11 变分自编码器
“我们要创造一个梦境。”
—— 《盗梦空间》 (2010)
柯布是顶级的造梦师,他知道梦境并非凭空而来,而是潜意识的投影。他随身带着一个陀螺(图腾),用来验证自己是在现实还是在梦境的边缘。
11.1 从压缩到生成
VAE 就是算法界的“造梦师”。 编码器将复杂的现实压缩成一个低维的潜在空间(Latent Space)——这就像是梦的种子(均值与方差)。解码器则根据这个种子,重构出丰富多彩的“梦境”(图像)。我们在这个空间里游走,就是在探索数据灵魂的形状。
在前面的章节中,我们要么是在做回归(预测股价),要么是在做分类(识别图像)。这些任务统称为判别式模型 (Discriminative Models),本质上是学习一个决策边界。
从本章开始,我们将进入生成式模型 (Generative Models) 的世界。我们的目标不再是区分“这是什么”,而是要让机器学会“创造”——不仅仅是记住训练集里的图片,而是理解图片背后的生成逻辑,从而创造出从未见过的新样本。我们将从最经典的变分自编码器 (Variational Auto Encoder, VAE) 开始这段旅程。
11.1.1 AE 的局限
在介绍 VAE 之前,我们需要先回顾一下它的前身——自编码器 (Auto Encoder,AE)。自编码器的结构非常简单,由两部分组成:
- 编码器 (Encoder):将高维输入数据 \(x\)(比如一张图片)压缩成一个低维向量 \(z\)。这个 \(z\) 被称为潜在向量 (Latent Vector)。
- 解码器 (Decoder):将 \(z\) 还原回 \(x'\),尽可能让 \(x' \approx x\)。
如果把训练过程比作“压缩文件”,AE 确实做得不错。它能学到数据的主要特征。但是,如果我们想用标准 AE 来生成新数据,就会遇到大问题。
问题在于潜在空间 (Latent Space) 的不连续性。
假设我们训练了一个手写数字 AE,它把数字“1”编码为点 \(A\),把数字“7”编码为点 \(B\)。在几何空间中,点 \(A\) 和点 \(B\) 之间是什么?在标准 AE 中,那里可能是一片荒芜的“死区”,解码器从未见过那里的数据。如果你在 \(A\) 和 \(B\) 之间随机取一个点输入解码器,输出的往往是一张毫无意义的噪点图,而不是一个介于“1”和“7”之间的数字。
结论:标准 AE 学会了复现,但没有学会生成。它的潜在空间是离散的、毫无规律的。
11.1.2 从点到分布
VAE 的核心创新在于:它不再将输入映射为潜在空间中的一个固定的“点”,而是映射为一个概率“分布”。
在 VAE 中,编码器不再直接输出隐向量 \(z\),而是输出两个统计量:
- 均值 (Mean, \(\mu\)):代表分布的中心。
- 对数方差 (Log-Variance, \(\log\sigma^2\)):代表分布的范围(不确定性)。
直观理解:
- AE 说:“这张图片就是空间坐标 \((3.5, 4.2)\)。”
- VAE 说:“这张图片大概在坐标 \((3.5, 4.2)\) 附近,可能有一点偏差,在这个圆圈范围内取样,应该都像这张图。”
当我们想要生成一个潜变量 \(z\) 时,我们就从这个正态分布 \(N(\mu, \sigma^2)\) 中随机采样一个点。
这样做的好处是平滑了潜在空间。因为我们是对分布采样,训练过程中解码器会被迫适应以 \(\mu\) 为中心的小范围内的所有点。这意味着,如果你在数字“1”和数字“7”的分布之间移动,解码器生成的图像会从“1”平滑地渐变为“7”,而不会出现噪点。
11.1.3 损失函数
重建误差与 KL 散度:VAE 的训练目标由两部分组成,这两部分通过损失函数进行博弈。
\[ Loss = L_{reconstruction} + \beta \cdot L_{KL} \]
重建损失 (Reconstruction Loss)
这部分和标准 AE 一样,衡量生成出的图片和原图像不像。
- 如果是连续数据(如像素值),通常使用均方误差 (MSE)。
- 如果是二值化数据(黑白点),可以使用二元交叉熵 (BCE)。
KL 散度 (Kullback-Leibler Divergence)
如果我们只看重建损失,模型会作弊:它会把方差 \(\sigma^2\) 缩得无限小,让分布退化成一个点,这样 VAE 就退化回了标准 AE,失去了生成能力。
为了防止这种情况,我们需要加一个约束(正则化项):强迫编码器输出的分布 \(N(\mu, \sigma^2)\) 尽可能接近标准正态分布 \(N(0, 1)\)。衡量两个概率分布差异的指标就是 KL 散度。对于两个高斯分布,KL 散度有明确的解析解公式。假设我们希望编码器产生的分布接近 \(N(0, I)\),推导后的公式非常适合编程实现:
\[ D_{KL} = -0.5 \sum_{i=1}^{J} (1 + \log(\sigma_i^2) - \mu_i^2 - \sigma_i^2) \]
- \(\mu_i^2\) 项:惩罚均值偏离 0。
- \(\sigma_i^2 - \log(\sigma_i^2)\) 项:惩罚方差偏离 1(过大或过小都会导致惩罚)。
重建损失希望分布尽可能窄(专注于复现原图)。KL 散度希望分布尽可能宽且靠近中心(保证空间的连续性和完备性)。VAE 就这个博弈过程中,找到了一个既能生成清晰图像,又具备良好潜在空间结构的平衡点。
重参数化技巧 (Reparameterization Trick)
原理讲通了,但在写代码时会遇到一个致命的工程问题:反向传播无法穿过“随机采样”层。在神经网络中,梯度下降依赖于链式法则。如果在网络中间有一个节点是 z = sample_from_normal(mu, sigma),这是一个随机过程。你无法对这个动作求导,因为它是不可微的。这意味着梯度断掉了,编码器无法更新参数。
为了解决这个问题,VAE 引入了重参数化技巧。我们将随机性“剥离”出来。我们不再直接从 \(N(\mu, \sigma^2)\) 采样,而是将其分解为:
\[ z = \mu + \sigma \odot \epsilon \]
其中:
- \(\mu\) 和 \(\sigma\) 是编码器计算出来的(确定性的,可导)。
- \(\epsilon\) 是从标准正态分布 \(N(0, 1)\) 中采样的噪声(随机的,不需要求导)。
- \(\odot\) 代表逐元素相乘。
这使得 VAE 的训练过程变得非常高效。通过这个技巧,看似复杂的变分推断问题,被转化为了一个简单的神经网络前向计算问题。在 torch 中,这只需要一行代码即可实现。
11.2 构建 VAE 模型
我们将把上一节那张抽象的流程图,翻译成具体的 R 代码。你会发现,R 的 torch 语法在构建自定义网络时显得非常优雅和结构化。
在开始写代码之前,我们需要确定一下网络架构。我们以 章节 7 的 MNIST 数据集为例,输入是一张 \(28 \times 28\) 的灰度图片。
首先先定义一个 dataset 函数,用于加载 MNIST 数据集。VAE 不需要 label,它的目标是重建输入,所以 Target 和 Input 一样。
vae_dataset <- dataset(
name = "mnist_vae_dataset",
initialize = function(images) {
self$data <- images
},
.getitem = function(i) {
# 返回 list(input, target)
list(x = self$data[i,..], y = self$data[i,..])
},
.length = function() {
self$data$size(1)
}
)
# 实例化 Dataset
train_ds <- vae_dataset(train_data$images)
test_ds <- vae_dataset(test_data$images)
# 实例化 Dataloader
train_dl <- dataloader(train_ds, batch_size = 128, shuffle = TRUE)
test_dl <- dataloader(test_ds, batch_size = 128, shuffle = FALSE)加载数据等环节同 章节 7 中的代码。
11.2.1 VAE 框架
实际上 VAE 框架非常简单,我们只需要定义编码器和解码器,然后在训练时计算损失函数即可。首先看下初始化部分:
initialize = function(
input_dim = 784, hidden_dim = 400, latent_dim = 20) {
# --- Encoder (编码器) ---
self$fc1 <- nn_linear(input_dim, hidden_dim)
# 瓶颈层分裂
self$fc2_mu <- nn_linear(hidden_dim, latent_dim) # “均值”
self$fc2_logvar <- nn_linear(hidden_dim, latent_dim) # “方差”
# --- Decoder (解码器) ---
self$fc3 <- nn_linear(latent_dim, hidden_dim)
self$fc4 <- nn_linear(hidden_dim, input_dim)
},根据前文讨论,VAE 认为潜在空间是一个高斯分布。要描述一个高斯分布,必须知道两个参数:均值 \(\mu\)方差 \(\sigma^2\)。所以,我们在瓶颈处把网络一分为二:fc2_mu 负责猜均值,fc2_logvar 负责猜方差。
接下来是关键的 reparameterize 函数,用于从编码器的输出中采样潜在变量 \(z\)。上一节我们推导公式 \(z = \mu + \sigma \odot \epsilon\),代码中实现的逻辑如下:
# mu/logvar: 编码器输出的均值/对数方差
reparameterize = function(mu, logvar) {
# 计算标准差 sigma
std <- torch_exp(0.5 * logvar)
# 从标准正态分布 N(0, 1) 中采样噪声 epsilon
# 生成一个和 std 形状一样的张量,填满标准正态随机数
eps <- torch_randn_like(std)
z <- mu + eps * std
return(z)
}为什么要网络输出 logvar 而不是直接输出方差?因为方差 \(\sigma^2\) 必须是正数。如果让神经网络直接预测方差,你需要加激活函数(如 ReLU)保证它是正的,但这容易导致梯度问题。预测 \(\log\sigma^2\) 就没限制了,它可以是负无穷到正无穷的任何实数,取个指数 (exp) 自然就变回正数了,数值上更稳定。在代码中,变量 logvar 代表:
\[ \text{logvar} = \ln(\sigma^2) \]
所以
\[ \sigma^2 = e^{\text{logvar}} \]
所以
\[ \sigma = \sqrt{e^{\text{logvar}}} = e^{0.5 \text{logvar}} \]
eps <- torch_randn_like(std) 这一步非常巧妙。随机生成一个和 std 形状一样的张量,里面填满了服从 \(N(0, 1)\) 的随机噪声。
z <- mu + eps * std 我们在确定的均值上,加上了一点方差为 std 的随机扰动。这使得 \(z\) 变成了一个从分布中采样出来的点,同时又保留了 \(\mu\) 和 \(\sigma\) 的梯度信息(反向传播可以穿过加法和乘法,但不能穿过“采样”动作,所以我们把采样动作隔离到了 eps 身上。
接下来看 forward 函数:
forward = function(x) {
x_flat <- x$view(c(-1, 784)) # 展平输入
h <- x_flat %>% self$fc1() %>% torch_relu() # encoder
mu <- self$fc2_mu(h)
logvar <- self$fc2_logvar(h)
# 采样 (训练时采样,预测时为了稳定通常也采样,或者直接用 mu)
z <- self$reparameterize(mu, logvar)
# 解码
recon <- z %>% self$fc3() %>% torch_relu() %>%
self$fc4() %>% torch_sigmoid()
list(recon, mu, logvar)
}形状变化如下:
- 输入:展平后的向量,长度 \(784\),从
[Batch, 1, 28, 28]到[Batch, 784]。 - 编码器:从 784 压缩到 400,再压缩到潜在空间 (Latent Space)。
- 潜在空间:维度设为 \(20\)。需要输出两个向量:均值 \(\mu\) 和对数方差 \(\log\sigma^2\)。
- 解码器:从 20 还原回 400,再还原回 784(输出图片)。
最后返回了个 list [recon, mu, logvar],
recon,用于计算重建图像像不像原图的 loss。mu和logvar用与计算 KL 散度,用于衡量潜在空间分布是否标准。
11.2.2 训练模型
luz 的损失函数接收 predictions (模型的输出) 和 targets (真实标签)。
vae_loss <- function(predictions, targets) {
recon_x <- predictions[[1]]
mu <- predictions[[2]]
logvar <- predictions[[3]]
# 展平
targets_flat <- targets$view(c(-1, 784))
# 使用二元交叉熵 (BCE)
BCE <- nnf_binary_cross_entropy(recon_x, targets_flat, reduction = 'sum')
# KL 散度 (Kullback-Leibler Divergence)
KLD <- -0.5 * torch_sum(1 + logvar - mu$pow(2) - logvar$exp())
# 返回总损失
BCE + KLD
}训练过程就和之前的一样,只是损失函数换成了 vae_loss。
fitted <- vae_module %>%
setup(
loss = vae_loss,
optimizer = optim_adam
) %>%
set_hparams(input_dim = 784, hidden_dim = 400, latent_dim = 20) %>%
fit(
train_dl,
epochs = 20,
valid_data = test_dl,
verbose = TRUE
)关于 loss 的估算。VAE 的 Loss 由两部分组成:重建误差 (BCE) + KL 散度。我们以单张图片举例说明。假如模型瞎猜,每个像素点都预测为 0.5(灰度),那么一个像素点的 BCE 损失为: \[ \text{BCE} = - \sum_{i=1}^{1} \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right] \]
其中 \(y_i\) 是真实像素值(0 或 1),\(\hat{y}_i\) 是模型预测值(0.5)。
这个 BCE 值为 0.693,一张图片有 784 个像素点,一个 batch 为 128 张图片,所以一个 batch 的 BCE 损失约为 69543。KL 散度根据公式可以计算,数值很小,可以忽略不计。
假设每个像素点误差很小,比如 0.1,那么一个 batch 的重建误差约为 10035。
以上为估计,看实际训练过程的 loss 曲线:
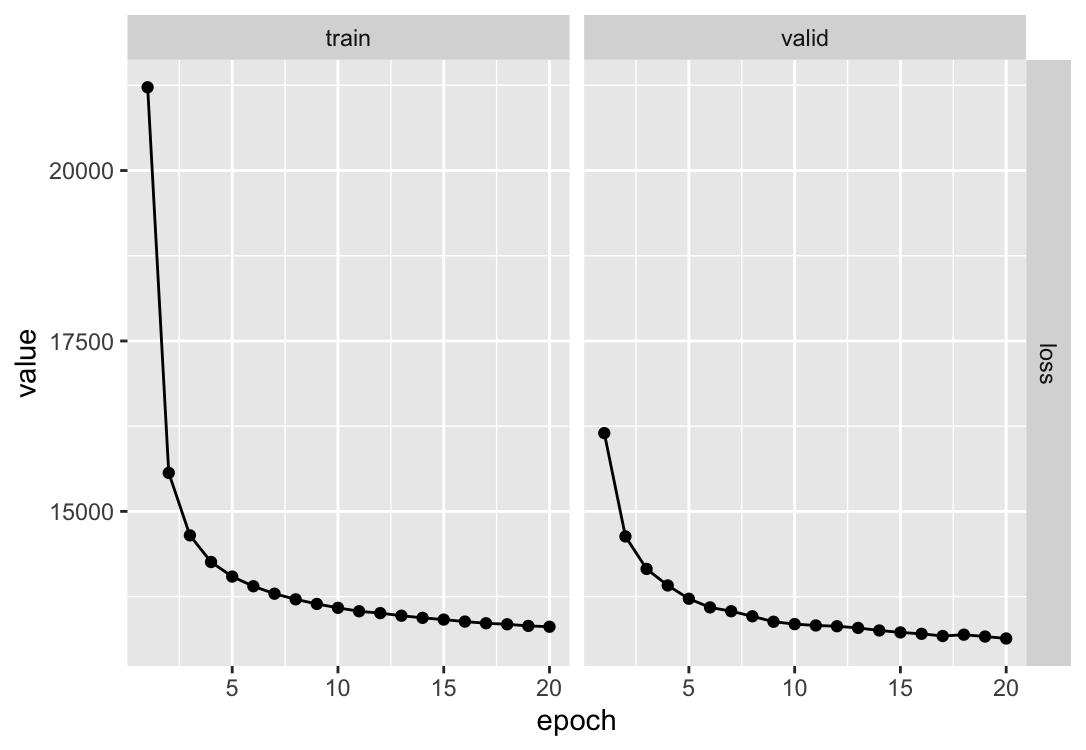
20 个 epoch 训练完成,loss 下降到 13000 左右,符合我们的预期。
11.2.3 生成新图片
训练完成后,我们可以尝试从潜在空间采样,生成一些全新的数字。
思路非常清晰:
- 从分布 \(N(0, 1)\) 中采样 \(z\),形状为
[n, 20],其中 \(n\) 是要生成的图片数量。 - 用 \(z\) 作为输入,通过解码器网络,生成对应的图片 \(\hat{x}\)。
- 可视化 \(\hat{x}\),就是我们生成的新数字。
generate_digits <- function(luz_fitted_obj, n = 16) {
raw_model <- luz_fitted_obj$model
raw_model$eval()
device <- raw_model$parameters[[1]]$device
z <- torch_randn(n, 20, device = device)
with_no_grad({
samples <- z %>%
raw_model$fc3() %>%
torch_relu() %>%
raw_model$fc4() %>%
torch_sigmoid()
})
samples_cpu <- samples$to(device = "cpu")
samples_matrix <- as_array(samples_cpu$view(c(n, 28, 28)))
plot_data <- map_dfr(1:n, function(i) {
expand.grid(row = 1:28, col = 1:28) %>%
mutate(
val = as.vector(t(samples_matrix[i,,])),
img_id = i
)
})VAE 生成的数字如下(图片上面的数字没有意义,是生成图片的序号):

11.2.4 聚类和压缩
假如我们有 2000 个样本,需要做一个聚类分析。传统统计思维下,可视化有几个可能做法:
- UMAP (Uniform Manifold Approximation and Projection)
- t-SNE (t-Distributed Stochastic Neighbor Embedding)
- PCA (Principal Component Analysis,主成分分析)
这三种方法都可以将 2000 个样本压缩到 2 维空间,可视化出来。还有一种办法,利用 标签 y 和 x 的关系,通过线性判别分析法 MASS::lda,找到二维投影方向,使得不同类别之间的差异最大。我们可以看下这四种可视化结果如何。
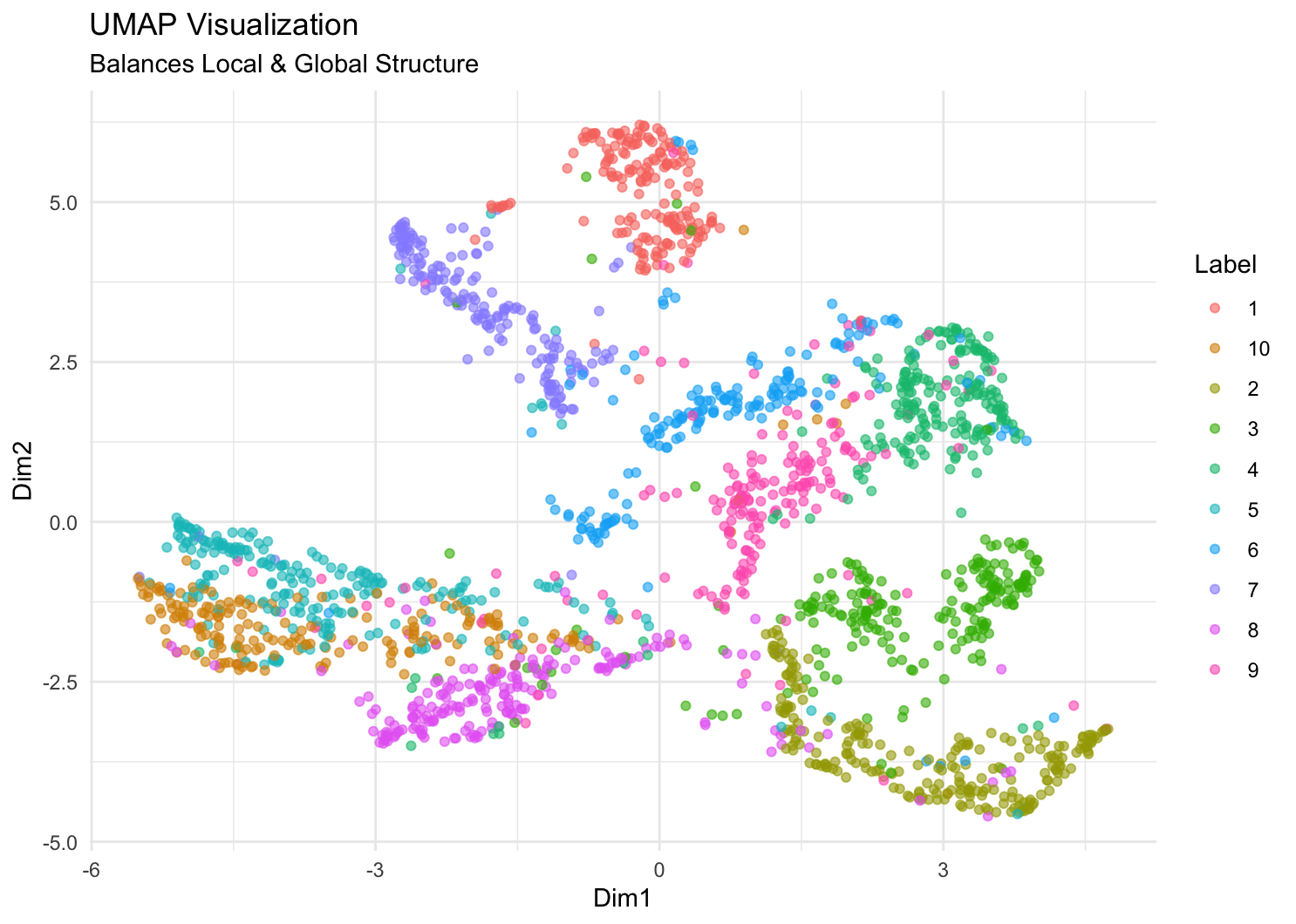
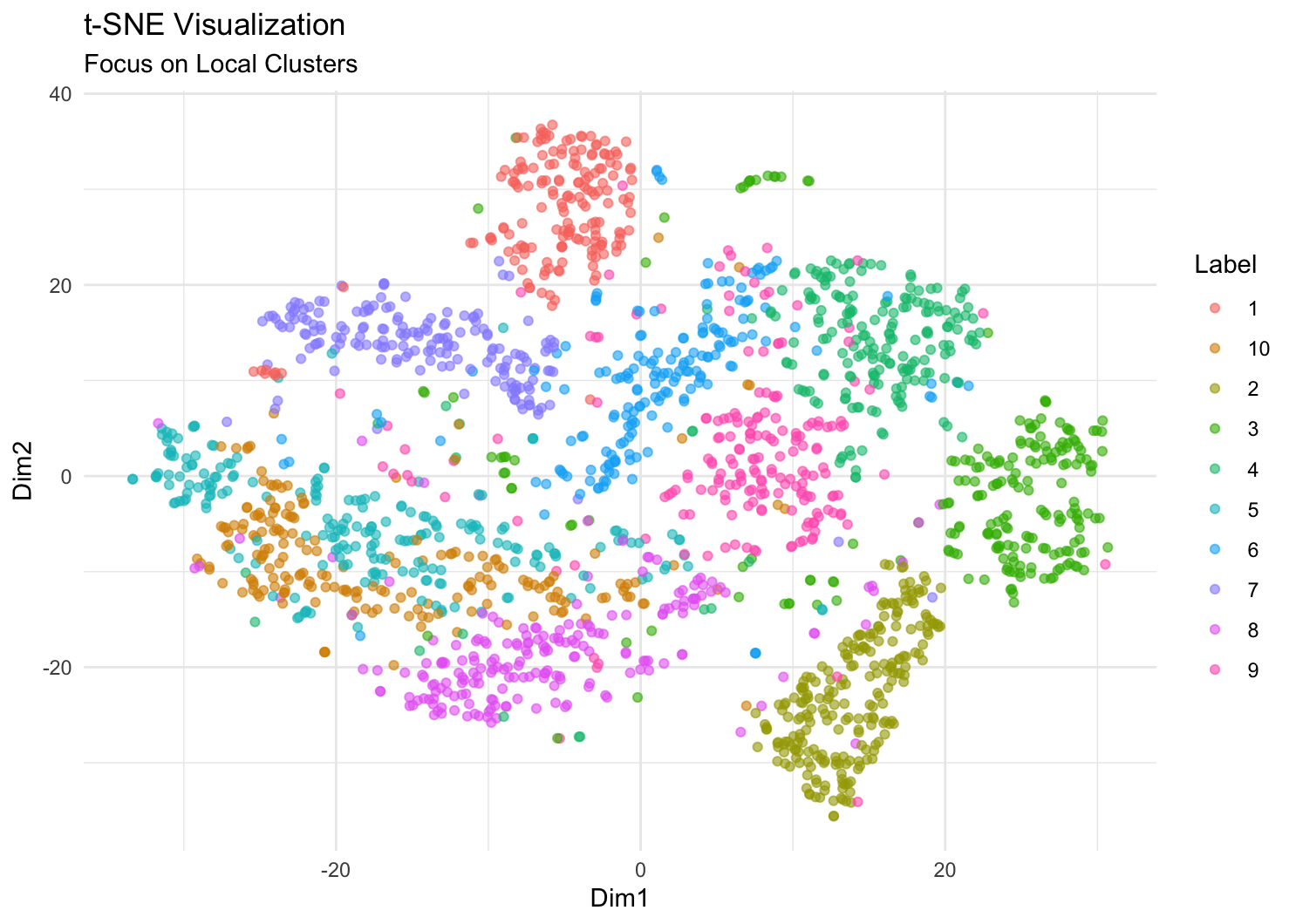
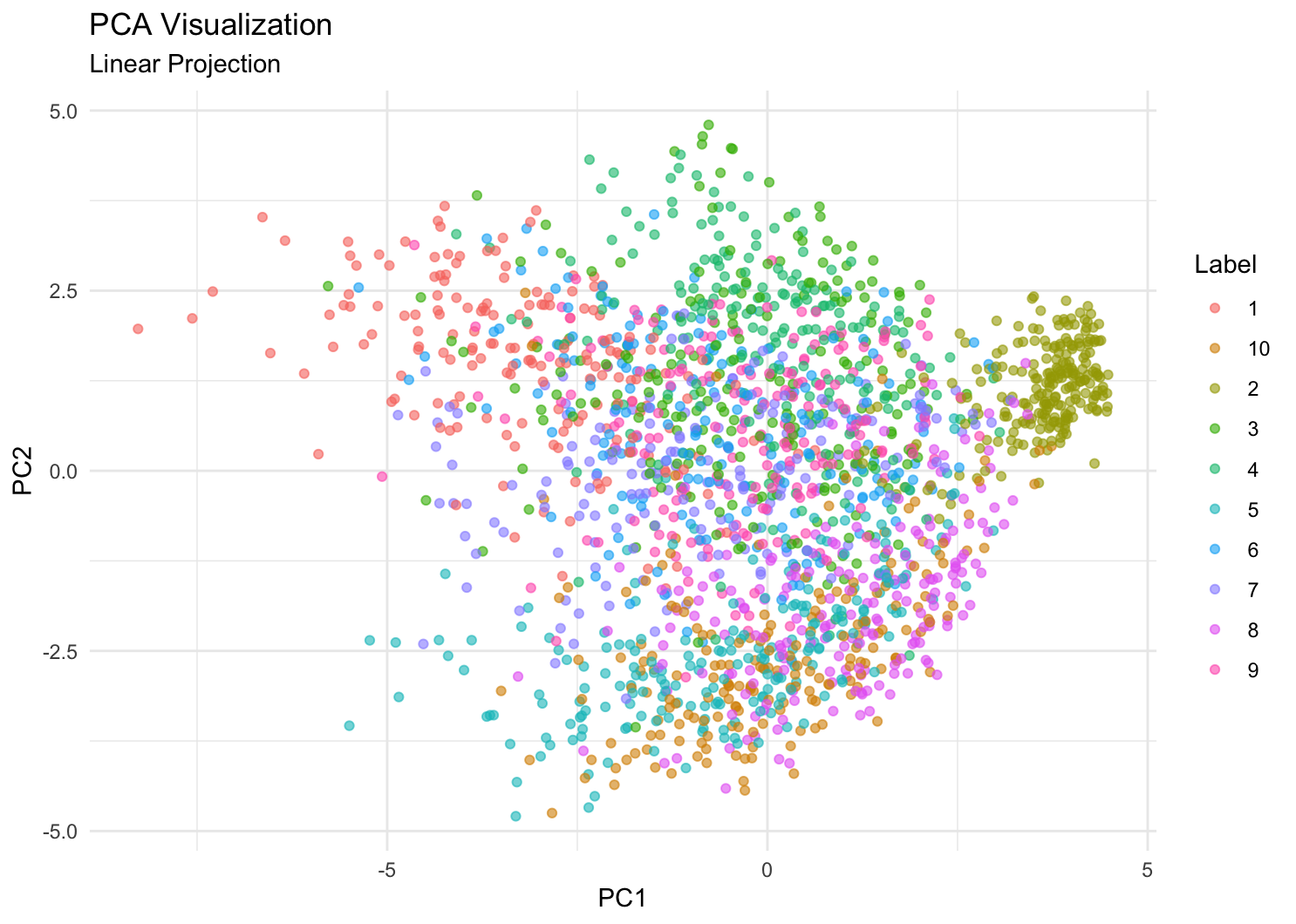
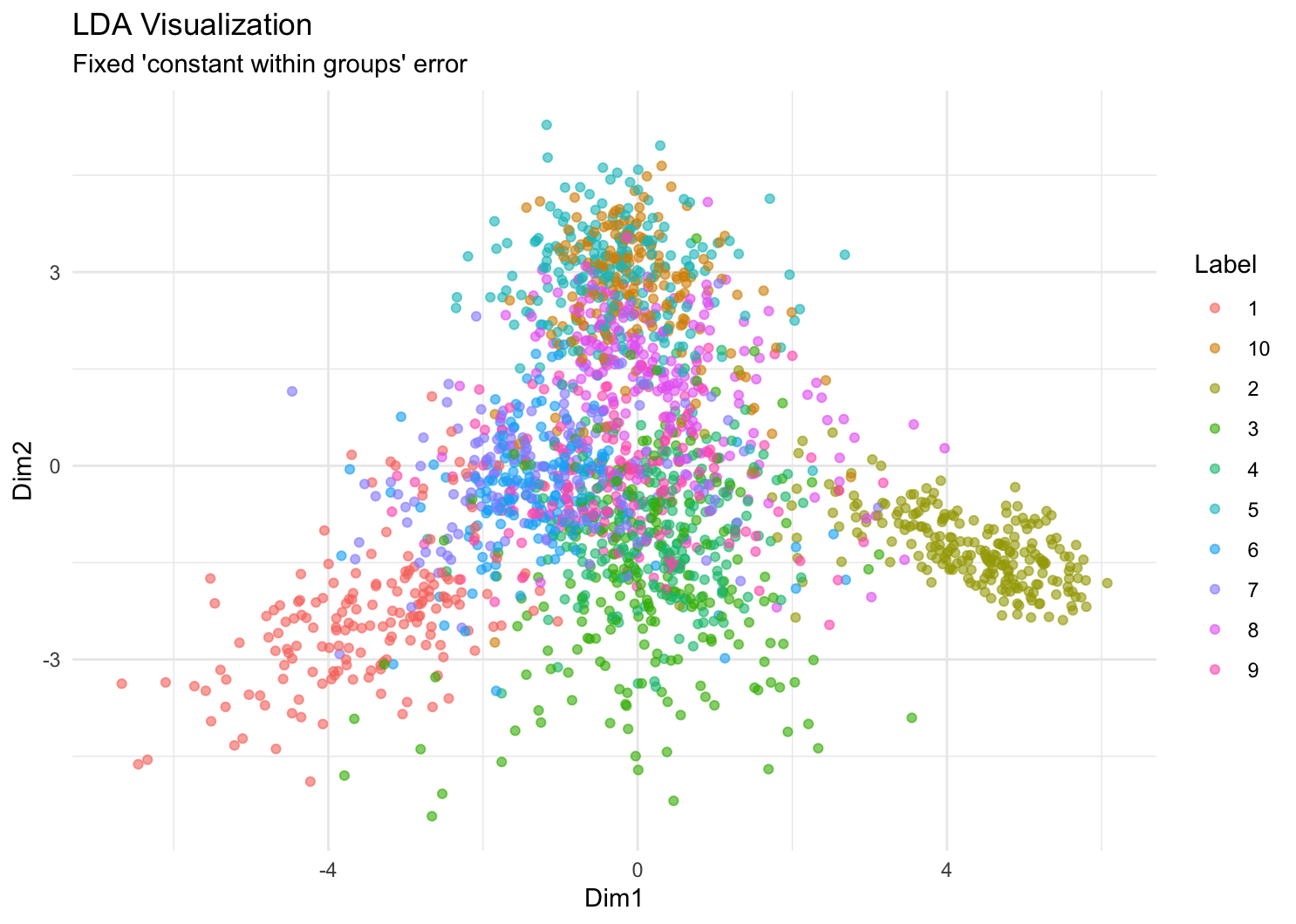
从视觉效果上看,UMAP 和 t-SNE 效果最好,LDA 次之,PCA 效果最差。UMAP 和 t-SNE 都可以保留数据的局部结构,而 LDA 则是全局的。
回到 VAE 网络架构,前一节我们将每张图片压缩到了 20 维空间,那如果我们将 VAE 将其其编码器的输出映射到 2 维空间,那 VAE 是否同样可以用于降维及可视化上?
答案显然是可以的,我们只需要将 latent_dim 设为 2,即可将 VAE 编码器的输出映射到 2 维空间。
fitted_2d <- vae_module %>%
setup(loss = vae_loss, optimizer = optim_adam) %>%
set_hparams(input_dim = 784,
hidden_dim = 400,
latent_dim = 2) %>%
fit(train_dl, epochs = 20, valid_data = test_dl) # 多跑几轮取 2000 个样本,每个样本的隐向量 \(z\) 都被映射到 2 维空间中的一个点。这些点大致分布在以 \((0, 0)\) 为中心的一个小圆圈内。VAE 降维可视化效果如下,聚类效果表现的很明显,但同 UMAP、t-SNE 等方法相比,VAE 降维的效果更平滑,有点同 LDA 类似。
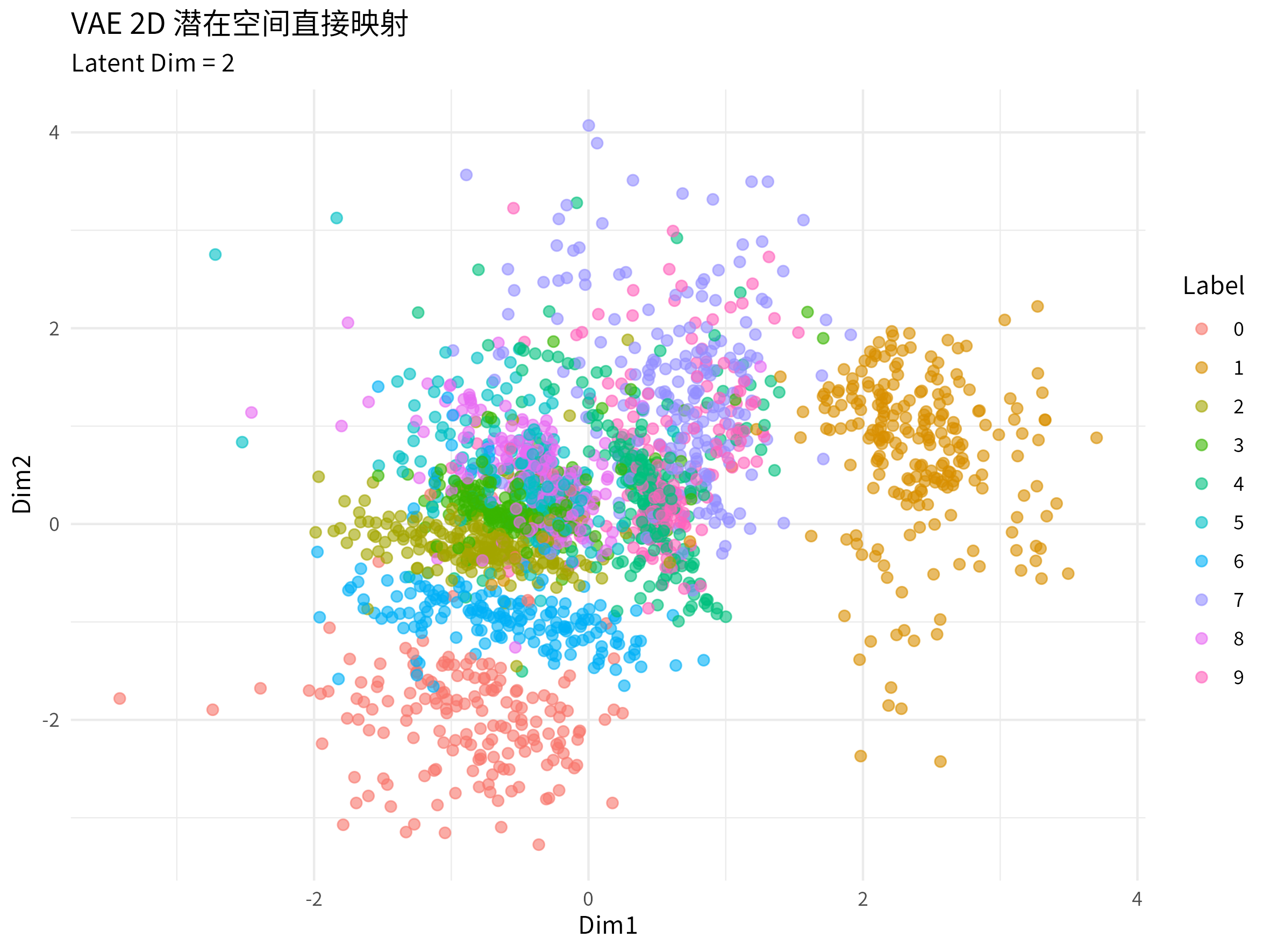
上图是 2000 个真实的手写数据被强行压缩到 2 维空间上的效果,那我们很容易想到,这个 VAE 模型在这个 2 维空间生成数字会是什么样子(空间连续性)?
我们生成一个 \(20 \times 20\) 的网格坐标,横纵坐标范围是 \([-3, 3]\),每个点都对应一个潜在空间中的点,我们将这些点输入到解码器中,得到对应的数字图像。

- 这个空间上 0-9 这 10 个数字都有呈现。
- 我们观察前 2 行,视线从图的左边移到右边,数字从“5”慢慢变成“9”,再变成“7”,最后进化为“1”。
- 最下面的几行,从 “0” 开始,再变的奇奇怪怪没见过的符号,最后进化为“1”。这些没见过的“数字”就是机器在尝试理解“0 到 1”这个连续的概念。是一个平滑的过渡。
KL 散度的强制力在 VAE 的损失函数中,有一项是 KL 散度。它的作用是强迫编码器输出的潜在分布 \(z\),必须尽可能地模仿 标准正态分布 \(N(0, 1)\)。
因为模型被这样训练了,所以绝大多数训练图片的潜在坐标 \(z\),都会落在以 0 为中心,标准差为 1 的范围内。
对于任何一个服从标准正态分布 \(N(0, 1)\) 的变量:
- \(\pm 1\) 个标准差内(即 -1 到 1):包含约 68.2% 的数据。
- \(\pm 2\) 个标准差内(即 -2 到 2):包含约 95.4% 的数据。
- \(\pm 3\) 个标准差内(即 -3 到 3):包含约 99.7% 的数据。
这也是我们为什么选 -3 到 3:如果我们画图的坐标轴设为 -3 到 3,我们就覆盖了 99.7% 的可能性。也就是几乎囊括了模型能生成的所有正常形态的数字。
11.3 VAE 时序异常检测
在工业制造、医疗诊断和金融风控中,我们面临一个共同的难题:异常样本极其稀缺。 例如,工厂里的机器绝大部分时间都在正常运转,故障数据少之又少;医院里健康人的心电图数据很多,但某种罕见心脏病的数据却很难收集。如果使用传统的分类模型(如逻辑回归或 CNN 分类器),极度的样本不平衡会导致模型失效。
本节我们将转换思路,利用 VAE 的生成特性,通过“学会正常,从而识别异常”的逻辑,解决这一问题。
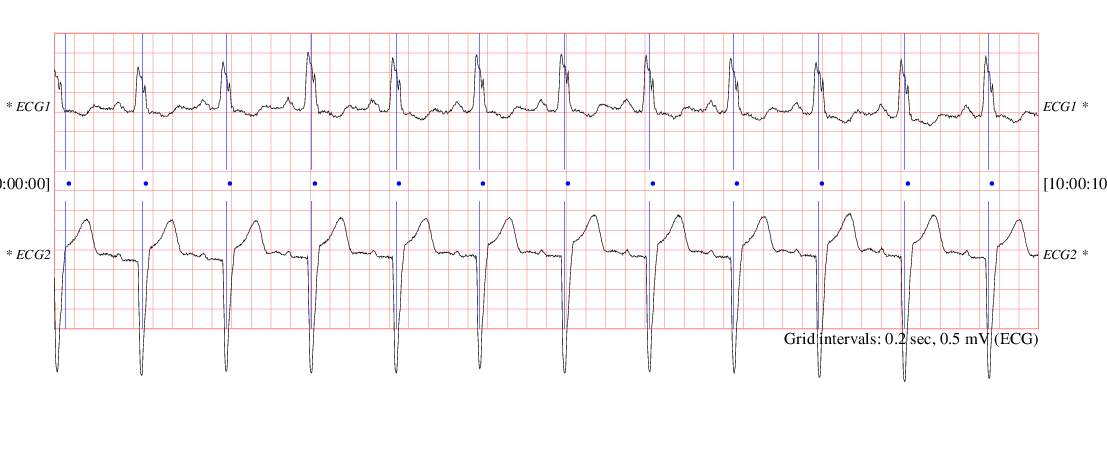
11.3.1 ECG5000
我们将使用 UCR 时间序列档案中的 ECG5000 数据集(Chen 等 2015)。这是一组记录心跳电信号的数据,每条数据包含 140 个时间步(Time Steps),相当于一次完整心跳的波形。
- 正常样本(Class 1):约 2900 条。
- 异常样本(Class 2-5):约 2100 条(包含 R-on-T 室性早搏等多种心脏异常)。
11.3.2 建模思路
先理一下思路:
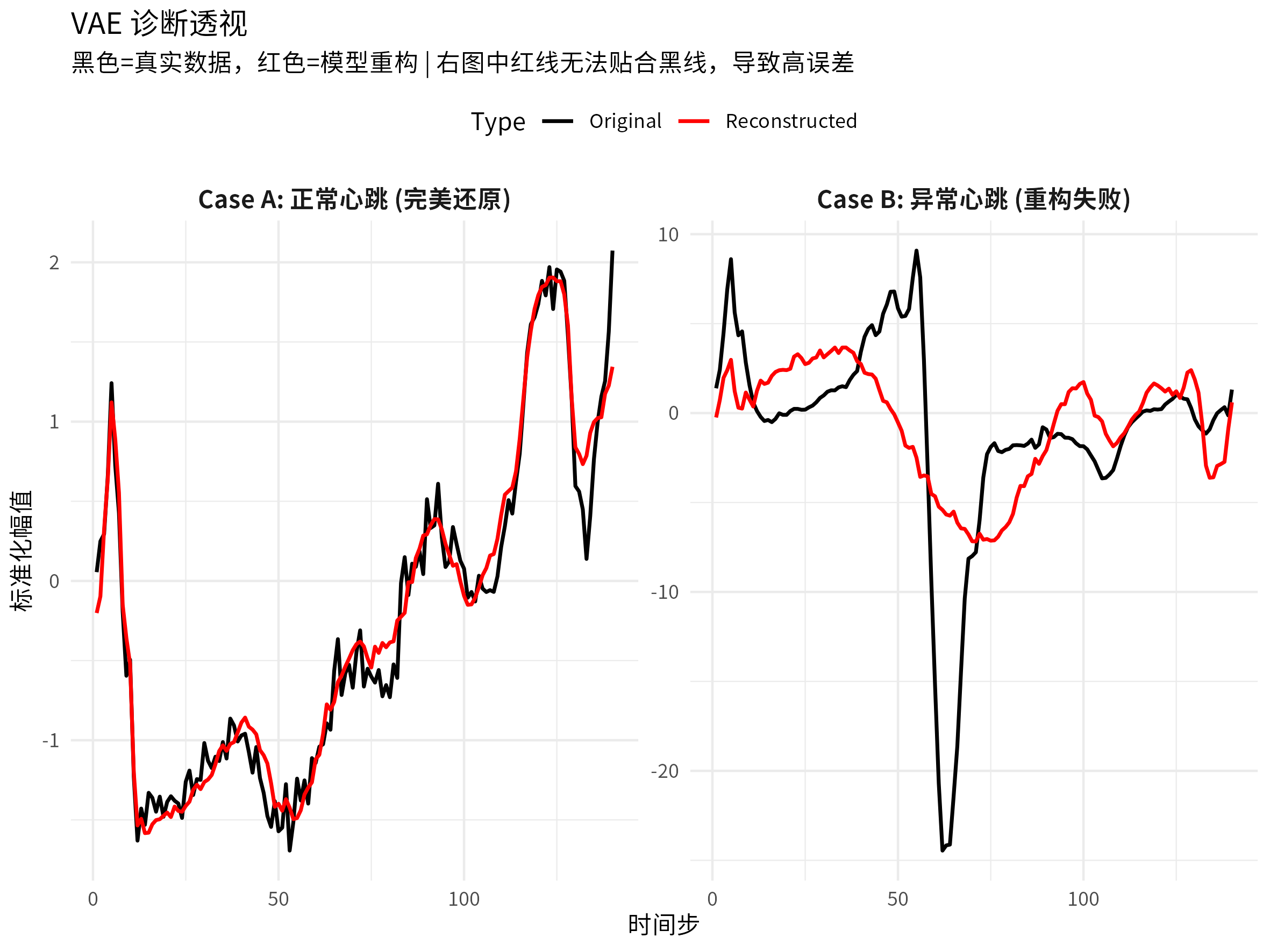
- 用正常的心电图数据训练 VAE 模型,得到模型。
- 后面所有的心电图数据都用这个模型进行重构。符合正常模式的样本,重构误差会比较小;不符合正常模式的样本,重构误差会比较大。
- 计算异常样本的重构误差(Reconstruction Error)。
- 设定一个阈值,将重构误差大于阈值的样本判断为异常。
整个建模过程同手写数字识别类似,只是将输入从图片变成了时间序列,不再多做赘述。在构建训练集和验证集时,有一点差异。
我们将正常样本的 80% 作为训练集,剩余 20% 的正常样本和所有异常样本作为验证集。也就是说我们的思路是,用正常的数据训练 VAE 模型,但使用正常 + 异常数据进行验证。
因为这种训练方式,所以 valid 集的 loss 会更高:
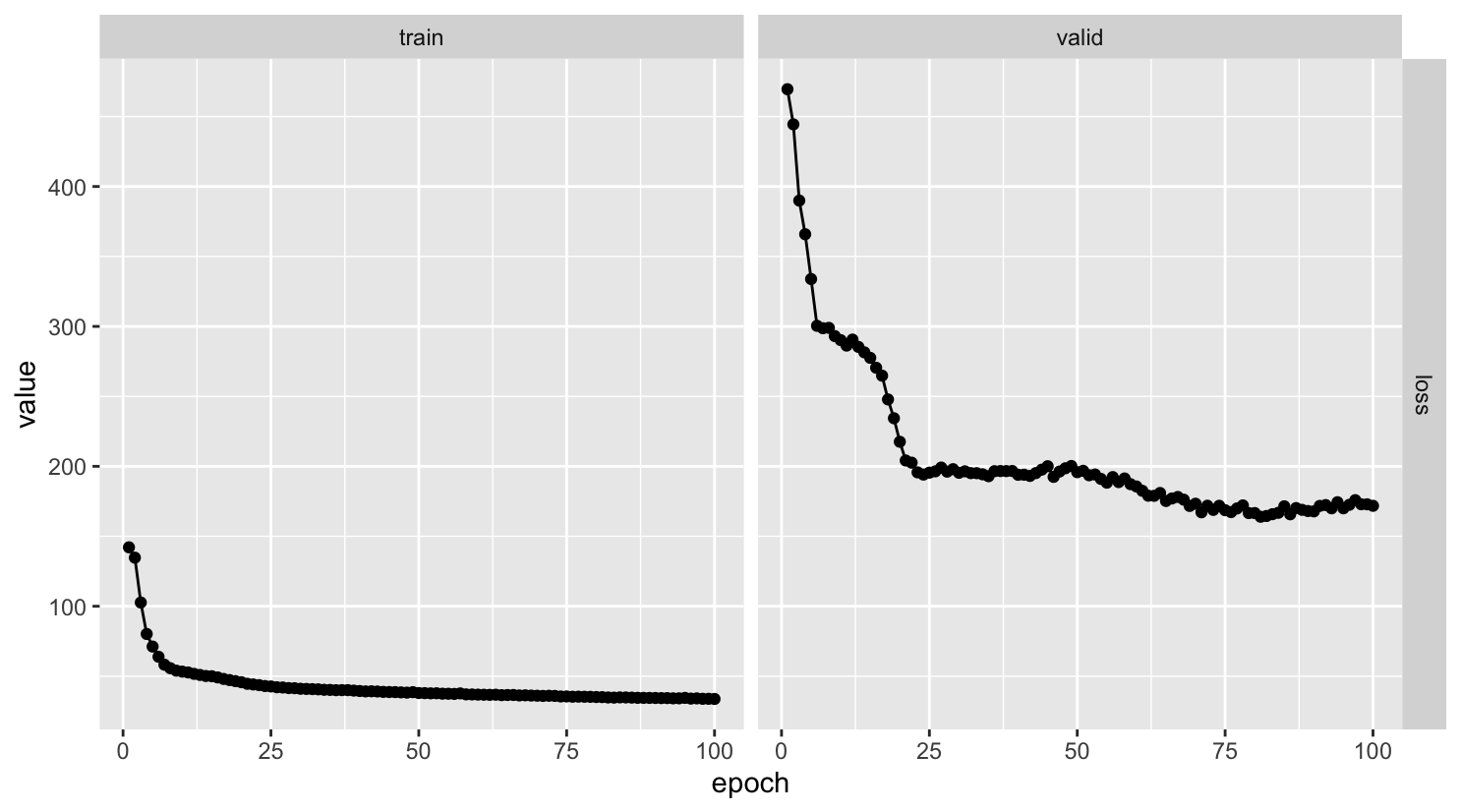
11.3.3 验证效果
当我们构建完模型后,对验证集进行预测,得到每个样本的重构误差。我们可以将这些重构误差可视化,看看异常样本的分布情况。
abs_diff <- abs(x_valid_scaled - reconstructions)
# 对每一行求均值,得到每个样本的单一分数
anomaly_scores <- rowMeans(abs_diff)我们可以将这些重构误差可视化,看看异常样本的分布情况。
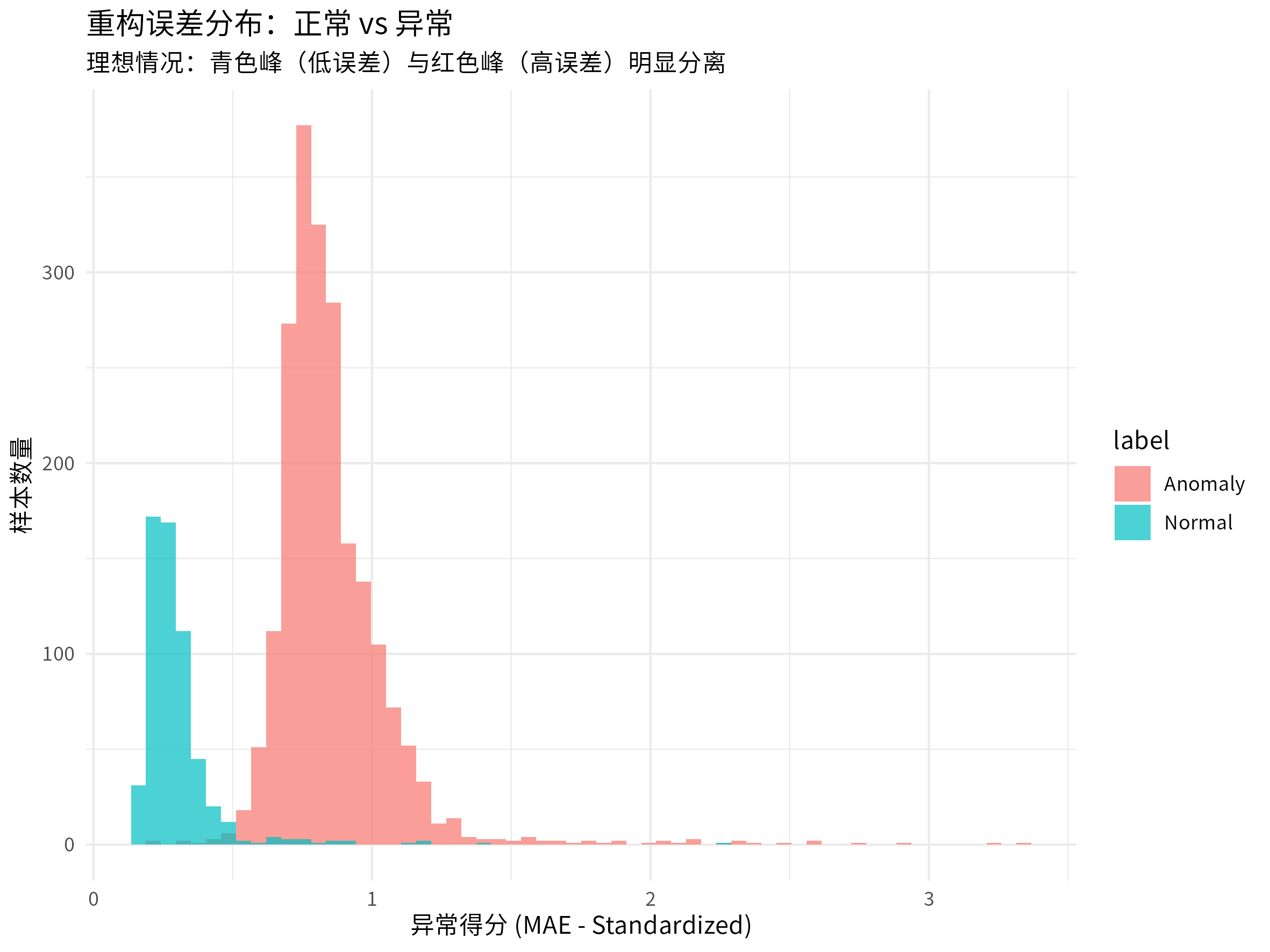
异常和正常数据显然从属于两个不同的分布。
我们也可以随机找两条异常样本和正常样本,看看它们的重构误差分布。按照建模思路,异常样本的重构误差应该要大于正常样本的重构误差。