15 生产部署
“网络是广阔且无边的。”
—— 《攻壳机动队》(1995)
草薙素子站在高楼顶端,俯瞰着庞大而璀璨的城市网络。随后她纵身一跃,身体在空中隐形,意识却已接入了无处不在的数据洪流,无论何处,她无所不在。
15.1 模型持久化
模型训练完成不是终点,而是起点。 部署(Deployment)就是让你的模型像素子一样,跳出实验室的躯壳,通过 Docker 和 API,接入广阔的互联网生产环境。在真实的数据洪流中,模型才真正获得了生命。
在 R torch 中 有三种模型持久化的方式,适应于不同场景。
15.1.1 torch_save
该函数可以保存我们已经训练好的模型。但在生产环境中,保存方式的选择决定了模型使用上的不同。
torch_save(model, "model.pt"):保存全量模型 (The Whole Object):
- 利用 R 的序列化机制,将整个 R6 对象打包,包括代码结构、参数、优化器状态。
- 它依赖于具体的代码环境。如果你修改了模型类的定义,或者在另一台没有加载该类定义的机器上加载,代码会直接报错。
torch_save(model$state_dict(), "weights.pt"):保存状态字典1,较为常用。
- 只保存参数张量的字典(
Map<String, Tensor>)。 - 它不仅文件体积更小,而且允许你在加载时灵活调整模型结构(例如,加载预训练权重到稍微修改过的网络中)。
持久化的对象可以通过 torch_load 函数加载。
# 需要提前载入 model 的定义
weights <- torch_load('data/13_model_weights.pt')
model$load_state_dict(weights)15.1.2 ONNX 标准
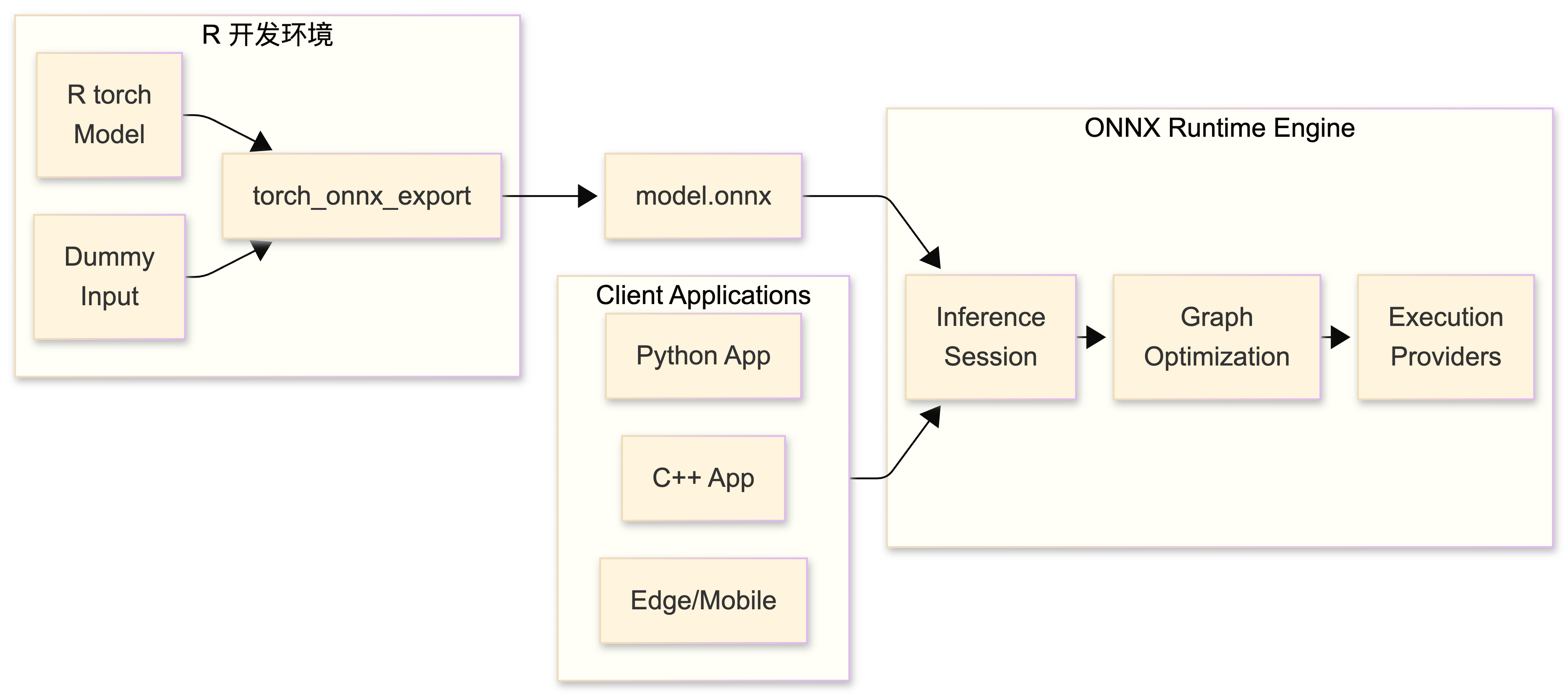
R 语言在统计分析领域是王者,但在边缘计算设备或高并发微服务架构中,C++ 和 Python (PyTorch/TensorRT) 占据主导。如何让 R 训练的模型在这些环境中运行?答案是 ONNX (Open Neural Network Exchange)。
ONNX 是一种通用的中间格式。你可以把它想象成深度学习界的“PDF”——无论你在 Word (R torch) 还是 Pages (PyTorch) 中编写文档,导出为 PDF (ONNX) 后,任何阅读器都能打开。
生产互动
library(torch)
# 1. 定义并实例化模型
model <- nn_sequential(
nn_linear(10, 20),
nn_relu(),
nn_linear(20, 1)
)
model$eval() # 必须切换到评估模式
# 2. 创建一个虚拟输入 (Dummy Input)
# ONNX 导出器需要通过一次实际的前向传播来追踪计算图
dummy_input <- torch_randn(1, 10)
# 3. 导出模型
torch_onnx_export(
model,
dummy_input,
"my_model.onnx",
input_names = list("input_features"),
output_names = list("prediction")
)使用场景:
- 导出的
.onnx文件可以使用 ONNX Runtime (C++) 加载,通常比原生的 R torch 推理快 2-5 倍。 - Python 工程师可以直接加载你训练的模型,无需安装 R 环境。
15.1.3 TorchScript (JIT)
除了 ONNX,Torch 还有一个原生的序列化方案:TorchScript (Just-In-Time)。这个即时编译的方案目标是脱离 Python/R 的解释器依赖,直接在 libtorch (C++) 环境中运行。
- Tracing (追踪):记录输入张量流经网络的路径。
- Scripting (脚本化):分析源代码逻辑(目前 R torch 主要支持 Tracing)。
# JIT 追踪示例
traced_model <- jit_trace(model, dummy_input)
# 保存为脚本模型,这可以在 C++ 程序中直接加载
jit_save(traced_model, "model_scripted.pt")15.2 脚本到微服务
模型训练好了,如何让网页端或手机 App 调用它?我们需要将其封装为 REST API2。建议有两种方案可考虑 Plumber 和 RestRserve。
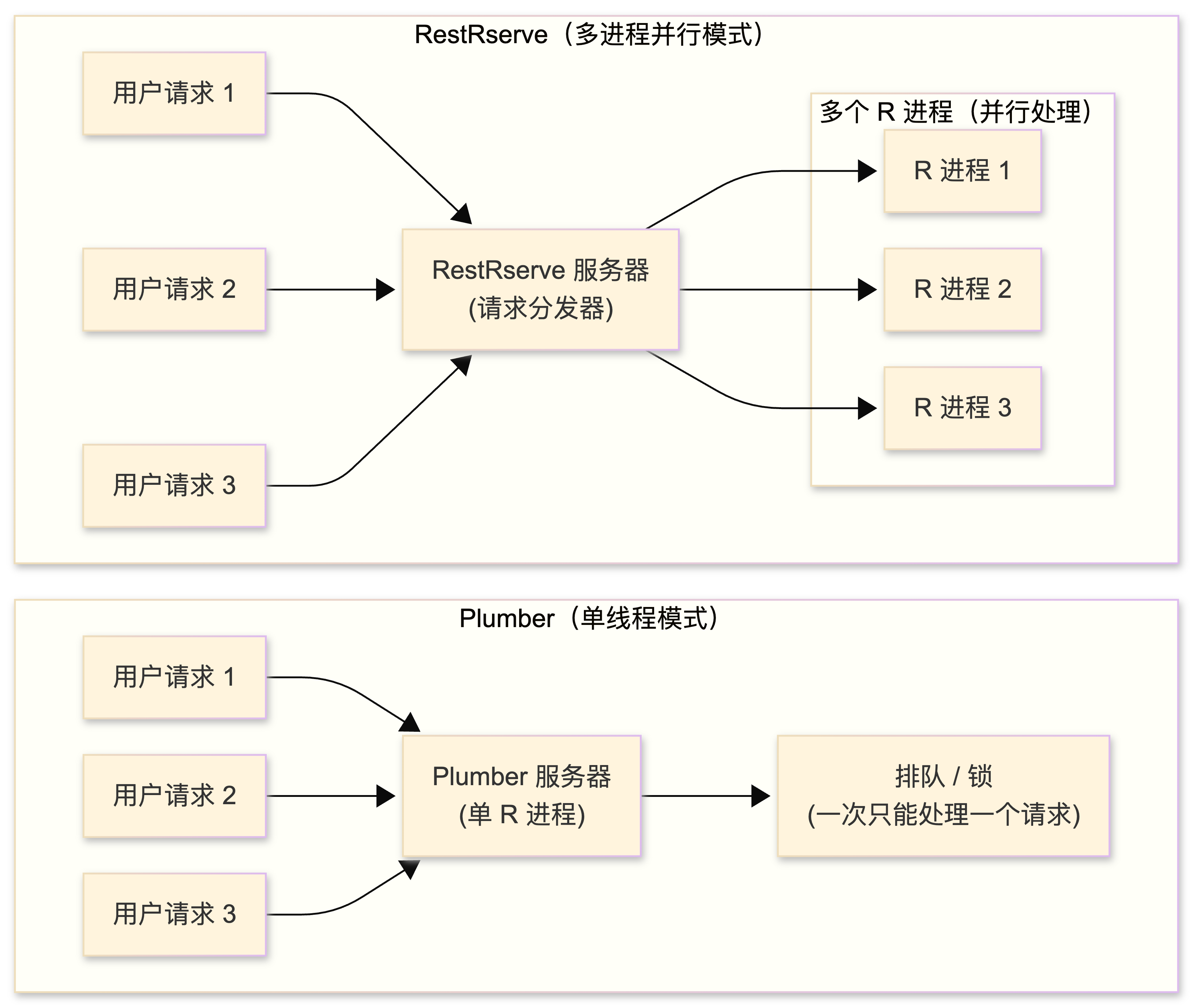
Plumber:
- R 生态中最流行的 API 框架,通过特殊的注释 (
#* @get /predict) 定义接口。 - 语法极其简单,与 RStudio 集成完美。基于单线程,处理高并发请求时容易阻塞,适合构造小型应用或演示。
RestRserve:
- 专为高并发生产环境设计的 R Web 服务器。
- 支持 Unix
fork()多进程后端。这意味着它可以同时启动多个 R 进程处理请求,充分利用多核 CPU,且是非阻塞的,从而实现并发处理。对于计算密集型任务,RestRserve 是更专业的选择。
当然虽然 RestRserve 性能非常优秀,但也是有代价的。你在开发过程中需要处理线程冲突、零拷贝策略的调整3、二进制文件处理等非常底层的逻辑。相对而言,plumber 帮你封装了很多脏活累活,语法和逻辑简单很多。
因此简化起见,我们将 plumber 框架以及上一节 Grad-CAM 方法找到 resnet18 的特征图的机制,构建一个标准的推理服务:
接收一个图片 -> 预处理 -> 推理特征图(并返回分类) -> 返回 JSON
有两个核心函数:
utils.R:包含模型定义、预处理函数等。内容同上一章,不做赘述。server_plumber.R:包含 resnet18 模型加载、预处理、推理、返回 JSON 的逻辑。提供/explain接口,接收图片文件,返回分类结果和 Grad-CAM 可视化。
server_plumber.R 的代码量很低:
#!/usr/bin/env Rscript
library(plumber)
source("utils.R")
device <- torch_device("cpu")
model <- model_resnet18(pretrained = TRUE)
model$eval() # 记得设为 eval 模式
target_conv <- model$layer4[[2]]$children$conv2
spy_layer <- SpyModule(target_conv)
model$layer4[[2]]$add_module("conv2", spy_layer)
# 辅助函数 (获取路径)
get_image_path <- function(img_obj) {
if (!is.null(img_obj$datapath)) return(img_obj$datapath)
tmp <- tempfile(fileext = ".jpg")
writeBin(img_obj[[1]], tmp)
return(tmp)
}
# --- 路由定义 (带注释) ---
#* @apiTitle Grad-CAM Explainer
#* @apiDescription 上传图片,返回 JSON 结果
#* 上传图片并解释
#* @param image:file 上传图片文件
#* @post /explain
#* @serializer json
function(req, image) {
img_path <- get_image_path(image)
tryCatch({
generate_gradcam(model, spy_layer, img_path, device)
}, error = function(e) list(error = e$message))
}终端中运行 server 并指定端口号:
> plumber::pr('server_plumber.R') |> plumber::pr_run(port=8080)
Model weights for <resnet18> (~45 MB) will be downloaded and
processed if not already available.
Running plumber API at http://127.0.0.1:8080
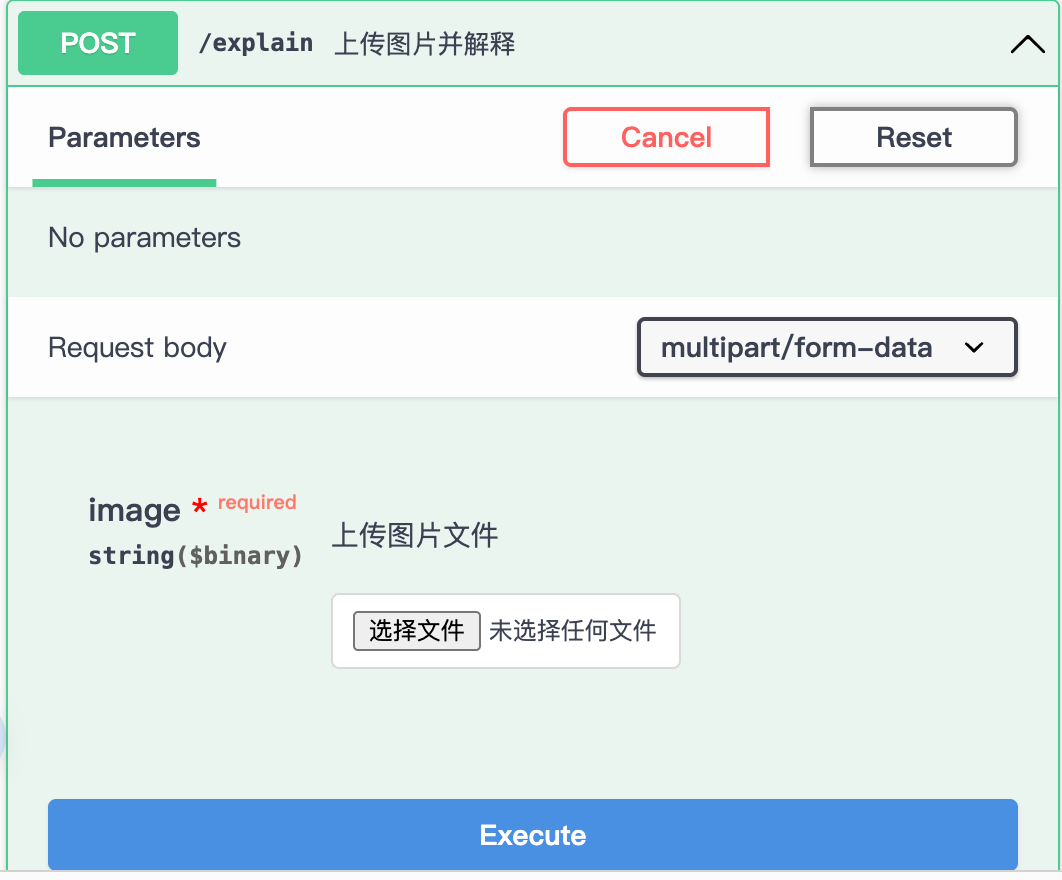
Running swagger Docs at http://127.0.0.1:8080/__docs__/服务启动之后可以在 Swagger UI 查看 API 文档,在这个页面可以很便捷的 debug API。
也可以构建一个直接访问服务的测试脚本,server 接口会返回 JSON 结果:
library(httr)
library(jsonlite)
api_url <- "http://127.0.0.1:8000/explain"
# image_path <- "your_file.jpg"
image_path <- "/Users/liusizhe/Desktop/ILSVRC2012_val_00023573.jpeg"
resp <- POST(
url = api_url,
body = list(image = upload_file(image_path)),
encode = "multipart"
)
content(resp)
#$class_idx
#$class_idx[[1]]
#[1] "golden retriever"
#$image_base64
#$image_base64[[1]]
#[1] "iVBORw0KGgoAAAANSUhE ... <truncated>也可以使用 k6 开启 5 个并发做一个 30s 接口测试:
k6 run --vus 5 --duration 30s k6-test.jsRestRserve4 和 plumber 两种方式的接口响应性能如下:
| 指标 | RestRserve | Plumber |
|---|---|---|
| 总完成请求数 | 1065 | 340 |
| 每秒吞吐量 (QPS) | 35.39 | 11.20 |
| 中位数延迟 (med) | 137.88ms | 440.33ms |
| 95% 分位数延迟 (p95) | 163.5ms | 493.75ms |
| 数据吞吐速度 (Sent) | 5.0 MB/s | 1.6 MB/s |
15.3 容器化 (Docker)
“在我的电脑上能跑,但在服务器上报错”,这是依赖管理的噩梦。Docker 的出现解决了这一痛点:它将操作系统、R 环境、底层系统库(如 LibTorch)以及你的代码打包在一个独立的“容器”中,确保了从开发到生产环境的高度一致性。
15.3.1 编写 Dockerfile
Dockerfile 是构建镜像的蓝图。每个指令都定义了构建过程中的一步:
- FROM: 指定基础镜像,即构建的起点。
- RUN: 在镜像构建过程中执行命令(如安装软件)。
- WORKDIR: 设置工作目录,后续指令都会基于此目录执行。
- COPY: 将本地文件复制到镜像中。
- EXPOSE: 声明服务端口(仅作文档用途,实际映射需在运行时指定)。
- CMD: 定义容器启动后默认执行的命令。
针对深度学习 API,我们需要构建一个包含 R 环境、系统依赖库以及 LibTorch 的镜像(假设你已经配置好依赖和网络环境)。
代码清单:构建 R 深度学习镜像 (Dockerfile)
# 1. 基础镜像:强制指定 linux/amd64 架构
FROM --platform=linux/amd64 rocker/r-ver:4.5.2
# 2. 编译 R 包和处理图像所需的底层库
RUN apt-get update && apt-get install -y --no-install-recommends \
libcurl4-openssl-dev \
libgit2-dev \
libjpeg-dev \
libmagick++-dev \
libpng-dev \
libssl-dev \
libtiff-dev \
libxml2-dev \
&& rm -rf /var/lib/apt/lists/*
# 3. 安装 R 包
RUN R -e " \
pkgs <- c('rlang', 'ellipsis', 'coro', 'jsonlite', \
'magick', 'RestRserve', 'base64enc', \
'curl', 'torch', 'torchvision'); \
install.packages(pkgs, dependencies = TRUE) \
"
# 4. R 的 torch 包只是接口,此步用于下载几百 MB 的 LibTorch 核心库
RUN R -e "torch::install_torch()"
# 5. 注入应用代码
WORKDIR /app
COPY server_RestRserve.R utils.R label_list.json ./
# 6. 启动配置
EXPOSE 8000
CMD ["Rscript", "server_RestRserve.R"]细心的读者会发现,我们在 FROM 指令中添加了 --platform=linux/amd64。这是基于实战经验的考量:
随着 Apple M 系列芯片(ARM64 架构)的普及,开发者的本地环境常与云端服务器(通常是 x86_64 架构)不一致。R 的 torch 依赖底层的 LibTorch C++ 库。如果在 Mac 上不指定平台构建,Docker 默认会拉取 ARM 版镜像并下载 ARM 版 LibTorch。这会导致镜像推送到云服务器后,因二进制架构不兼容而崩溃(Segmentation Fault)。
为了保证 x86 云服务器绝对的兼容性,我们显式地锁定了架构,确保镜像“一次构建,处处运行”。
15.3.2 一键部署
构建并运行容器非常简单。无论是在 AWS、阿里云还是本地测试,只需以下两条命令:
# 1. 构建镜像
# -t 标记镜像名称为 my-torch-api
# 注意最后的点 (.) 代表使用当前目录下的 Dockerfile
docker build -t my-torch-api .
# 2. 运行容器
# -d: 后台运行 (Detached mode)
# -p 8080:8000: 将容器内的 8000 端口映射到宿主机的 8080 端口
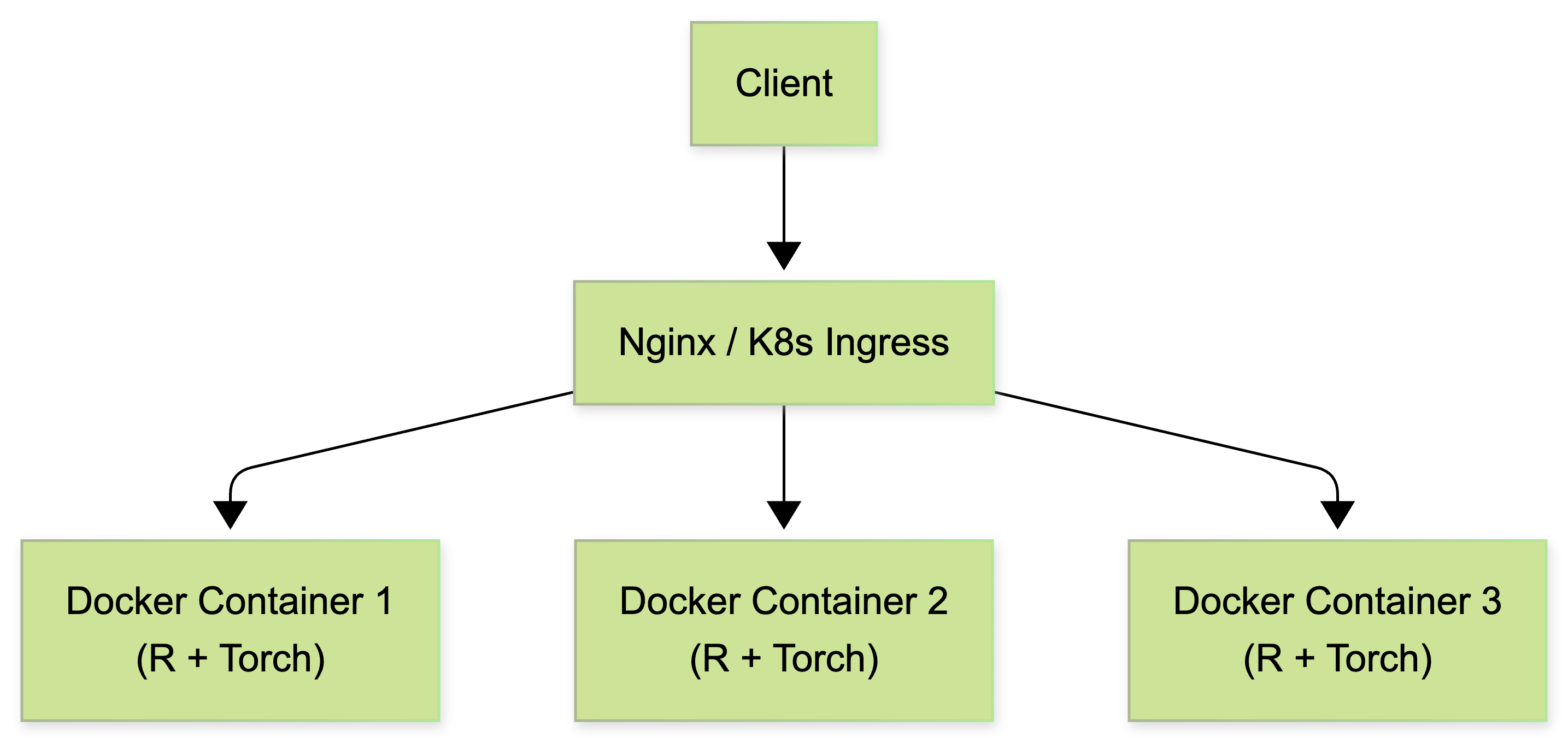
docker run -d -p 8080:8000 --name torch_service my-torch-api在将 R 深度学习服务推向生产环境时,我们推荐“多容器、单进程”的策略,而非在 R 内部进行多线程并发。
这里存在一个隐蔽的技术风险:OpenMP 与 Fork 的死锁问题。 许多 R 的底层库(包括 torch 和 magick)在 C++ 层面使用了 OpenMP 进行多线程加速。而在 Linux 下,RestRserve 等 Web 框架常用 fork() 系统调用来实现并发。
当父进程的 OpenMP 线程池正在运行时执行 fork(),子进程只复制了调用 fork 的那个线程,其他线程“凭空消失”,导致内存锁的状态不一致。这极易引发死锁 (Deadlock),导致服务无响应。
解决方案是,在 Linux 主机上,将 Docker 容器作为最小隔离单元。
- 每个 R 进程只使用单线程(或限制 OpenMP 线程数),仅处理一个请求。
- 通过启动多个 Docker 容器副本(Replicas)来应对高并发。
- 利用 Kubernetes (K8s) 或 Docker Swarm 进行负载均衡。
对于超高并发的工业级场景,更通用的方案是将 Web 业务逻辑与 AI 推理逻辑解耦。例如,使用 NVIDIA Triton5 专门负责模型推理,使用 Java 负责业务胶水层,甚至还需要各类负载均衡等策略。R 并不是为了适配高性能业务系统而设计,如果你没有强大后端团队支持,QPS 不过 20-30 个,那么上述框架是你快速落地的方便之选。
15.4 Shiny App
如果你想让你的模型不仅能被机器(代码)调用,还能被人类(非技术人员)直接交互,R Shiny 框架是不二之选。在这一节,我们将结合前面所讲的知识,构建一个“交互式生成艺术工坊”。
我们将设计一个直观的 Web 应用:用户上传图片,后台模型不仅告知分类结果,还能通过 Grad-CAM 绘制出模型的“注意力地图”,让用户看到模型究竟在看哪里。
核心交互逻辑非常清晰:前端负责接收与展示,后端负责推理与生成。
- 用户在 Shiny 端上传一张本地图片。
- Shiny 将图片打包,发送给正在运行的 Plumber/RestRserve 后端服务。
- 后端进行模型推理,返回分类结果和 Grad-CAM 热力图(Base64 编码)。
- Shiny 解析返回结果,将原始图、热力图和预测文本并排展示。
基本架构图如下:

后端服务我们已经在前面小节实现,这里只需要在补充一个完整的 UI,进行交互呈现即可。这个 UI 不复杂,主要模块包括:
- 文件上传组件,用于用户上传图片。
- 提交按钮,用于触发图片处理。
- 图片展示区域,用于显示上传的图片。
- 分类结果展示区域,用于显示模型的分类结果。
- Grad-CAM 可视化展示区域,用于显示生成的注意力可视化。
成品 Shiny App 的样式如下所示:

一般的 Shiny App 结构主要由两部分构成,分别是 UI 和 Server,我们先看 UI 如何构建。
15.4.1 构建 UI
页面需要引入 shiny, httr (用于API请求) 和 base64enc (用于图片编码) 包。
整个 UI 被包裹在 fluidPage 中,是经典的 sidebarLayout 布局:左侧为控制区 sidebarLayout,右侧为展示区 mainPanel。
先是文件上传组件和提交按钮的控制区 sidebarLayout,我们还贴心地加了一行提示,防止用户忘记启动后端服务。
sidebarPanel(
fileInput("upload", "上传一张图片 (jpg/png)",
accept = c("image/jpeg", "image/png")),
actionButton("analyze", "开始分析", class = "btn-primary"),
hr(),
helpText("提示:请确保后台 Plumber 服务已在 8000 端口启动。")
)再是右边的展示区 mainPanel,设置了两个 column 和一个 textOutput,分别展示原始图片、 Grad-CAM 注意力可视化以及模型的预测结果:
mainPanel(
fluidRow(
column(6,
h4("原始图片"),
uiOutput("orig_ui")
),
column(6,
h4("模型注意力 (Grad-CAM)"),
uiOutput("cam_ui")
)
),
hr(),
h4(textOutput("pred_text")) #稍微加大字体
)以上,UI 定义完成。
15.4.2 定义 Server 端
Server 端是一个巨大的 function(input, output, session)。用户点击“开始分析”时,触发 API 请求,这里使用 eventReactive 来监听按钮点击。当用户点击分析按钮时,将图片以临时文件的方式打包通过 POST 请求,发送至后端的推理服务:
api_response <- eventReactive(input$analyze, {
req(input$upload)
# 构造上传请求
# input$upload$datapath 是 Shiny 保存的临时文件路径
resp <- tryCatch({
POST(
url = "http://127.0.0.1:8080/explain",
body = list(image = upload_file(input$upload$datapath)),
encode = "multipart"
)
}, error = function(e) {
showNotification(paste("连接 API 失败:", e$message), type = "error")
return(NULL)
})
content(resp, as = "parsed")
})拿到 api_response 后,我们需要分别渲染三部分内容。
一、显示原始图片:
output$orig_ui <- renderUI({
req(input$upload)
tags$img(src = base64uri(input$upload$datapath), width = "100%")
})二、展示 Grad-CAM 图片:
output$cam_ui <- renderUI({
res <- api_response()
req(res)
# 构造 Base64 图片标签
tags$img(src = paste0("data:image/png;base64,",
res$image_base64), width = "100%")
})三、展示预测类别:
output$pred_text <- renderText({
res <- api_response()
req(res)
paste("该图片的预测类别是:", res$class_idx)
})至此,Shiny App 的 UI 和 Server 端逻辑都已完成。以上代码整合在 app.R 文件中,先启动 plumber 服务(或通过 docker 镜像启动 RestRserve 服务),再执行 app.R 即可得到本节开头展示的成品。
更多的 demo 的图片可以在这里下载:Kaggle Imagenet Mini 1000
至此,《R torch 深度学习精解与实践》的正文部分圆满结束。现在,去构建属于你的智能应用吧!