num_directions, batch_size, hidden_size) - 注意,无论
batch_first如何设置,这里batch_size总是在第二维。 - 用于文本分类、回归任务(即 Many-to-One 结构),通常作为整句话的特征表示(Context Vector)。
c_n :最后一个时间步的细胞状态。形状同 h_n。通常仅在 Seq2Seq 的 Decoder 初始化时使用。
实战代码演示——维度变换:
library(torch)
# Batch 大小为 3, 句子长度为 5, 每个词向量维度为 10
input <- torch_randn(3, 5, 10)
# 定义双向 LSTM
lstm <- nn_lstm(input_size = 10, hidden_size = 20,
batch_first = TRUE, bidirectional = TRUE)
# 前向传播
out_list <- lstm(input)
output <- out_list[[1]]
h_n <- out_list[[2]][[1]] # 隐状态元组的第一个元素
# 验证维度
# output: (Batch=3, Seq=5, Feat=20*2=40)
print(output$shape)
# h_n: (Layers=1 * Dir=2, Batch=3, Hidden=20) -> (2, 3, 20)
print(h_n$shape)
# 如何获取用于分类的向量?
# 对于双向 LSTM,通常拼接正向的最后一步和反向的最后一步(即反向的第一步)。
# 在 torch 中,h_n 已经包含了这些信息,或者我们可以从 output 中切片:
# (假设 batch_first=TRUE)
last_forward <- output[ , 5, 1:20] # 最后一个时间步的前 20 维
last_backward <- output[ , 1, 21:40] # 第一个时间步的后 20 维 (反向)8.3 连续型序列建模
在掌握了 LSTM 的数学原理与内部构造后,我们终于来到了工程实战环节。本节我们将解决最经典的深度学习应用场景之一——时间序列预测。
与处理文本数据(离散的 Token)不同,时间序列通常是连续的数值(如股价、气温、销售额)。我们的任务是根据过去的一段历史数据,预测未来的一个或多个数值。这在机器学习中属于回归(Regression)任务。
假设我们需要预测北京的小时温度。有一个时间序列数据集 \(D = \{x_1, x_2, ..., x_N\}\),其中 \(x_t\) 代表第 \(t\) 小时的气温。我们的目标是构建一个模型 \(f\),利用过去 \(W\) 小时的数据来预测第 \(t\) 小时的气温:
\[ \hat{x}_t = f(x_{t-W}, x_{t-W+1}, ..., x_{t-1}) \]
这里的 \(W\) 被称为窗口大小 (Window Size) 或序列长度 (Sequence Length)。
神经网络无法直接“理解”整条时间轴,我们需要将连续的时间序列转化为监督学习所需的 (特征, 标签) 对,即 (Features, Label)。
这一过程通过滑动窗口实现。想象一个长度为 \(W+1\) 的框,在时间序列上一步步向右滑动:
- 窗口 1: 输入 \([x_1, ..., x_W]\), 标签 \(x_{W+1}\)
- 窗口 2: 输入 \([x_2, ..., x_{W+1}]\), 标签 \(x_{W+2}\)
- …
我们使用 PRSA_data_2010.1.1-2014.12.31.csv,该数据集记录了 2010 年至 2014 年北京每个小时的 PM2.5 浓度数据 (Chen 2015),同时刚好有对应的气温、露点温度、大气压、综合风向、累计风速、累计降雪小时数、累计降雨小时数等数据。
| No | year | month | day | hour | pm2.5 | DEWP | TEMP | PRES | cbwd | Iws | Is | Ir |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2010 | 1 | 1 | 0 | NA | -21 | -11 | 1021 | NW | 1.79 | 0 | 0 |
| 2 | 2010 | 1 | 1 | 1 | NA | -21 | -12 | 1020 | NW | 4.92 | 0 | 0 |
| 3 | 2010 | 1 | 1 | 2 | NA | -21 | -11 | 1019 | NW | 6.71 | 0 | 0 |
| 4 | 2010 | 1 | 1 | 3 | NA | -21 | -14 | 1019 | NW | 9.84 | 0 | 0 |
| 5 | 2010 | 1 | 1 | 4 | NA | -20 | -12 | 1018 | NW | 12.97 | 0 | 0 |
| 6 | 2010 | 1 | 1 | 5 | NA | -19 | -10 | 1017 | NW | 16.10 | 0 | 0 |
我们的案例将利用前 72 小时的气温 TEMP、露点温度 DEWP、大气压 PRES 、小时 hour、月份数据 month,来预测下一个小时的气温。
8.3.1 数据预处理
在数据变为 torch 能读懂的数据之前,先做一下数据预处理。有两个关键处理需要注意:
1. 时间周期编码 (Cyclical Encoding)
数据预处理依然使用了 tidymodels 包。变量处理上,我们没有直接使用原始的 0-23 的小时数和 1-12 的月份数,而是将其转换为 sin 和 cos 值。
#| filename: "8_beijing_seq_lstm.R"
url <- "/Users/liusizhe/data/PRSA_data_2010.1.1-2014.12.31.csv"
# 基础清洗与特征提取
df_clean <- read.csv(url) %>%
mutate(time = ymd_h(paste(year, month, day, hour))) %>%
arrange(time) %>%
mutate(
hour_sin = sin(2 * pi * hour / 24),
hour_cos = cos(2 * pi * hour / 24),
month_sin = sin(2 * pi * month / 12),
month_cos = cos(2 * pi * month / 12)
) %>%
select(time, TEMP, PRES, DEWP, hour_sin, hour_cos, month_sin, month_cos)因为时间是循环的(23点和0点很接近),如果直接用数字,23 和 0 会显得距离很远。正余弦转换保留了时间的连续性和周期性。
2. 数据切分
利用专门用于时序数据的截断函数 initial_time_split。
# 专门用于时序数据,严格按时间顺序截断 (前80%训练,后20%验证)
time_split <- initial_time_split(df_clean, prop = 0.8)
train_raw <- training(time_split)
valid_raw <- testing(time_split)3. 标准化(Z-Score)
正态分布标准化:\(x_{new} = \frac{x - \mu}{\sigma}\)。如果不做标准化,会因为量纲问题导致 LSTM 无法有效学习。当然,模型训练完之后,需要将预测结果反标准化,才能得到真实的气温值。
ts_recipe <- recipe(~ ., data = train_raw) %>%
update_role(time, new_role = "ID") %>%
step_normalize(TEMP, PRES, DEWP)
ts_prep <- prep(ts_recipe, training = train_raw)
train_data_norm <- bake(ts_prep, new_data = NULL, -time) %>% as.matrix()
valid_data_norm <- bake(ts_prep, new_data = valid_raw, -time) %>% as.matrix()
# TIDYMODELS 把计算好的统计量极其规范地存在了 prep 对象里
temp_mean <- ts_prep$steps[[1]]$means["TEMP"]
temp_sd <- ts_prep$steps[[1]]$sds["TEMP"]仅在 train_raw 上计算 Mean 和 SD,然后应用到 valid_raw。绝对不能使用全量数据的统计值进行标准化,否则验证集的信息会泄露给训练过程。
接下来就是将标准化后的数据集转换为 torch 能读懂的格式。
time_series_dataset <- dataset(
name = "ts_dataset",
initialize = function(data, seq_len) {
self$data <- torch_tensor(data, dtype = torch_float())
self$seq_len <- seq_len
},
.getitem = function(i) {
x <- self$data[i:(i + self$seq_len - 1), ]
# 这会返回一个 (1) 的张量,DataLoader 拼接后变成 (64, 1)
y <- self$data[i + self$seq_len, 1]$unsqueeze(1)
list(x = x, y = y)
},
.length = function() {
nrow(self$data) - self$seq_len
}
)
train_ds <- time_series_dataset(train_data_norm, seq_len)
valid_ds <- time_series_dataset(valid_data_norm, seq_len)滑动窗口大小 \(W\) 通过 seq_len 参数指定。通过 .getitem 方法,我们可以从数据集中提取出 (x, y) 对。这里的特征是一个 \(W \times 7\) 的矩阵,标签是一个 \(1\) 维向量。
以及还有一个关键的 .getitem 中使用了 $unsqueeze(1):torch 的 MSE Loss 要求预测值 (Batch, 1) 和 真实值 (Batch, 1) 形状一致。如果不加这一步,Target 会变成 (Batch),导致计算 Loss 时触发广播机制(Broadcasting)或者报错。
最后是构建 dataloader,train_dl 做了随机化,并设置如果最后一个 batch 样本量不足,则做抛掉处理 (避免出现一个样本的情况):
train_dl <- dataloader(train_ds, batch_size = 64, shuffle = TRUE, drop_last = TRUE)
valid_dl <- dataloader(valid_ds, batch_size = 64, shuffle = FALSE, drop_last = TRUE)8.3.2 模型定义和训练
开始定义 lstm 模型,我们预期结构和参数如下:
Input (7 features) -> LSTM (Hidden 64) -> Linear (64 -> 1) -> Output
这是一个典型的 Many-to-One 模式,LSTM 会输出一个序列 (Batch, Seq_Len, Hidden)。
lstm_regressor <- nn_module(
"lstm_regressor",
initialize = function(input_size, hidden_size, output_size, num_layers) {
self$lstm <- nn_lstm(
input_size = input_size,
hidden_size = hidden_size,
num_layers = num_layers,
batch_first = TRUE,
dropout = 0.2 # 增加一点 dropout 防止过拟合
)
self$linear <- nn_linear(hidden_size, output_size)
},
forward = function(x) {
# x shape: (batch, seq_len, input_size)
out_list <- self$lstm(x)
# 取序列最后一个时间步的输出
output <- out_list[[1]]
last_step_out <- output[, dim(output)[2], ]
out <- self$linear(last_step_out)
return(out)
}
)代码中 out_list[[1]] 和 output[, dim(output)[2], ] 取出了序列的最后一个时间步的输出,只把这一个向量喂给全连接层。这是标准的“Many-to-One”预测写法。
训练过程以及如下 (设置了早停策略):
n_features <- ncol(train_data_norm) # 7 (3个物理量 + 4个时间分量)
fitted <- lstm_regressor %>%
setup(
loss = nn_mse_loss(),
optimizer = optim_adam,
metrics = list(luz_metric_mae())
) %>%
set_hparams(
input_size = n_features,
hidden_size = 128,
output_size = 1,
num_layers = 2 # 稍微加深网络
) %>%
set_opt_hparams(
lr = 0.001
) %>%
fit(
train_dl,
epochs = 20,
valid_data = valid_dl,
callbacks = list(
luz_callback_early_stopping(monitor = "valid_loss", patience = 5)
),
verbose = TRUE
)这里使用了堆叠 LSTM 的变体结构,增加了一个 LSTM 层,dropout = 0.2 参数仅在 num_layers > 1 时才生效。它会被插入在第一层和第二层之间,随机丢弃 20% 的连接,防止过拟合。模型真正的结构实际是:
Input -> LSTM -> Dropout -> LSTM -> Linear -> Output
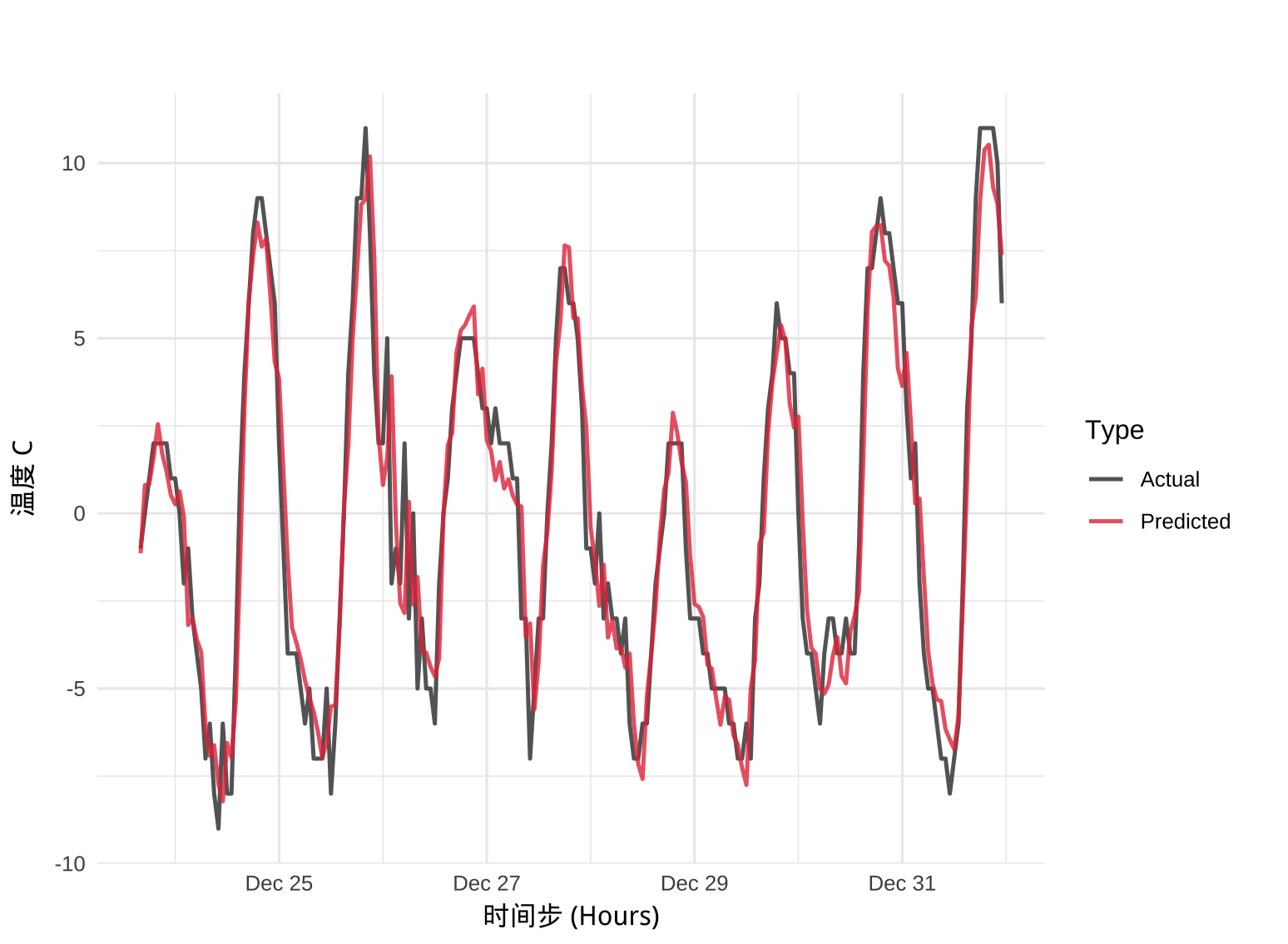
训练完模型,我们取最后的 200 个样本进行可视化,对比真实值和预测值(预测值需要做反标准化)。
preds_tensor <- predict(fitted, valid_dl)
preds_scaled <- as.numeric(preds_tensor)
# 获取真实值:对应的时间点是从 seq_len + 1 开始的,第1列 TEMP
actuals_scaled <- valid_data_norm[(seq_len + 1):nrow(valid_data_norm), 1]
# 反标准化 (Reverse Z-Score)
# 公式: x = z * sd + mean
preds_real <- preds_scaled * temp_sd + temp_mean
actuals_real <- actuals_scaled * temp_sd + temp_mean最终模型的预测效果:
注记思考题
我们提取了 LSTM 最后一个时间步的输出作为整个序列的表征,这是一种最基础的Many-to-One 结构。如果我们要预测未来 3 天 的气温(Many-to-Many),模型的输出层和 Dataset 的标签部分应该如何修改?(提示:标签维度将变为 \(W+1, W+2, W+3\))。
8.4 离散型序列处理
气温预测十分顺利,因为输入原本就是规整的数值矩阵。但当我们面对自然语言文本(离散符号)且句子长短不一时,LSTM 无法直接处理。我们需要跨越三大工程难点:词嵌入的查表机制、文本流水线,以及变长序列的 Padding与 Packing 技术。
8.4.1 Embedding 层
对于文本数据,最直观的表示方法是 One-Hot 编码。假设词表大小为 10000,单词 “Apple” 的索引是 5,则其向量可以表示为:[0, 0, 0, 0, 1, 0, ..., 0]。
但在深度学习中,我们几乎从不直接使用 One-Hot,原因有二:
- 输入向量维度过大且极其稀疏,计算效率极其低下。
- 任何两个词向量的内积为 0,无法体现 “Apple” 与 “Fruit” 的相似性。
nn_embedding 层在数学上等价于一个不带偏置项的线性层 (Linear Layer),其输入是 One-Hot 向量。
设词表大小为 \(V\),嵌入维度为 \(D\)。嵌入层的权重矩阵 \(W \in \mathbb{R}^{V \times D}\)。 对于第 \(i\) 个词(索引为 \(i\)),其 One-Hot 向量 \(e_i\) 与 \(W\) 相乘:
\[ \text{Embedding}(i) = e_i^T \cdot W = W[i, :] \]
由于 \(e_i\) 中只有第 \(i\) 位是 1,其余为 0,这个矩阵乘法实际上就是取出矩阵 \(W\) 的第 \(i\) 行。因此,在工程实现上,nn_embedding 不做矩阵乘法,而是直接进行数组索引(Index Lookup),速度极快。
在 R torch 中,nn_embedding 接收的是整数索引(而非 One-Hot 向量)。
# 假设词表大小 1000,每个词映射为 32 维向量
embed_layer <- nn_embedding(num_embeddings = 1000, embedding_dim = 32)
# 输入必须是 Long (整数) 类型张量
# 形状: (Batch_Size, Seq_Len) -> (2, 3)
input_indices <- torch_tensor(
matrix(c(1, 5, 9, 2, 6, 10), nrow = 2), dtype = torch_long())
# 输出形状: (Batch_Size, Seq_Len, emb_dim) -> (2, 3, 32)
output_vectors <- embed_layer(input_indices)nn_embedding 的权重 \(W\) 是可学习的参数。在训练过程中,模型会自动调整每个词的向量表示,使得语义相近的词在空间距离上更近。
除了通过模型训练自动学习,我们还可以手动初始化嵌入层的权重。这在以下场景中非常有用:
- 预训练模型:如 BERT、GPT 等,已经在大规模文本数据上预训练,包含了丰富的语义信息。我们可以直接加载这些模型的嵌入层权重,作为我们任务的初始化。
- 领域特定任务:如果任务数据与预训练模型的领域有显著差异,手动初始化可以帮助模型更快地收敛到任务相关的表示。比如 R 包
text2vec中提供的 GloVe 算法,就可以用于初始化嵌入层。
8.4.2 文本流水线
在 R 生态中,我们可以利用 R 强大的字符串处理能力(如 tidytext, stringr, text2vec)来构建更透明的流水线:
Tokenization (分词):对于英文,最简单的分词是按空格切分;对于中文,通常使用
jiebaR等工具。Vocabulary (构建词表):词表就是一个字典,记录了所有出现过的词与整数索引的一一对应关系。但在深度学习中,我们需要在词表中预留几个特殊令牌 (Special Tokens),这非常关键:
<PAD>(Padding): 用于填充短句子,使其与长句子等长。通常索引设为 0 或 1。<UNK>(Unknown): 处理从未见过的生僻词。<SOS>(Start of Sequence) 和<EOS>(End of Sequence): 句首尾标记1。
构建一个简易的 Vocab 类
#| filename: "8_movie_sentiment_lstm.R"
library(tidytext)
library(dplyr)
library(purrr)
TidyTextPipeline <- R6::R6Class(
"TidyTextPipeline",
public = list(
token_to_idx = NULL,
idx_to_token = NULL,
max_len = NULL,
initialize = function(texts,
max_vocab = 20000,
max_len = 256) {
self$max_len <- max_len
token_df <- tibble(text = texts) %>% unnest_tokens(word, text)
top_tokens <- token_df %>% count(word, sort = TRUE) %>%
head(max_vocab) %>% pull(word)
full_vocab <- c("<PAD>", "<UNK>", top_tokens)
self$idx_to_token <- full_vocab
self$token_to_idx <- set_names(seq_along(full_vocab), full_vocab)
cat("词汇表构建完成。大小:", length(full_vocab), "\n")
},
encode = function(text) {
tokens <- tibble(text = text) %>% unnest_tokens(word, text) %>% pull(word)
indices <- self$token_to_idx[tokens]
indices[is.na(indices)] <- self$token_to_idx["<UNK>"]
n <- length(indices)
pad_idx <- self$token_to_idx["<PAD>"]
if (n >= self$max_len)
indices[1:self$max_len]
else
c(indices, rep(pad_idx, self$max_len - n))
},
decode = function(indices) {
indices <- as.integer(indices)
tokens <- self$idx_to_token[indices]
tokens <- tokens[!is.na(tokens) & tokens != "<PAD>"]
paste(tokens, collapse = " ")
},
vocab_size = function()
length(self$idx_to_token)
)
)函数讲解:
- 这是一个 R6 类,所有的功能都定义在 public 列表中,意味着可以从外部直接访问。
token_to_idx,idx_to_token,max_len这三个变量是该管道的核心状态,用于存储词汇表映射关系和配置。 initialize是类的构造函数,在创建新对象TidyTextPipeline$new(...)时运行。它的目标是构建词汇表。encode编码,是该类的核心功能函数。它的目标是将单个文本字符串转换为固定长度的整数向量。逻辑流程:Tokenization -> Indexing -> Padding。decode解码,将整数向量转换为原始文本字符串,主要用于 debug。vocab_size返回当前词汇表的大小,包括<PAD>,<UNK>, 以及所有出现过的词。
注意,该函数类基于 tidytext 包构造,该包设计思想主要基于 tidy data principles 理念(Wickham 2014)。文本数据处理过程被转换为 tidy 格式(每个变量是一列,每个观测是一行),这使得文本处理更加透明、可维护。
例如该函数可以很方便的增加去除停止词这些预处理步骤,只需在 initialize 的管道中加入 anti_join(stop_words) 即可,非常便于后期维护和扩展。
我们用一个简单的例子来展示 TidyTextPipeline 类的使用:
texts <- c("I love R language!", "Deep learning is fun.")
pipeline <- TidyTextPipeline$new(texts, max_len = 8) # 初始化流水线
pipeline$vocab_size() # 10
head(pipeline$token_to_idx)
# <PAD> <UNK> i love r language
# 1 2 3 4 5 6
# 编码 (Encoding)
encoded_seq <- pipeline$encode("I love python and R!")
unname(encoded_seq)
# [1] 5 9 2 2 10 1 1 1
pipeline$decode(encoded_seq) # 解码 (Decoding)
# [1] "i love <UNK> <UNK> r"8.4.3 变长序列处理
由于 torch 的张量必须是矩形(矩阵或高维方块),而一个 Batch 中的句子长度往往不同(如:“Yes” vs “I love machine learning”)。我们必须对其进行对齐。
Padding (填充)
最简单的方法是填充。找到 Batch 中最长的句子,将短句子用 <PAD>(通常索引为 0 或 1)填补。实现函数 nn_utils_rnn_pad_sequence。但如果不做额外处理,LSTM 会把 <PAD> 当作普通单词处理,更新隐状态。这不仅浪费计算资源,还会引入噪声(模型会“学习”到填充符的模式)。
Masking (掩码)
为了解决 Padding 的问题,我们可以在计算 Loss 时使用 Mask 矩阵(由 0 和 1 组成),忽略标记为 0 的位置。但这只能解决 Loss 计算问题,无法节省 LSTM 前向传播时的计算量。
Packing (打包)
R torch (底层调用 PyTorch C++) 提供了一种更高级的机制:nn_utils_rnn_pack_padded_sequence:将 Padding 后的张量压扁,去掉无效的填充位,并按照时间步重新组织数据。
- 排序:将一个 Batch 内的序列按长度降序排列。
- Pack:使用
nn_utils_rnn_pack_padded_sequence将张量转换为PackedSequence对象。此时数据不再是(Batch, Seq, Feat)的 3D 张量,而是被压缩了。 - Forward:将
PackedSequence喂给 LSTM。LSTM 内部通过 C++ 优化,能够识别每个时间步的有效 Batch Size,跳过填充位的计算。 - Unpack:LSTM 输出后,使用
nn_utils_rnn_pad_packed_sequence将其还原为标准的 Padding 后的张量,以便进行后续的全连接层计算。
8.4.3.1 Padding 与 Packing 的完整闭环
这是你在实际项目中必须掌握的标准范式:
# 假设我们有 3 个变长序列,已经数值化
s1 <- torch_tensor(c(1, 2, 3)) # 长度 3
s2 <- torch_tensor(c(4, 5)) # 长度 2
s3 <- torch_tensor(c(6)) # 长度 1
batch_list <- list(s1, s2, s3)
# 1. Padding: 变为规整张量
# batch_first=TRUE -> (Batch, Seq)
padded_batch <- nn_utils_rnn_pad_sequence(batch_list,
batch_first = TRUE, padding_value = 0)
cat("Padded Shape:", paste(padded_batch$shape, collapse="x"), "\n")
# Padded Shape: 3 x 3
# [1, 2, 3]
# [4, 5, 0]
# [6, 0, 0]
# 2. 记录原始长度 (CPU上的向量)
lengths <- torch_tensor(c(3, 2, 1), device = "cpu")
# 3. Packing (压缩)
# enforce_sorted=TRUE 要求输入按长度降序排列(我们这里已经是了)
packed_input <- nn_utils_rnn_pack_padded_sequence(
padded_batch,
lengths,
batch_first = TRUE,
enforce_sorted = TRUE
)
# 4. 喂入 Embedding 和 LSTM
# 注意:Embedding 层可以直接处理 Padded Tensor,也可以处理 PackedSequence (需特殊技巧),
# 通常做法是:先 Embedding -> 再 Pack -> 再 LSTM
embed_layer <- nn_embedding(10, 5, padding_idx=0) # padding_idx 设为0,梯度永远为0
lstm <- nn_lstm(5, 10, batch_first = TRUE)
# 正确流程:
x_embed <- embed_layer(padded_batch) # (3, 3, 5)
# Pack Embedding 后的结果
x_packed <- nn_utils_rnn_pack_padded_sequence(x_embed, lengths,
batch_first = TRUE)
# LSTM 前向传播 (高效模式)
out_packed_tuple <- lstm(x_packed)
out_packed <- out_packed_tuple[[1]]
hidden_states <- out_packed_tuple[[2]]
# 5. Unpack (还原)
# 还原为 (Batch, Seq, Hidden)
out_unpacked_tuple <- nn_utils_rnn_pad_packed_sequence(out_packed,
batch_first = TRUE)
output_tensor <- out_unpacked_tuple[[1]]
cat("Output Shape:", paste(output_tensor$shape, collapse="x"), "\n")
# Output Shape: 3 x 3 x 108.5 IMDB 影评情感分析
数据源使用的是 IMDB 电影评论数据集(Maas 等 2011),包含 50000 条电影评论,其中 25000 条为训练集,25000 条为测试集。每个评论都被标注为正面(1)或负面(0)。最早用于 libsvm 分类的版本。我们用这个数据集构建双向 lstm 模型,用于情感分析。
8.5.1 数据预处理
以 train 目录为例,展示数据结构:
[2] “data/imdb/aclImdb/train/neg”
[3] “data/imdb/aclImdb/train/pos”
正面和负面评论分别在 pos 和 neg 子目录下。每个文件对应一条评论,文件名是评论的 id。我们需要将其转化为数据框,包含两列:text 是评论内容,label 是情感标签(1 为正面,0 为负面)。
#| filename: "8_movie_sentiment_lstm.R"
library(tidyverse)
library(tribble)
library(fs)
load_imdb_data <- function(root_path) {
cat(sprintf("正在扫描目录: %s ...\n", root_path))
pos_files <- dir_ls(file.path(root_path, "pos"), glob = "*.txt")
neg_files <- dir_ls(file.path(root_path, "neg"), glob = "*.txt")
pos_texts <- map_chr(pos_files, read_file)
neg_texts <- map_chr(neg_files, read_file)
tibble(
text = c(pos_texts, neg_texts),
label = c(rep(1, length(pos_texts)), rep(0, length(neg_texts)))
)
}加载 IMDB 数据集:
base_path <- "/Users/liusizhe/data/imdb/aclImdb"
train_df <- load_imdb_data(file.path(base_path, "train"))
test_df <- load_imdb_data(file.path(base_path, "test"))利用前文定义的“文本流水线”将评论文本转换为 token id 序列2。
pipeline <- TidyTextPipeline$new(texts = train_df$text,
max_vocab = 20000,
max_len = 256)关于 max_len = 256 是否够用,我们可以看一下 train 数据集中的评论长度分布。
> summary(text_lengths)
Min. 1st Qu. Median Mean 3rd Qu. Max.
10.0 131.0 181.0 242.3 295.0 2525.0 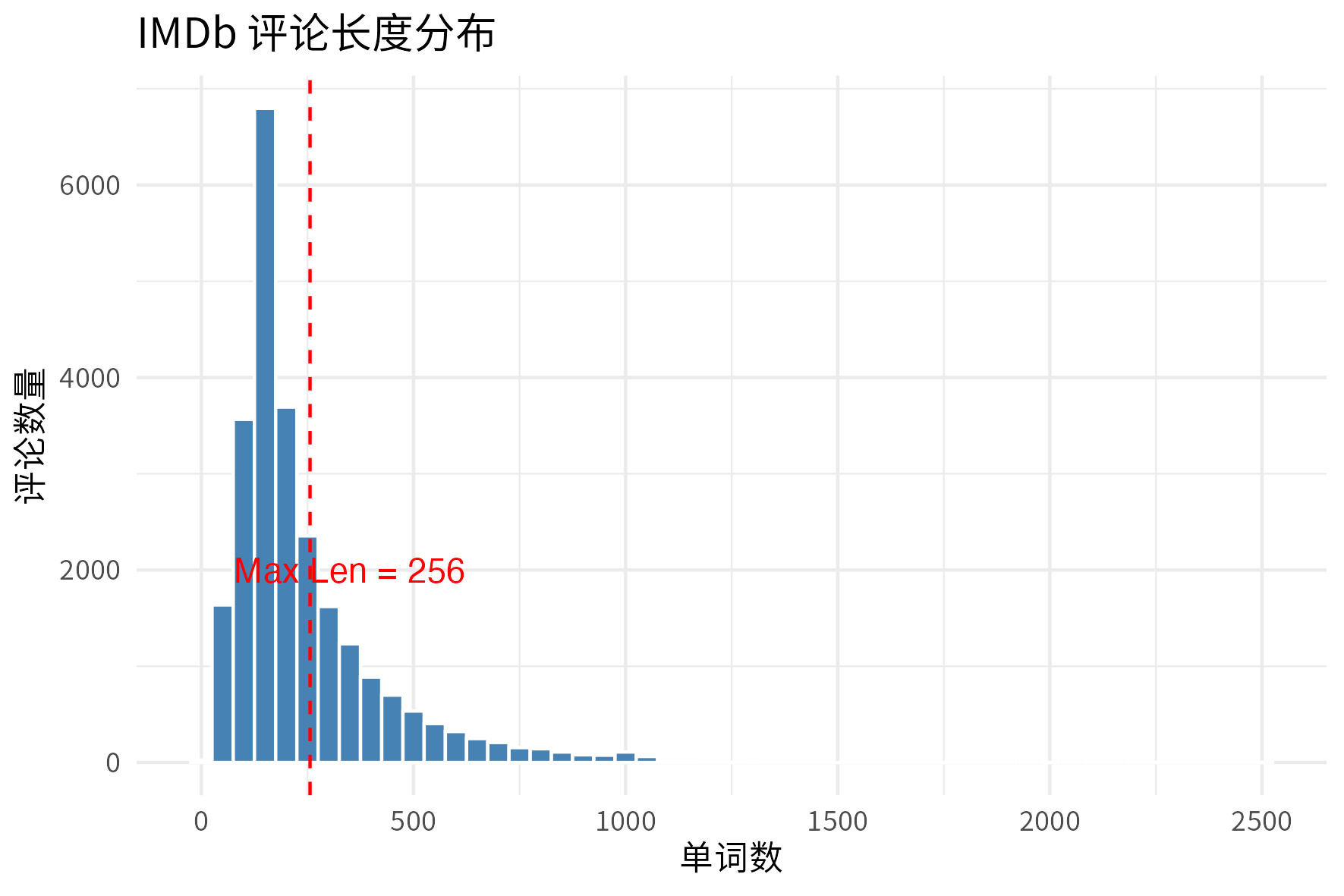
长度小于等于 256 的评论占比为 69.18%,考虑到 IMDB 数据集的评论长度分布是长尾分布,69.18% 的评论长度在 256 以下,这算是一个合理的设置。
定义一个简单的数据集类 SimpleIMDbDataset,该类用于加载 IMDB 数据集,将数据转化为 torch 张量格式。
SimpleIMDbDataset <- dataset(
"SimpleIMDbDataset",
initialize = function(df, pipeline) {
self$df <- df
self$pipeline <- pipeline
},
.getitem = function(i) {
list(
x = torch_tensor(self$pipeline$encode(self$df$text[i]), dtype = torch_long()),
y = torch_tensor(self$df$label[i], dtype = torch_float())
)
},
.length = function()
nrow(self$df)
)封装 Dataset 并且定义 DataLoader:
train_ds <- SimpleIMDbDataset(train_df, pipeline)
valid_ds <- SimpleIMDbDataset(test_df, pipeline)
train_dl <- dataloader(train_ds, batch_size = 64, shuffle = TRUE)
valid_dl <- dataloader(valid_ds, batch_size = 64, shuffle = TRUE)8.5.2 模型定义和训练
在情感分析场景下,会更复杂。比如说这句话
你觉得我真的喜欢她吗?不!
如果从左到右读取,模型会先处理“你觉得我真的喜欢她吗?”这部分,然后是“不!”这部分。真实情感是负面的。所以我们考虑将评论文本从左到右和从右到左分别输入到模型中,取平均值作为最终的情感预测。
定义一个双向 lstm 模型 BidirectionalLSTM:
# 双向 LSTM + Mean Pooling
IMDbLSTM <- nn_module(
"IMDbLSTM",
initialize = function(vocab_size,
emb_dim,
hidden_dim,
output_dim = 1) {
self$embedding <- nn_embedding(vocab_size, emb_dim,
padding_idx = 1)
self$lstm <- nn_lstm(emb_dim,
hidden_dim,
batch_first = TRUE,
bidirectional = TRUE)
self$fc <- nn_linear(hidden_dim * 2, output_dim) # 双向所以 *2
self$dropout <- nn_dropout(0.5)
},
forward = function(x) {
x <- self$embedding(x)
output <- self$lstm(x)
# Mean Pooling: 对所有时间步求平均,比只取最后一个稳健
avg_pool <- torch_mean(output[[1]], dim = 2)
self$fc(self$dropout(avg_pool))
}
)基本结构为:
Input -> Embedding -> BiLSTM -> AvePooling -> Dropout -> Linear -> Output
从 forward 视角看整个数据流是怎样的:假设我们输入一个 Batch,里面有一句话:“The movie is good” (假设经过填充后长度为 Max_Len = 256)。
- 句子转 Token:
pipeline$encode("The movie is good"),输出位整数索引序列 (Indices),例如 [23, 104, 8, 55, 1, 1, …] (1 是 padding)。形状为[64, 256]。 - 查表找词向量:
x <- self$embedding(x),利用上一步的整数索引,去vocab_size x 128的大矩阵里把对应的行取出来。这个大矩阵(Embedding Matrix)里的数值是在不断更新的。形状从[64, 256]变为了[64, 256, 128](增加了 Embedding 维度)。 - LSTM 处理
output <- self$lstm(x),LSTM 按照时间步(Sequence)一步步吃进词向量,结合上下文更新隐藏状态。形状变化:[64, 256, 128]到[64, 256, 128]。注意:这里输出维度变了,128 是 lstm 的hidden_dim = 64且bidirectional = TRUE。 - 求每个词的均值:
avg_pool <- torch_mean(output[[1]], dim = 2)。它在时间步维度 (dim=2) 上取平均,把 256 个词的特征压缩成一个句子的特征。形状变化:[64, 256, 128]到[64, 128]。不管句子多长,这里都变成了一个固定长度的向量。 - 全连接与概率预估 (Linear + Sigmoid):
self$fc(self$dropout(avg_pool)),将 128 维的句子特征映射到 1 维(正/负打分)。形状变化:[64, 128] -> [64, 1]。
接下来,我们将模型训练 10 个 epoch,使用 Adam 优化器,学习率为 1e-3。同时使用早停策略,当验证集损失不再提升时,提前停止训练。
fitted <- IMDbLSTM %>%
setup(
loss = nn_bce_with_logits_loss(),
optimizer = optim_adam,
metrics = list(luz_metric_binary_accuracy_with_logits())
) %>%
set_hparams(
vocab_size = pipeline$vocab_size() + 1,
emb_dim = 128,
hidden_dim = 64
) %>%
set_opt_hparams(lr = 0.001) %>%
fit(
train_dl,
valid_data = valid_dl,
epochs = 10,
verbose = TRUE,
callbacks = list(
luz_callback_early_stopping(monitor = "valid_loss",
patience = 2) # 没提升就早停
)
)观察模型的效果。
- 验证集的精度在 85%,训练集的精度可以到 95%
- 但在第 5 个 epoch 时,验证集损失不再提升,模型提前停止训练。
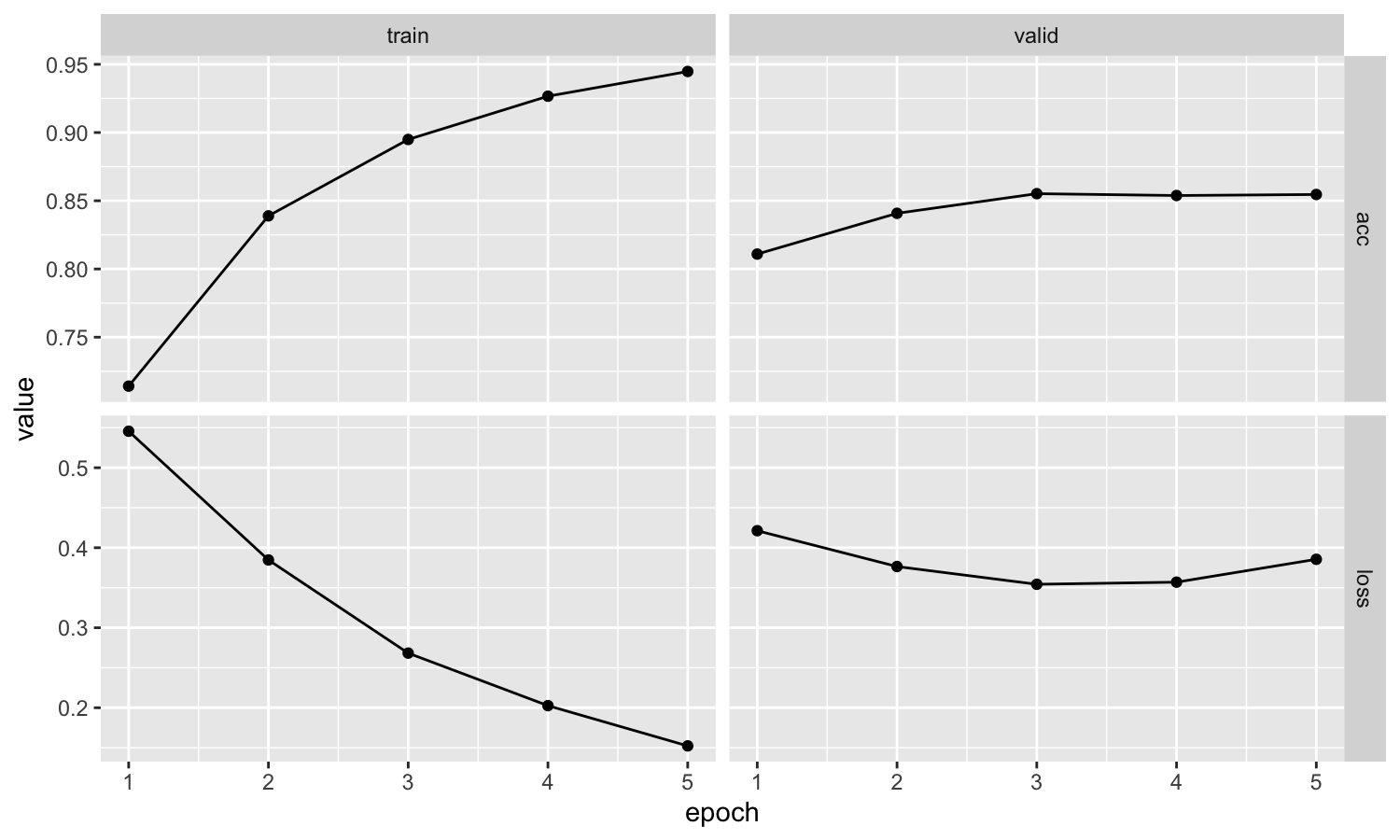
我们将该模型应用于《疯狂动物城2》,来看预测效果。首先先定义一个预测函数:
predict_sentiment <- function(text) {
input_ids <- pipeline$encode(text)
input_tensor <- torch_tensor(input_ids,
dtype = torch_long())$unsqueeze(1)
pred <- predict(fitted, input_tensor)
prob <- torch_sigmoid(pred)
score <- as.numeric(prob)
cat(sprintf("评分: %.4f (%.1f%% 概率是好评)\n", score, score * 100))
}为了演示效果,我们拿豆瓣的《疯狂动物城2》的 3 条短评做演示(需要用翻译为英文再做预测):
影院重新成为庇护所的108分钟
译:108 minutes of cinemas becoming a sanctuary again
我喜欢这一部的价值观甚至要更胜过第一部,感谢迪士尼在这样撕裂的时代里还愿意输出这样的故事。 如果它诞生在10年前,我会说迪士尼又端上来了一盘精致的老式甜品,可恰恰因为它诞生在今天的世界,我衷心地希望这样的电影越多越好。
译:I love the values conveyed in this installment even more than in the first one. Thank you, Disney, for still being willing to tell a story like this in such fractured times. Had it been released ten years ago, I might have called it yet another exquisitely crafted old-fashioned confection from Disney. But precisely because it was born in the world of today, I sincerely hope there will be more films like this.
我的天啊,太难看了,不是说了宝伯特是坏人然后后面就上了他的车是什么鬼???纯卖萌片。
译:My God, this is so terrible. Didn’t they say Baobote was the bad guy? Then why did they get into his car afterward? What the heck??? Just a pure moe anime.
预测函数为三个评论给出的好评概率分别为 0.6236,0.9431,0.3324。基本符合我们的预期。
8.5.3 Fine-tuning
可以想象,随着训练的进行,token 的词向量会不断调整,表示的会越来越有意义。
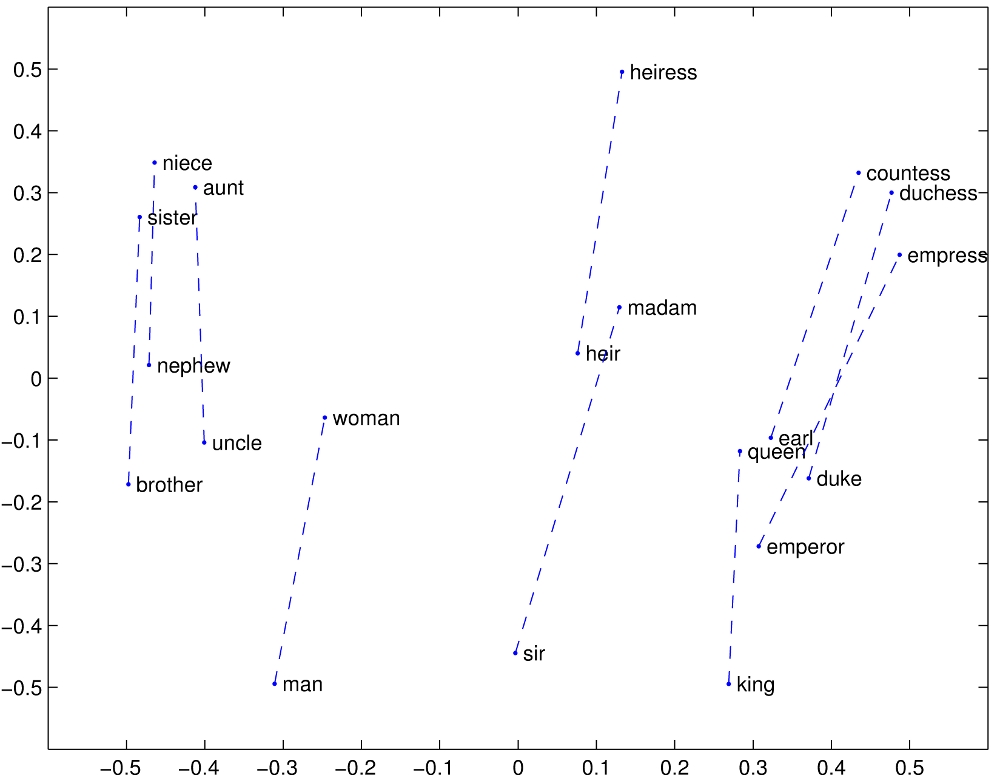
我们验证一下 “amazing”, “terrible”, “bad”, “excellent” 这三个单词的词向量的 cosine 相似性变化趋势(靠前的 epoch 更能体现变化,所以只训练了 2 个 epoch)。
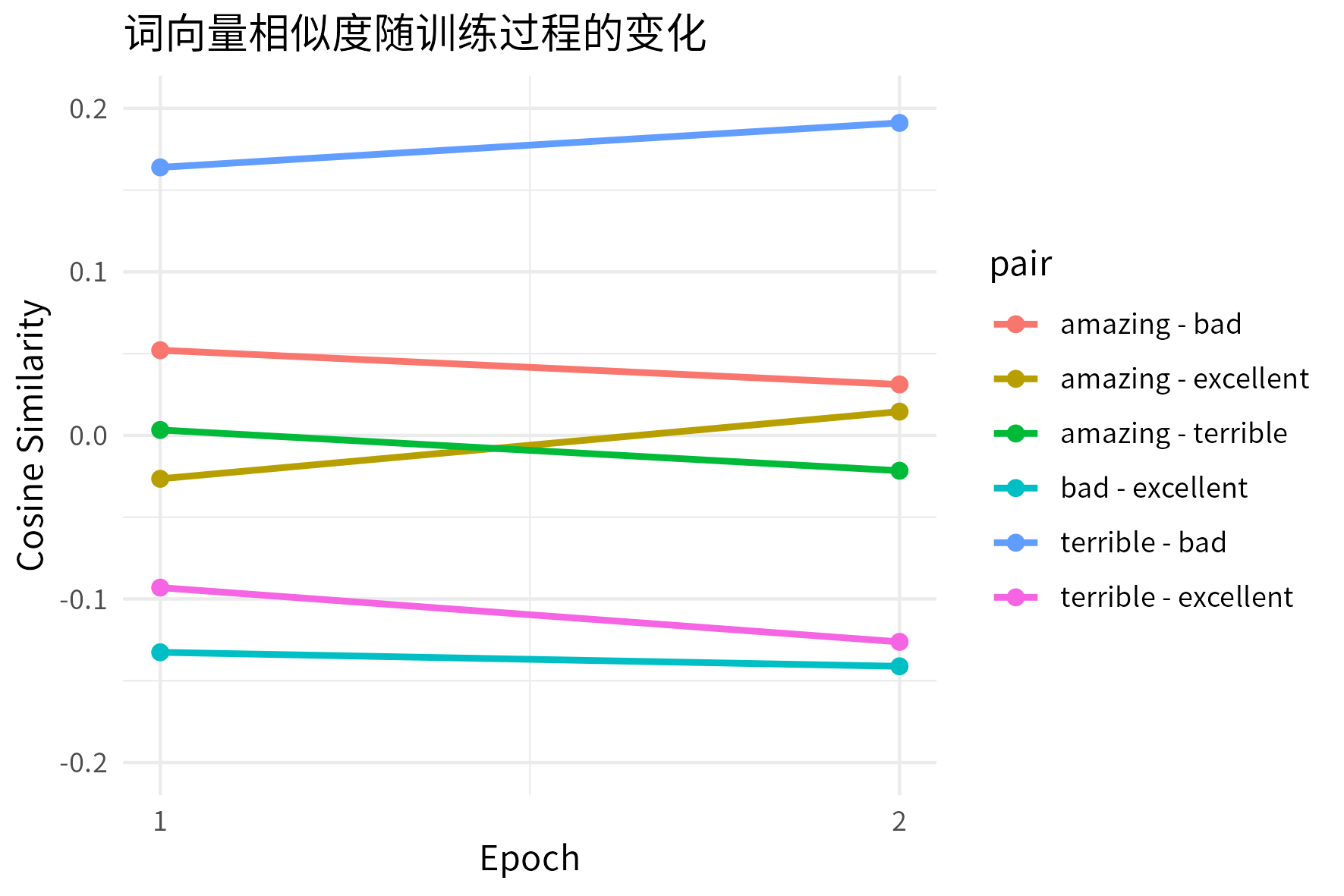
果然,变化的趋势和语义实际关系式一致的:
既然是这样,那么如果每个 token 对应的 embedding 向量是最优,那模型训练的效果会不会更好?
8.5.3.1 引入预训练词向量
这个想法实现的技术路径就是 Embedding Fine-tuning (词向量微调),我们不需要从零开始随机初始化词向量矩阵,而是加载预训练的词向量(如 GloVe 或 Word2Vec)作为 Embedding 层的初始化权重。
已经预训练好的词向量模型有3:
- 来自于斯坦福大学的 GloVe (Global Vectors for Word Representation)
- 来自于 Meta 公司的 FastText
模型利用在大规模语料库上学到的单词语义关系(比如 “amazing” 和 “excellent” 在向量空间本来就很近),在 IMDb 这种相对较小的数据集上做分类问题,可以获得更好的泛化能力。
我们为了让整个模型训练的过程更加透明化,选择了有纯文本词向量提供的 GloVe(Pennington 等 2014) 模型。进入 Stanford NLP Group - GloVe 项目,选择 glove.2024.wikigiga.50d.zip 下载,该数据集包含了基于 2024 年维基百科语料构建的 GloVe 模型,19 亿 tokens, 120 万 vocab 的 50 维词向量,压缩文件大小为 270M。
其中的修改有两个关键点,一个是在模型的 Embedding 层加载预训练的词向量,另一个是在训练时冻结 Embedding 层的参数,不参与反向传播更新。
有两个关键参数的传递:
pretrained_weights:预训练的词向量矩阵。freeze_embeddings:是否冻结 Embedding 层的参数,默认值为FALSE。
首先将下载的压缩包解压到 data/imdb/aclImdb 目录下,并将数据按照要求加载到 R 内存,这里我们利用了 R 高效处理数据的包 data.table,解压后 800M 数据,加上数据格式转化等操作,3-5 秒即可完成。
# --- 加载 GloVe 预训练向量 ---
library(data.table)
load_pretrained_embeddings <- function(
file_path, pipeline, emb_dim = 100) {
glove_dt <- fread(file_path,
header = FALSE,
quote = "",
encoding = "UTF-8",
key = "V1") # 将第一列(单词)设为索引,加速查找
cat(sprintf("GloVe 读取完毕,包含 %d 个词向量。\n", nrow(glove_dt)))
vocab_words <- pipeline$idx_to_token
vocab_size <- length(vocab_words)
my_vocab_dt <- data.table(
word = vocab_words,
idx = 1:vocab_size
)
# glove_dt 的 V1 是词,V2...V101 是向量
matched_dt <- merge(my_vocab_dt, glove_dt,
by.x = "word", by.y = "V1", sort = FALSE)
# 4. 初始化最终权重矩阵
final_matrix <- matrix(
rnorm((vocab_size + 1) * emb_dim, sd = 0.1),
nrow = vocab_size + 1, ncol = emb_dim)
# 将 <PAD> (索引为 1) 设为 0
pad_idx <- pipeline$token_to_idx["<PAD>"]
final_matrix[pad_idx, ] <- 0
# 5. 填入匹配到的 GloVe 权重
indices <- matched_dt$idx
vec_cols <- paste0("V", 2:(emb_dim + 1))
vectors <- as.matrix(matched_dt[, ..vec_cols])
final_matrix[indices, ] <- vectors
cat(sprintf("匹配命中率: %.2f%% (%d/%d)\n",
(nrow(matched_dt) / vocab_size) * 100,
nrow(matched_dt), vocab_size))
rm(glove_dt, matched_dt)
gc()
return(torch_tensor(final_matrix, dtype = torch_float()))
}该函数的逻辑如下:
fread读取 GloVe 预训练向量文件,将第一列设为索引,加速后续查找。- 从
pipeline中提取词汇表,将 GloVe 中匹配到的词向量填充到final_matrix中。 merge将词汇表与 GloVe 数据合并,根据索引填充词向量。- 初始化剩余的词向量为随机值(用于覆盖 GloVe 中没有的词)。
- 返回最终的词向量矩阵。
词表的匹配命中率: 96.76% (19353/20002)。
接下来修改模型,在 Embedding 层加载预训练的词向量,同时设置 freeze_embeddings 参数,默认值为 FALSE,表示不冻结 Embedding 层的参数,参与反向传播更新。
IMDbLSTM <- nn_module(
"IMDbLSTM",
initialize = function(
vocab_size,
emb_dim,
hidden_dim,
pretrained_weights = NULL, # 新增参数
output_dim = 1,
freeze_embeddings = FALSE) { # 是否冻结 embedding 层
self$embedding <- nn_embedding(vocab_size, emb_dim, padding_idx=1)
if (!is.null(pretrained_weights)) {
self$embedding$weight$set_data(pretrained_weights)
self$embedding$weight$requires_grad_( !freeze_embeddings )
}
self$lstm <- nn_lstm(emb_dim,
hidden_dim,
batch_first = TRUE,
bidirectional = TRUE)
self$fc <- nn_linear(hidden_dim * 2, output_dim)
self$dropout <- nn_dropout(0.5)
},
forward = function(x) {
x <- self$embedding(x)
output <- self$lstm(x)
avg_pool <- torch_mean(output[[1]], dim = 2)
self$fc(self$dropout(avg_pool))
}
)为了保持同前面的案例一致可比,我们选择只迭代 5 个 epoch。
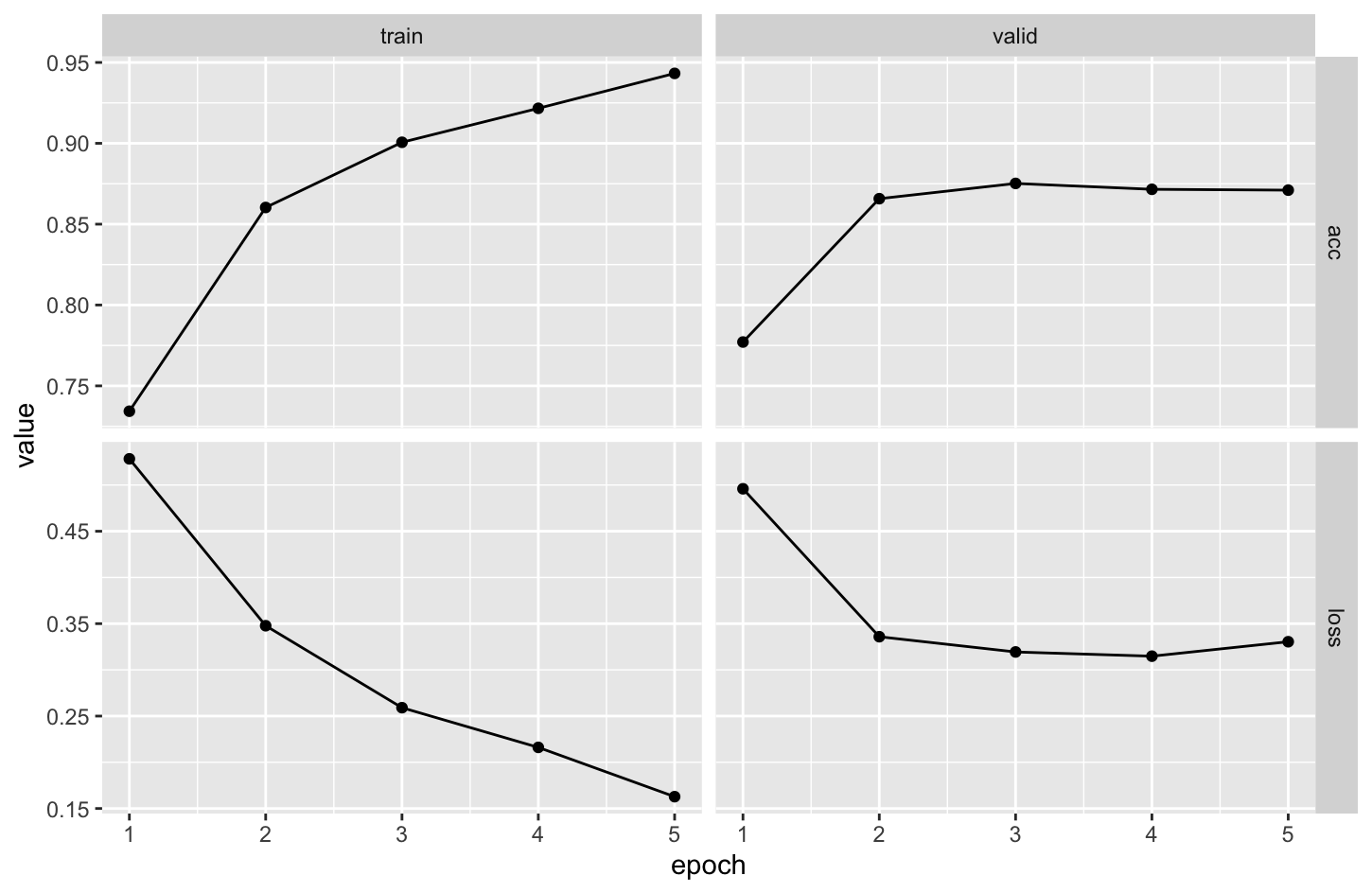
从 valid 数据集上的 acc 可以看到,引入预训练词向量后,模型的泛化能力得到了提升,验证集上的 acc 从 85% 提升到了 87%。
8.6 Seq2Seq 雏形
在前面的章节中,我们要么处理“一对一”的任务(如图像分类),要么处理“多对一”的任务(如文本情感分析),或者是同步的“多对多”任务(时序预测,用统一的 Windows 来预测未来的多个时间步)。
但在现实世界中,最棘手的序列任务往往是非同步的“多对多”(Many-to-Many)映射,且输入和输出序列的长度通常不相等。最典型的例子就是机器翻译(Machine Translation):
- 英文输入:“How are you?” (3个 Token)
- 中文输出:“你好吗?” (3个 Token) 或 “你最近过得怎么样?” (8个 Token)
这种输入序列 (\(X\)) 到输出序列 (\(Y\)) 的映射,且 \(Length(X) \neq Length(Y)\) 的结构,被称为 Seq2Seq(Sequence-to-Sequence) 模型。它是现代自然语言处理的基石,也是连接传统 RNN 与现代 Transformer 的桥梁。
为了解决变长序列的映射问题,Sutskever 等人在 2014 年提出了著名的 Encoder-Decoder 架构。其核心思想非常直观:先压缩,再解压。该架构包含两个独立的 RNN 网络:
1. 编码器 (Encoder):
负责阅读理解者。接收输入序列 \(X = (x_1, x_2, ..., x_T)\),将其一步步处理。但它不产生任何即时输出,而是将输入序列的所有信息压缩成一个上下文向量 (Context Vector, \(c\))。通常,这个 \(c\) 就是编码器 RNN 的最后一个隐状态 (Final Hidden State)。数学表达:
\[ h_t = \text{RNN}_{enc}(x_t, h_{t-1})\]\[c = h_T \]
2. 解码器 (Decoder):
负责创作或翻译。根据上下文向量 \(c\),逐步生成目标序列 \(Y = (y_1, y_2, ..., y_{T'})\)。解码器的初始隐状态通常由 \(c\) 初始化。在生成每个词时,它不仅依赖当前的输入,还依赖上一时刻的隐状态。数学表达:
\[ s_t = \text{RNN}_{dec}(y_{t-1}, s_{t-1}, c) \]
\[ P(y_t | y_{<t}, X) = \text{Softmax}(W \cdot s_t) \]
假设我们使用 LSTM 作为基底,编码器输出包含 output(所有时间步的隐状态)和 (hn, cn)(最后一个时间步的隐状态和细胞状态)。在最基础的 Seq2Seq 模型中,我们丢弃 output,只保留 (hn, cn) 作为 Context Vector,传递给解码器作为初始状态。
Encoder-Decoder 架构存在一个致命的 设计缺陷,这个缺陷直接催生了注意力机制(Attention)的诞生。定长编码的局限性无论输入序列 \(X\) 是 5 个单词还是 500 个单词,Encoder 都被迫将其压缩成一个 固定长度 的向量 \(c\)。
- 信息有损压缩:这就好比要求你读完一本《红楼梦》,然后必须把所有细节、人物关系、情感色彩都浓缩在“一句话”里传给另一个人,让他根据这句话把《红楼梦》复写出来。显然,大量细节会丢失。
- 长距离遗忘:对于长句子,RNN 固有的梯度消失问题,使得 Context Vector 往往只记住了句子末尾的信息,而遗忘了句子开头的信息。
- 对齐困难:在翻译时,输出的某个词通常只与输入的某几个词强相关(例如 “Hello” 对应 “你好”)。但在基础 Seq2Seq 中,解码器在生成每个词时,面对的都是同一个静态的 \(c\),无法区分输入的重点。
如果解码器在生成翻译时,不仅仅是盯着那个死板的上下文向量 \(c\),而是拥有“透视眼”,能够回头看(Attend to) 编码器的所有原始隐状态 \((h_1, h_2, ..., h_T)\),并且根据当前翻译的需要,动态地聚焦于最相关的输入词,会发生什么?这正是注意力机制(Attention)的起源。它将把这一节的静态 Context Vector 变成动态计算的 Context Vector,从而彻底引爆了深度学习领域,并最终导向了 Transformer 架构。我们将在下一章详细推导并从零实现这一革命性的技术。