13 扩散模型
“有时你看到的只是一团乱麻。你得凑近了看。”
—— 《少数派报告》 (2002)
在预防犯罪局,巨大的全息屏幕上最初显示着杂乱无章、像液体般流动的噪点与光影。安德顿警官挥舞双手,像指挥家一样对这些混乱的数据流进行抓取、回溯和聚焦,最终,原本模糊的噪点逐渐凝聚,显露出一张清晰的行凶者面孔。
13.1 熵增与时间倒流
本章我们将抛开复杂的工程细节,通过一个精简的 2D 点云案例,带你理解现代生成式 AI —— 扩散模型(Diffusion Models)背后的数学之美。
想象一滴浓墨水滴入一杯清水中。
随着时间的推移,墨水分子会因为布朗运动(Brownian Motion)无序地扩散到整杯水中。最终,这杯水变成了一杯均匀的浅灰色液体。这个过程伴随着熵增(Entropy Increase):原本清晰的结构(墨滴)逐渐瓦解,信息逐渐丢失,最终变成了彻底的无序(噪声)。
扩散模型的核心思想非常浪漫:如果我们能录下墨水扩散的全过程,然后倒着播放录像,会发生什么?
我们会看到一杯浑浊的灰色液体,其中的墨水分子仿佛受到了某种力量的召唤,违背热力学定律,逐渐汇聚,最后奇迹般地还原成一滴清晰的墨水。这就是扩散模型想要做的事情:学习如何逆转熵增的过程。
在深度学习的语境下,我们将这个过程形式化为两个阶段:
- 前向过程 (Forward Process / Diffusion Process):这是一个单纯的“破坏”过程。我们一点点往图片上撒“高斯噪声”。随着步数 \(t\) 的增加,图片逐渐模糊,直到 \(t=T\) 时,图片完全变成了一张毫无意义的“雪花屏”(标准高斯噪声分布)。这一步不需要训练神经网络,完全由数学公式控制。
- 逆向过程 (Reverse Process / Denoising Process):这是一个“创造”过程。如果有一张全是噪点的图,我们无法直接还原原图。但如果我们训练一个神经网络,教它只还原“这一小步”呢?网络只需要学会:看着 \(t\) 时刻的图,猜出这一步加了多少噪,然后剔除这点噪声得到 \(t-1\) 时刻的图。如此反复多步,就能从纯噪声中“雕刻”出清晰的图像。
早期的研究试图让神经网络直接预测“去噪后的图像 \(x_{t-1}\)”,但这非常困难,因为从模糊到清晰的可能性太多了。
2020 年,DDPM (Denoising Diffusion Probabilistic Models) 论文提出了一个天才般的简化:
不要预测图像,而是预测噪声。
与其让网络画出“原本的画”,不如让网络指出“当前的画里哪里是干扰”。如果网络能准确识别出当前图像中包含的噪声 \(\epsilon\),我们就可以用当前图像减去这个预测出的噪声,从而得到稍微清晰一点的图像。
13.2 核心公式
在接下来的代码实现中,你需要掌握两个最关键的数学公式。不用担心复杂的推导,我们只关注如何用。
(1) 前向加噪公式(任意时刻的捷径)
要在第 \(t\) 步得到加噪后的图像 \(x_t\),我们不需要写一个循环一步步加噪。通过数学上的重参数化技巧 (Reparameterization Trick),我们可以一次性算出结果:
\[ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \]
这个公式非常直观:
- \(x_0\) 是原始的清晰图像(信号)。
- \(\epsilon \sim \mathcal{N}(0, I)\) 是我们随机采样的标准高斯噪声。
- \(\sqrt{\bar{\alpha}_t}\) 是信号系数:随着时间 \(t\) 变大,它越来越小(原图看不清了)。
- \(\sqrt{1 - \bar{\alpha}_t}\) 是噪声系数:随着时间 \(t\) 变大,它越来越大(噪声占主导)。
注意:\(\bar{\alpha}_t\) 是由一个预先定义好的“调度表”(Schedule)决定的常数,不是网络学习出来的参数。
(2) 损失函数(Loss Function)
虽然扩散模型背后的数学推导涉及变分下界(ELBO),但落实到代码上,其 Loss 函数惊人地简单——本质上就是一个均方误差 (MSE):
\[ L = || \epsilon - \epsilon_\theta(x_t, t) ||^2 \]
这是一个典型的监督学习任务:
- \(\epsilon\)(真值):我们在前向过程中手动加进去的、真实的噪声。
- \(\epsilon_\theta(x_t, t)\)(预测值):神经网络看着加噪后的图 \(x_t\) 和当前时间步 \(t\),预测出来的噪声。
一句话总结:训练扩散模型,其实就是在训练一个对时间敏感的去噪器。它并不直接产生图像,而是学会了如何把不需要的“杂质”(噪声)挑出来。理解了这两个公式,你就已经掌握了扩散模型的 80%。下一节,我们将使用 R 语言和 torch 从零实现它。
13.3 从零构建 Diffusion
在编写代码之前,我们需要明确本节的工程目标。本案例不处理高维像素图像(这通常需要引入 U-Net 等卷积架构),而是专注于 二维点云生成(2D Point Cloud Generation)。
我们的目标是训练一个神经网络,学习 R Logo 的空间概率分布 \(q(x)\)。
- 输入域 (Input Domain):服从标准正态分布的二维随机噪声 \(z \sim \mathcal{N}(0, I)\)。
- 目标域 (Target Domain):一组在二维平面上构成了 R Logo 形状的点集 \(x \sim q_{data}\)。
机制:
- 前向过程:将 R Logo 的坐标点 \(x_0\) 逐步混合高斯噪声,直至其退化为纯噪声 \(x_T\)。
- 逆向过程:训练一个参数化的神经网络 \(\epsilon_\theta(x_t, t)\)。给定任意时刻 \(t\) 的噪声点坐标 \(x_t\),网络需预测该位置包含的噪声分量,从而引导点向数据流形(Data Manifold)靠拢。
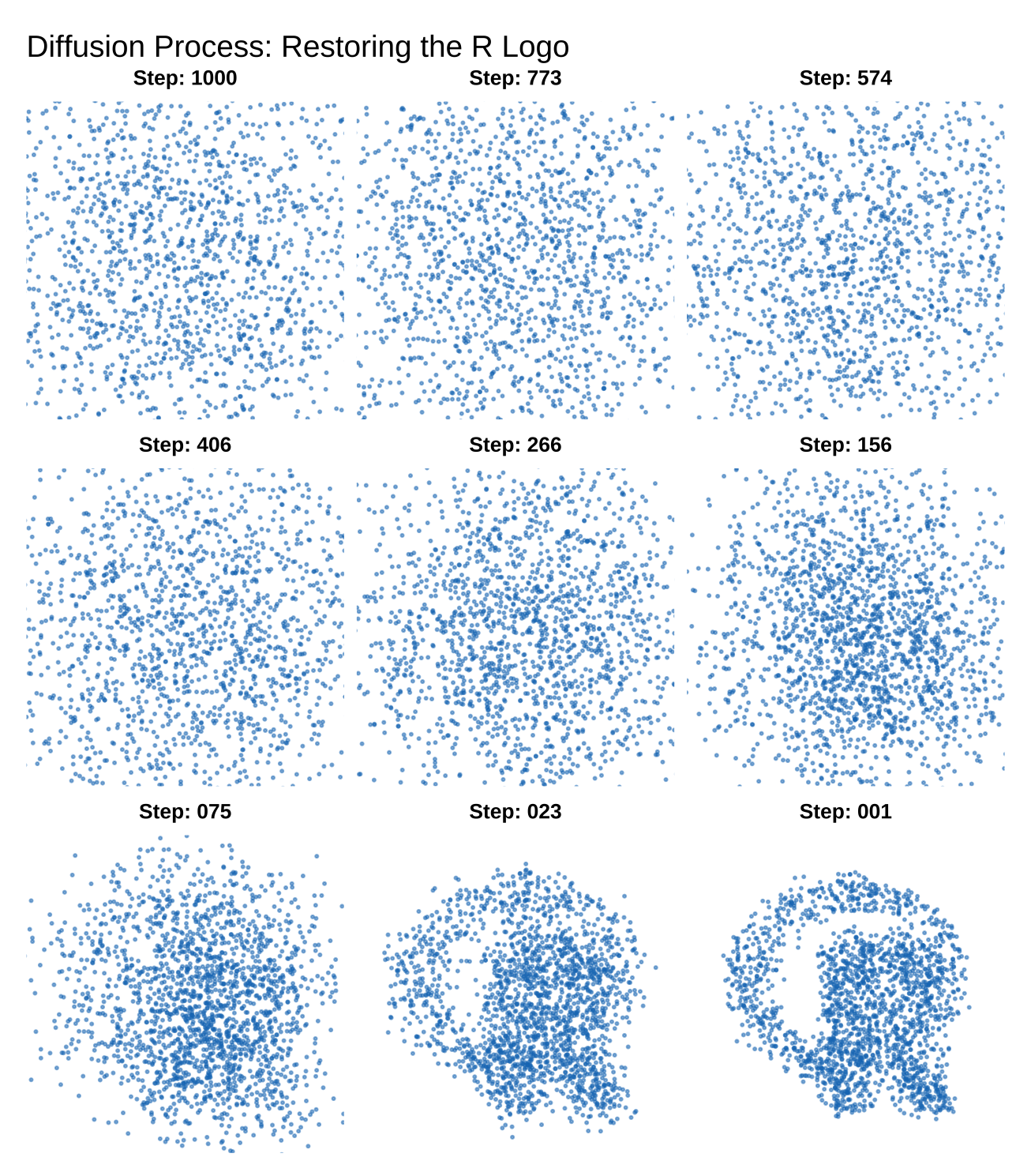
最后将二维坐标的变化轨迹在平面直角坐标系中画出。观察数据点是如何从无序的混沌状态,经过迭代采样,逐渐坍缩到有序的目标分布上的。
为什么选择点云而非图像作为入门案例?原因是处理图像通常需要 CNN 或 Attention 机制,而处理二维坐标只需最基础的 MLP(多层感知机)。这能让我们将注意力完全集中在扩散模型的数学原理(加噪/去噪调度)上,而非网络结构设计上。
代码将拆解为四个逻辑模块:
- 实现线性调度器(Linear Schedule)与加噪公式,为训练提供监督信号。
- 搭建一个具备时间感知能力(Time-Embedding)的 MLP 神经网络。
- 实现 DDPM 的迭代采样算法的训练
- 完成从纯噪声到结构化数据的逆向采样。
13.3.1 调度器和加噪
首先利用 magick 包,将 R logo 图片读入,转化为灰度图,归一化到 [-1, 1] 之间,最后再增加一些随机抖动。样子是这样的:

这是扩散模型的时间表。我们定义总步数 n_steps = 1000。我们会生成一个从 0.0001 到 0.02 线性增长的 \(\beta\) 序列。随着时间推移,加入的噪声方差越来越大。
同时,我们实现前向加噪函数 q_sample,它对应数学公式:\(x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon\)。
n_steps <- 1000 # 增加步数以获得更高清的细节
# 线性调度 (Linear Schedule)
# 噪声方差 beta 从 0.0001 线性增加到 0.02
betas <- torch_linspace(1e-4, 0.02, n_steps)$to(device = device)
# 计算 alpha 及其累乘 (Pre-calculate Alphas)
alphas <- 1 - betas
alphas_bar <- torch_cumprod(alphas, dim = 1)
# --- 前向过程 (Forward / q_sample) ---
# 公式:x_t = sqrt(alpha_bar) * x0 + sqrt(1 - alpha_bar) * epsilon
# 输入:x0 (原图), t (时间步)
# 输出:xt (加噪图), noise (真值)
q_sample <- function(x0, t) {
# 生成标准高斯噪声
noise <- torch_randn_like(x0)
# 提取对应时间步的系数,并调整形状为 (batch, 1) 以便广播
sqrt_ab <- torch_sqrt(alphas_bar[t])$view(c(-1, 1))
sqrt_one_minus_ab <- torch_sqrt(1 - alphas_bar[t])$view(c(-1, 1))
# 直接计算任意时刻的加噪图像
xt <- sqrt_ab * x0 + sqrt_one_minus_ab * noise
list(xt = xt, noise = noise)
}betas(\(\beta\)):控制每一步加多少噪声。这里使用线性调度 (torch_linspace) 从 0.0001 到 0.02。alphas(\(\alpha\)):\(\alpha_t = 1 - \beta_t\)。alphas_bar(\(\bar{\alpha}\)):torch_cumprod 计算累乘。这允许我们直接跳到第 \(t\) 步,计算出 \(x_t\)(加噪后的图像),而不需要一步步循环加噪。
13.3.2 搭建神经网络
我们的模型是一个简单的 MLP(多层感知机),但它有一个特殊能力:时间感知。 通过 PositionEmbeddings,我们将时间 \(t\)(一个整数)转换成一个高维向量,并注入到网络的每一层中。这让网络能根据噪声的强度动态调整去噪策略。
# 把时间 t 翻译成向量,原理同 transformer 章节
PositionEmbeddings <- nn_module(
"PositionEmbeddings",
initialize = function(dim) {
self$dim <- dim
},
forward = function(time) {
device <- time$device
half_dim <- self$dim %/% 2
embeddings <- log(10000) / (half_dim - 1)
embeddings <- torch_exp(
torch_arange(0, half_dim - 1, device = device) * -embeddings)
embeddings <- time$unsqueeze(2) * embeddings$unsqueeze(1)
torch_cat(list(torch_sin(embeddings),
torch_cos(embeddings)), dim = -1)
}
)
# 时间感知残差块,做了残差直连
TimeAwareResBlock <- nn_module(
"TimeAwareResBlock",
initialize = function(hidden_dim, time_dim, dropout = 0.1) {
self$mlp1 <- nn_sequential(nn_layer_norm(hidden_dim),
nn_gelu(),
nn_linear(hidden_dim, hidden_dim))
self$time_proj <- nn_sequential(nn_gelu(),
nn_linear(time_dim, hidden_dim)
) # 投影时间
self$mlp2 <- nn_sequential(
nn_layer_norm(hidden_dim),
nn_gelu(),
nn_dropout(dropout),
nn_linear(hidden_dim, hidden_dim)
)
},
forward = function(x, t_emb) {
h <- self$mlp1(x)
h <- h + self$time_proj(t_emb) # 注入时间
x + self$mlp2(h) # 残差连接
}
)
# 主模型是噪声预测器
NoisePredictor <- nn_module(
"NoisePredictor",
initialize = function(dim_in = 2,
time_dim = 64,
hidden_dim = 256,
num_blocks = 3) {
self$input_proj <- nn_linear(dim_in, hidden_dim)
self$time_mlp <- nn_sequential(
PositionEmbeddings(time_dim),
nn_linear(time_dim, time_dim * 4),
nn_gelu(),
nn_linear(time_dim * 4, time_dim)
)
self$blocks <- nn_module_list()
for (i in 1:num_blocks)
self$blocks$append(TimeAwareResBlock(hidden_dim, time_dim))
self$final_mlp <- nn_sequential(nn_layer_norm(hidden_dim),
nn_gelu(),
nn_linear(hidden_dim, dim_in))
},
forward = function(x, t) {
t_emb <- self$time_mlp(t$to(dtype = torch_float()))
x <- self$input_proj(x)
for (i in 1:length(self$blocks))
x <- self$blocks[[i]](x, t_emb)
self$final_mlp(x)
}
)13.3.3 模型训练
训练过程本质上就是一场“猜噪声”的游戏。 为了得到高质量的结果,我们设置 epochs = 5000。在 Apple M1/M2 或 GPU 上,这大约需要 5-10 分钟;在 CPU 上可能需要更久。
# 初始化
dataset <- make_r_logo(10000)$to(device = device)
model <- NoisePredictor()$to(device = device)
batch_size <- 2048
lr <- 1e-3
epochs <- 5000 # 演示用,可根据需要调整
optimizer <- optim_adamw(model$parameters, lr = lr)
# OneCycle 调度器有助于快速收敛
scheduler <- lr_one_cycle(
optimizer,
max_lr = lr,
epochs = epochs,
steps_per_epoch = 1,
pct_start = 0.2
)
# 训练过程
for (epoch in 1:epochs) {
model$train()
optimizer$zero_grad()
# 1. 采样 Batch
idx <- sample(1:nrow(dataset), batch_size)
x0 <- dataset[idx, ]
# 2. 随机采样时间步 t
t <- torch_randint(
low = 1,
high = n_steps + 1,
size = c(batch_size),
dtype = torch_long(),
device = device
)
# 3. 前向过程 (核心函数调用)
forward_out <- q_sample(x0, t)
xt <- forward_out$xt
real_noise <- forward_out$noise
# 4. 预测与 Loss
pred_noise <- model(xt, t)
loss <- nnf_mse_loss(pred_noise, real_noise)
# 5. 反向传播
loss$backward()
nn_utils_clip_grad_norm_(model$parameters, max_norm = 1.0)
optimizer$step()
scheduler$step()
if (epoch %% 500 == 0 || epoch == 1) {
cat(sprintf("Epoch %4d | Loss: %.5f\n", epoch, loss$item()))
}
}13.3.4 逆向采样
训练完成后,我们进行逆向采样。 这里我们定义 p_sample 函数,它对应着去噪公式。
# 这一步用于推理:给定 xt 和 t,算出 x_{t-1}
p_sample <- function(model, xt, t_idx) {
# t_idx 是一个整数 (例如 300)
# 1. 构造时间张量
batch_size <- xt$size(1)
t_tensor <- torch_full(c(batch_size), t_idx, dtype = torch_float(), device = xt$device)
# 2. 预测噪声 (Model Prediction)
with_no_grad({
pred_noise <- model(xt, t_tensor)
})
# 3. 获取系数
beta_t <- betas[t_idx]
alpha_t <- alphas[t_idx]
alpha_hat_t <- alphas_bar[t_idx]
# 4. 计算均值 (Mean) - DDPM 核心公式
# mean = 1/sqrt(alpha) * (xt - beta / sqrt(1-alpha_bar) * noise)
coef <- beta_t / torch_sqrt(1 - alpha_hat_t)
mean <- (1 / torch_sqrt(alpha_t)) * (xt - coef * pred_noise)
# 5. 加回方差 (Variance)
if (t_idx > 1) {
z <- torch_randn_like(xt)
sigma <- torch_sqrt(beta_t)
x_prev <- mean + sigma * z
} else {
x_prev <- mean # 最后一步不加噪声
}
x_prev
}为了展示扩散模型的神奇之处,我们使用非线性1 采样策略来截取中间步骤——重点捕捉最后阶段图像从模糊变清晰的瞬间。
cat("开始生成...\n")
model$eval()
# 策略:非线性采样,捕捉后期的细节变化
steps_to_capture <- seq(sqrt(n_steps), sqrt(1), length.out = 9)^2 %>%
round() %>% unique()
# 从纯噪声开始
current_x <- torch_randn(2000, 2, device = device)
history <- list()
# 倒计时循环 (t: n_steps -> 1)
pb <- txtProgressBar(min = 0, max = n_steps, style = 3)
for (t in seq(n_steps, 1)) {
# 核心函数调用:一步步去噪
current_x <- p_sample(model, current_x, t)
if (t %in% steps_to_capture) {
df <- as.data.frame(as.matrix(current_x$cpu()))
df$step <- sprintf("Step: %03d", t)
history[[length(history) + 1]] <- df
}
setTxtProgressBar(pb, n_steps - t + 1)
}
close(pb)扩散过程如下图所示:
13.4 U-Net 图像生成
在上一节中,我们成功训练了一个 MLP 让点云排成了 R Logo 的形状。但如果我们想生成 MNIST 手写数字,甚至人脸照片,MLP 就力不从心了。因为图像具有局部相关性(Spatial Locality),单纯的全连接层会破坏像素间的空间关系,且参数量会随着图像分辨率爆炸。
我们需要复用第 7 章学过的卷积神经网络(CNN)。但普通的 CNN(如 ResNet)通常用于分类,把一张大图压缩成一个标签。而扩散模型的任务是输入一张噪点图,输出一张同样大小的噪声预测图。即:
- 输入:一张带噪点的图 + 一个第多少步的数字。
- U-Net 开始观察这张图,利用它对数字结构的理解,指出“哪些像素点是噪点”。
- 输出:一张单纯的“噪点图”。
13.4.1 什么是 U-Net
U-Net 最初是为医学图像分割(Segmentation)设计的,它的结构非常独特,呈现一个“U”字形:
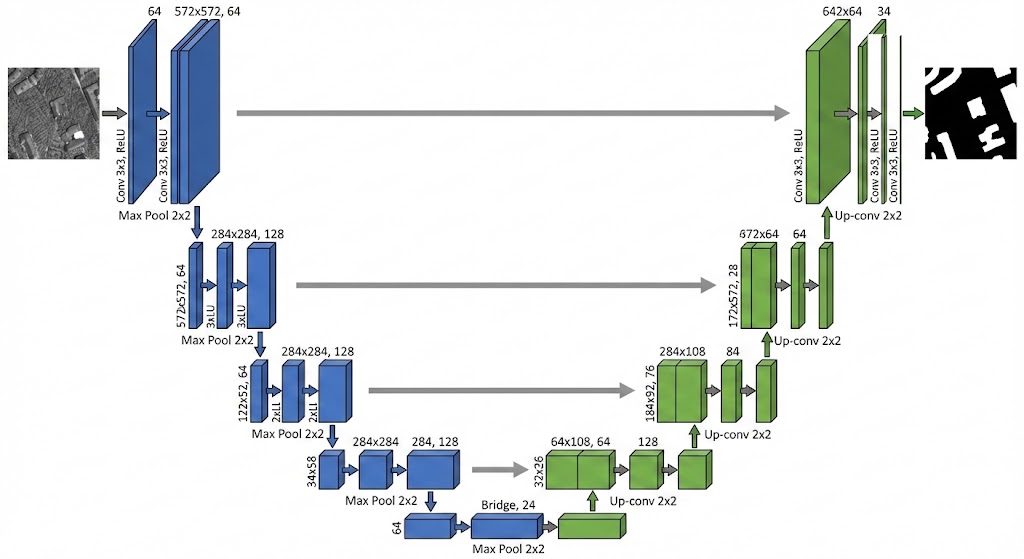
左半边 (Encoder / 下采样):
- 像传统的 CNN 一样,通过卷积和池化逐步压缩图片。结果是图片越来越小,通道(特征)越来越多。
- 这个过程丢弃了细节(比如笔画边缘的锯齿),但提取抽象概念(比如“这是个圈”、“这是个竖条”)。
- 代码对应:Down Stages (\(28 \to 14 \to 7\))。
底部 (Bottleneck / 瓶颈层):
- 在最小分辨率下处理信息。
- 用于理解全局结构。这是网络最“聪明”的地方,它理解了整张图的内容。
- 出于效果和效率的考量,在这里还可以加入了 Attention2。
- 代码对应:Mid Stage (\(7 \times 7\))。
右半边 (Decoder / 上采样):
- 图片越来越大,通道越来越少。
- 用于“还原”图像。把抽象概念变回具体的像素点,恢复分辨率。
- 代码对应:Up Stages (\(7 \to 14 \to 28\))。
中间的横线 (Skip Connections / 跳跃连接):
- 把左边对应层的特征,直接拼(Concat)到右边。
- 效果是可以找回丢失的细节。左边压缩时丢失了位置信息,通过“直连”直接传给右边,帮助右边画出清晰的边缘。
13.4.2 基础块和时间注入
构造一个时间感知残差块 (Time-Aware ResBlock),这是构建 U-Net 的最小单元。它比普通的卷积块多了一个步骤:注入时间信息。
结构:Conv -> GroupNorm -> SiLU + Time_Emb
Block <- nn_module(
"Block",
initialize = function(dim, time_emb_dim) {
self$proj <- nn_conv2d(dim, dim, 3, padding = 1)
self$norm <- nn_group_norm(32, dim)
self$act <- nn_silu()
# 时间投影层
self$time_mlp <- nn_sequential(nn_silu(), nn_linear(time_emb_dim, dim))
},
forward = function(x, t_emb) {
h <- self$proj(x)
h <- self$norm(h)
# 注入时间:(B, dim) -> (B, dim, 1, 1) -> 加到特征图上
time_h <- self$time_mlp(t_emb)$unsqueeze(-1)$unsqueeze(-1)
h <- h + time_h
self$act(h)
}
)这是 ResNet 风格的卷积块。time_mlp 将时间向量映射并加到图像特征 h 上。我们可以把时间嵌入看作一个“全局指令”。比如 \(t=1000\) 时,指令是“现在的图全是噪点,请大胆猜测”;\(t=10\) 时,指令是“只剩一点噪点了,请小心微调”。我们需要把这个指令发送给图像的每一个像素。
13.4.3 扩散调度器
这是扩散模型数学核心的实现部分。
- Betas (\(\beta\)):控制每一步加多少噪声。这里使用线性调度 (torch_linspace) 从 0.0001 到 0.02。
- Alphas (\(\alpha\)):\(\alpha_t = 1 - \beta_t\)。
- Alphas Bar (\(\bar{\alpha}\)):torch_cumprod 计算累乘。这允许我们直接跳到第 \(t\) 步,计算出 \(x_t\)(加噪后的图像),而不需要一步步循环加噪。
里面有个关键函数 extract:
extract <- function(a, t, x_shape) {
batch_size <- t$size(1)
# 1. 确保 t 是长整型 (MPS 要求)
t_long <- t$to(dtype = torch_long())
# a 是 [1000], t 是 [B], a[t] 会直接返回 [B]
out <- a[t_long]
# 3. 调整维度为 (B, 1, 1, 1) 以便与图像广播
out$view(c(batch_size, 1, 1, 1))
}这是一个广播 (Broadcasting) 辅助函数。
- a 是一个长度为 1000 的向量,t 是一个长度为 128 (Batch Size) 的向量。a[t] 取出当前 batch 对应的系数。
- 图像形状是 (128, 1, 28, 28)。为了让系数能和图像相乘,必须把系数的形状从 (128) 变成 (128, 1, 1, 1)。
在前一节的 MLP 中,我们直接把时间向量 \(t\) 和坐标 \((x,y)\) 拼在一起输入。但在 CNN 中,图像数据是 4 维张量 (Batch, Channel, Height, Width),而时间嵌入是 2 维向量 (Batch, Time_Dim)。维度不同,怎么融合?业界通用的做法是“广播与相加”(Broadcast & Add)。
13.4.4 SimpleUNet 主体
这个 U-Net 是整个扩散模型的核心,它的任务非常明确:给它一张带噪点的图 \(x_t\) 和一个时间步 \(t\),它要吐出这张图里包含的噪声 \(\epsilon\)。为了完成这个任务,代码被设计成三个主要部分:
- 时间处理(让模型知道现在是第几步)。
- 下采样(Encoder)(压缩图像,提取特征)。
- 上采样(Decoder)(放大图像,还原细节,预测噪声)。
一、初始化部分
时间感知 (self$time_mlp):
self$time_mlp <- nn_sequential(
PositionEmbeddings(time_dim),
nn_linear(time_dim, time_dim * 4),
nn_gelu(),
nn_linear(time_dim * 4, time_dim)
)扩散模型是分步骤的(第1步和第1000步的噪声强度完全不同)。模型必须“知道”现在是第几步。把一个简单的整数 t(比如 500),通过正弦变换和全连接层,变成一个长度为 32 的向量。
下采样(Down/Encoder):
self$init_conv <- nn_conv2d(...) # 刚进门的第一刀
self$down1 <- Block(...) # 处理 28x28
self$down2 <- Block(...) # 处理 14x14
self$to_down2 <- nn_conv2d(..., stride = 2) # 负责把图变小 (28->14)
# ...- 尺寸:\(28 \times 28 \to 14 \times 14 \to 7 \times 7\)。
- 通道(厚度):\(32 \to 64 \to 128\)。
- 牺牲分辨率,换取高层语义。虽然图变模糊了,但模型搞清楚了“这里大致有个圈”,“那里是个竖条”。
瓶颈层(Mid / Bottleneck):
self$mid1 <- Block(base_dim * 4, time_dim)
self$mid2 <- Block(base_dim * 4, time_dim)在 \(7 \times 7\) 这么小的尺寸上进行深度思考。此时不再改变图片大小。
上采样 (Up / Decoder):
self$up1 <- nn_conv_transpose2d(...) # 负责把图放大 (7->14)
self$up_block1 <- Block(...) # 负责融合特征
# ...一层层把图放大回去。nn_conv_transpose2d 是“反卷积”(转置卷积),它能把 \(7 \times 7\) 的像素插值、填充,变回 \(14 \times 14\)。
二、前向传播部分 (forward)
这部分顺次执行了:
- 处理时间
- 初始卷积和下采样
- 瓶颈层思考
- 上采样
- 还有一个关键操作:Skip Connections
- 输出
关于 Skip Connections 的拼接要解释一下:
# --- Up 1 (7 -> 14) ---
h_up1 <- self$up1(h_mid) # 把 7x7 放大回 14x14
# 【核心操作:拼接】
# h_up1 是刚才放大的,比较模糊。
# h2 是刚才下采样时存下的,非常清晰。
# 把它们在通道维度拼起来 (dim=2)。
h_cat1 <- torch_cat(list(h_up1, h2), dim = 2)
h_res1 <- self$up_block1(h_cat1, t_emb) # 融合这两种信息- h_up1(刚放大的)包含了“宏观结构”(比如:这里应该是个8的下半部分)。
- h2(之前的)包含了“微观细节”(比如:这个笔画边缘的具体位置)。
- 拼接让模型既知道画什么(结构),又知道画在哪(位置)。
整个网络的结构如下:形状格式为:(Batch, Channel, H, W)
| 阶段 | 变量名 | 形状 | 备注 |
|---|---|---|---|
| 输入 | x | (128, 1, 28, 28) | 原始噪点图 |
| 初始 | x1 | (128, 32, 28, 28) | 变厚了 |
| 下采样1 | h1 | (128, 32, 28, 28) | 存入记忆 |
| 下采样2 | h2 | (128, 64, 14, 14) | 变小,变厚,存入记忆 |
| 下采样3 | h3 | (128, 128, 7, 7) | 最小,最厚 |
| 中间层 | h_mid | (128, 128, 7, 7) | 形状不变 |
| 上采样1 | h_up1 | (128, 64, 14, 14) | 放大 |
| 拼接1 | h_cat1 | (128, 64+64, 14, 14) | 64来自上采样,64来自h2 |
| 融合1 | h_res1 | (128, 64, 14, 14) | 消化掉拼接的信息 |
| 上采样2 | h_up2 | (128, 32, 28, 28) | 放大 |
| 拼接2 | h_cat2 | (128, 32+32, 28, 28) | 32来自上采样,32来自h1 |
| 融合2 | h_res2 | (128, 32, 28, 28) | 消化 |
| 输出 | out | (128, 1, 28, 28) | 变回单通道噪声 |
13.4.5 训练过程和逆采样
这是 DDPM 的核心训练算法:
- 取图:拿一批干净的图 \(x_0\)。
- 随机时间:为每一张图随机选一个时间步 \(t\) (1 到 1000)。
- 造噪:生成随机高斯噪声 noise (\(\epsilon\))。
- 前向加噪:利用公式直接生成第 \(t\) 步的图 \(x_t\):
\[ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \]
代码中对应:xt <- sqrt_ab * x0 + sqrt_om_ab * noise。
- 预测:模型根据 \(x_t\) 和 \(t\) 预测刚才加进去的噪声 \(\epsilon\)。pred_noise <- model(xt, t)
- Loss:计算真噪声和预测噪声的 MSE(均方误差)。
训练完成后,使用上一节的 p_sample 采样函数(同样无需修改),给它一个纯随机噪声 img <- torch_randn(...),从 t=1000 倒数到 t=1,你会看到它慢慢变成一个手写的数字。

至此,我们已经复现了 DDPM 的核心逻辑。但你可能会发现生成速度很慢(需要几百步),且无法控制生成哪种数字。下一节,我们将讨论如何加速采样,以及如何让模型听懂指挥(条件生成)。
13.5 采样与条件控制
我们在代码里写的 p_sample 就是标准的 Ancestral Sampling (祖先采样)。
想象你在大雾弥漫的山顶(纯噪声),要下山回到山谷(清晰图像)。
- 训练时:我们直接把一个人从山谷扔到半山腰(一步加噪),这很容易计算。
- 推理时:由于你是从随机的“雾”开始的,你不知道路在哪。你必须每一小步都问路(模型预测噪声),然后小心翼翼地走一步。
如果你直接从第 1000 步跳到第 0 步,这样大的落差,图像大概率会崩坏。因为数学假设是:只有步长足够小,逆向过程才近似于高斯分布。
后来出现的 DDIM 和 DPM-Solver 等算法可以通过更高级的数学技巧“跳步”,把 1000 步压缩到 20-50 步,但这超出了本节基础范围,不做展开。
13.5.1 条件生成原理
在扩散模型中,我们不仅希望生成逼真的图像,更希望控制生成的内容(例如指定生成数字 “7”)。实现这一目标的主流方案是 Classifier-Free Guidance (CFG)。目前最主流的是控制生成方法(Stable Diffusion 也是用这个)。它的原理非常优雅,被称为 “双重人格” 策略。
Label 的 Embedding 叠加
在 U-Net 架构中,条件控制的核心在于如何将离散的类别标签(Label)转化为网络可理解的连续信号,并与时间步(Time Step)信号融合。
我们定义:
- \(t\) 为当前扩散时间步。
- \(y\) 为目标类别标签(例如数字 0-9)。
- \(\mathbf{v}_t \in \mathbb{R}^d\) 为时间 \(t\) 的 Embedding 向量(由 Sinusoidal Positional Embedding 生成)。
- \(\mathbf{v}_y \in \mathbb{R}^d\) 为类别 \(y\) 的 Embedding 向量(由可学习的 nn_embedding 层映射得到)。
从线性代数的角度来看,这是在特征空间中的线性叠加。由于神经网络(特别是随后的 MLP 层)本质上是非线性函数逼近器,它能够通过训练学习到如何将叠加后的向量 \(\mathbf{v}_{ctx}\) 解耦,提取出其中的时间信息(用于确定去噪强度)和类别信息(用于确定图像特征的结构倾向)。
这一混合向量 \(\mathbf{v}_{ctx}\) 随后被送入 U-Net 的各个残差块(ResBlock)中,通常作为 Scale(缩放)和 Shift(平移)参数作用于特征图,从而在不同分辨率层级上引导去噪方向。
损失函数
在引入条件 \(y\) 后,训练阶段的损失函数(Loss Function)形式保持不变,依然是预测噪声与真实噪声之间的均方误差(MSE)。
设真实噪声为 \(\epsilon \sim \mathcal{N}(0, \mathbf{I})\),噪声图为 \(x_t\),模型预测网络为 \(\epsilon_\theta\)。条件扩散模型的优化目标为:
\[ L = \mathbb{E}_{x_0, y, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, y) \|^2 \right] \]
虽然公式形式未变(代码一行不用改),但计算图(Computation Graph)发生了本质变化:
- 前向传播过程中,网络 \(\epsilon_\theta\) 接收 \(y\) 的 Embedding \(\mathbf{v}_y\) 作为输入的一部分。模型的输出 \(\epsilon_\theta(x_t, t, y)\) 显式地依赖于 \(y\)。
- 反向传播过程中,当计算梯度 \(\nabla L\) 时,误差不仅会更新 U-Net 的卷积层权重,还会沿着加法操作回传至 nn_embedding 层。
- 这意味着 Embedding 矩阵中的向量 \(\mathbf{v}_y\) 会被不断调整,以使得在这个向量的指引下,网络预测出的噪声能更准确地还原出属于类别 \(y\) 的图像。
也就是说,Loss 不需要显式包含 \(y\),因为 \(y\) 已经作为参数参与了预测过程,梯度下降会自动惩罚那些“无视条件”或“错误利用条件”的预测行为。
训练策略:Label Dropout
为了实现 Classifier-Free Guidance,模型必须具备两种能力:
- 条件生成能力:\(p(x|y)\),即给定标签生成特定图像。
- 无条件生成能力:\(p(x)\),即不给定标签生成任意图像。
我们通过 Label Dropout 策略在同一个模型中联合训练这两种能力。
采样策略:Classifier-Free Guidance (CFG) 原理
CFG 的核心思想是在推理(Sampling)阶段,利用向量运算增强条件信号的影响力。
对于给定的噪声图 \(x_t\) 和时间步 \(t\),我们进行两次前向预测:
- 无条件预测:\(\epsilon_{uncond} = \epsilon_\theta(x_t, t, y_\emptyset)\)。这代表了模型在没有任何约束下认为的噪声方向。
- 有条件预测:\(\epsilon_{cond} = \epsilon_\theta(x_t, t, y)\)。这代表了模型在已知目标是 \(y\) 时认为的噪声方向。
这两者的差值向量 \(\Delta = \epsilon_{cond} - \epsilon_{uncond}\) 具有明确的物理意义:它代表了“类别 \(y\) 独有的特征方向”,即去除了通用图像特征后,仅由类别 \(y\) 带来的梯度分量。
最终的预测噪声 \(\hat{\epsilon}\) 定义为: \[ \hat{\epsilon} = \epsilon_{uncond} + w \cdot (\epsilon_{cond} - \epsilon_{uncond}) \]
其中 \(w\) 是引导尺度(Guidance Scale)。
- 当 \(w=1\) 时,\(\hat{\epsilon} = \epsilon_{cond}\),即标准的条件生成。
- 当 \(w>1\) 时,我们显式地放大了差值向量 \(\Delta\)。这意味着我们在特征空间中,强行将去噪方向推向类别 \(y\) 的极值点,从而降低生成结果的多样性,但显著提升与条件 \(y\) 的一致性(Fidelity)。
这一公式实质上是用隐式的梯度引导代替了外挂分类器的显式梯度,避免了训练额外分类器的成本,且在工程实现上更为优雅和稳定。
13.5.2 实现逻辑
理论已经完备,现在我们将这些数学原理转化为具体的 R 代码逻辑。我们在 SimpleUNet 的基础上构建 ContextUnet,核心变动体现在以下三个环节:
1. 注入双重信号
如前所述,我们需要在模型初始化时增加 label_emb,并在前向传播(Forward)时将其与时间嵌入相加。
\[ \mathbf{v}_{ctx} = \mathbf{v}_t + \mathbf{v}_y \]
即,在代码中初始化部分增加了
self$label_emb <- nn_embedding(num_classes + 1, time_dim)在 forword 中将时间的向量同 y_label 的向量简单加在了一起。
t_emb <- self$time_mlp(t)
y_emb <- self$label_emb(y)
ctx_emb <- t_emb + y_emb这个例子源代码我增加了 Attention 机制,但考虑到 MNIST 这个数据集太简单了,并且出于执行效率考虑,Attention 模块注释掉了。如果你处理的复杂图像,人脸图片,高分辨率图片,请增加 Attention 机制。
2. 训练循环
为了让模型同时学会“有条件生成”和“无条件生成”,我们在训练循环中引入 Label Dropout。具体做法是生成一个随机掩码(Mask),以一定概率(如 10%)将真实标签替换为特殊的“空标签”(通常设为 \(N+1\))。
# 10% 的概率将标签设为 11 (空标签)
mask <- torch_rand(batch_n, device = device) < 0.1
labels[mask] <- 11这一步至关重要,它强迫模型在没有明确指令时,也能依靠对数据集的整体认知来还原图像。
3. 执行 CFG 策略
在推理阶段,我们不再直接预测噪声,而是通过公式组合两个预测结果。
# 1. 无条件预测 (你是谁?)
noise_uncond <- model(img, t, y_uncond)
# 2. 有条件预测 (由指令控制的你是谁?)
noise_cond <- model(img, t, y_cond)
# 3. 放大差异 (我要那个被指令强化过的你)
pred_noise <- noise_uncond + w * (noise_cond - noise_uncond)当我们把 target_digit 设为 7 并设置引导尺度 \(w=2.0\) 时,模型生成的图像如下所示:

可以看到,生成的数字不仅清晰,而且严格遵循了我们的控制条件。
13.5.3 从 Class 到 Text
理解了 Label Embedding,你就掌握了通向现代 AI 绘画(如 Stable Diffusion)的钥匙。
如果你将输入的 \(y\) 从一个简单的“数字索引”换成一段“文本描述”,将简单的查表层 nn_embedding 换成一个强大的文本编码器(如 CLIP 或 BERT),那么:
- \(\mathbf{v}_y\) 就变成了这就代表了“一只在太空骑马的宇航员”的语义向量。
- 扩散模型去噪的过程,就会受到这段文本语义的强力引导。
虽然工程实现的复杂度(如 Cross-Attention 机制)会显著增加,但其底层的 “条件引导去噪” 原理,与你刚刚完成的 MNIST 数字生成是完全一致的。