10 图神经网络
“这是一个网络——一个全球性的网络。纳美人可以接入它。”
—— 《阿凡达》 (2009)
欢迎来到非欧几里得空间。CNN 处理的是整齐的像素网格,而 GNN 处理的是像潘多拉森林一样复杂的图结构(Graph)。在这里,数据不再孤立,重点在于关系。就像纳美人的神经连接一样,让一个节点能够聚合邻居的信,从而感知到整个网络的智慧。
10.1 从 SVD 到 GCN
在 1970 年代初期,美国社会学家 Wayne Zachary 在美国一所大学发起了一项跆拳道社团成员社交网络研究。在观察期间,俱乐部内部爆发了激烈的政治冲突。
- 一方是教练(Mr. Hi):即数据集中的 Node 1。他希望提高收费,改善教学设施。
- 一方是主管(John A):即数据集中的 Node 34。作为 俱乐部的行政管理者,他强烈反对涨价,并试图解雇教练。
随着矛盾激化,俱乐部最终分裂成了两个独立的组织。支持教练 Mr. Hi 的人跟随他成立了新俱乐部,支持主管 John A 的人留在了原俱乐部,见 图 10.1。
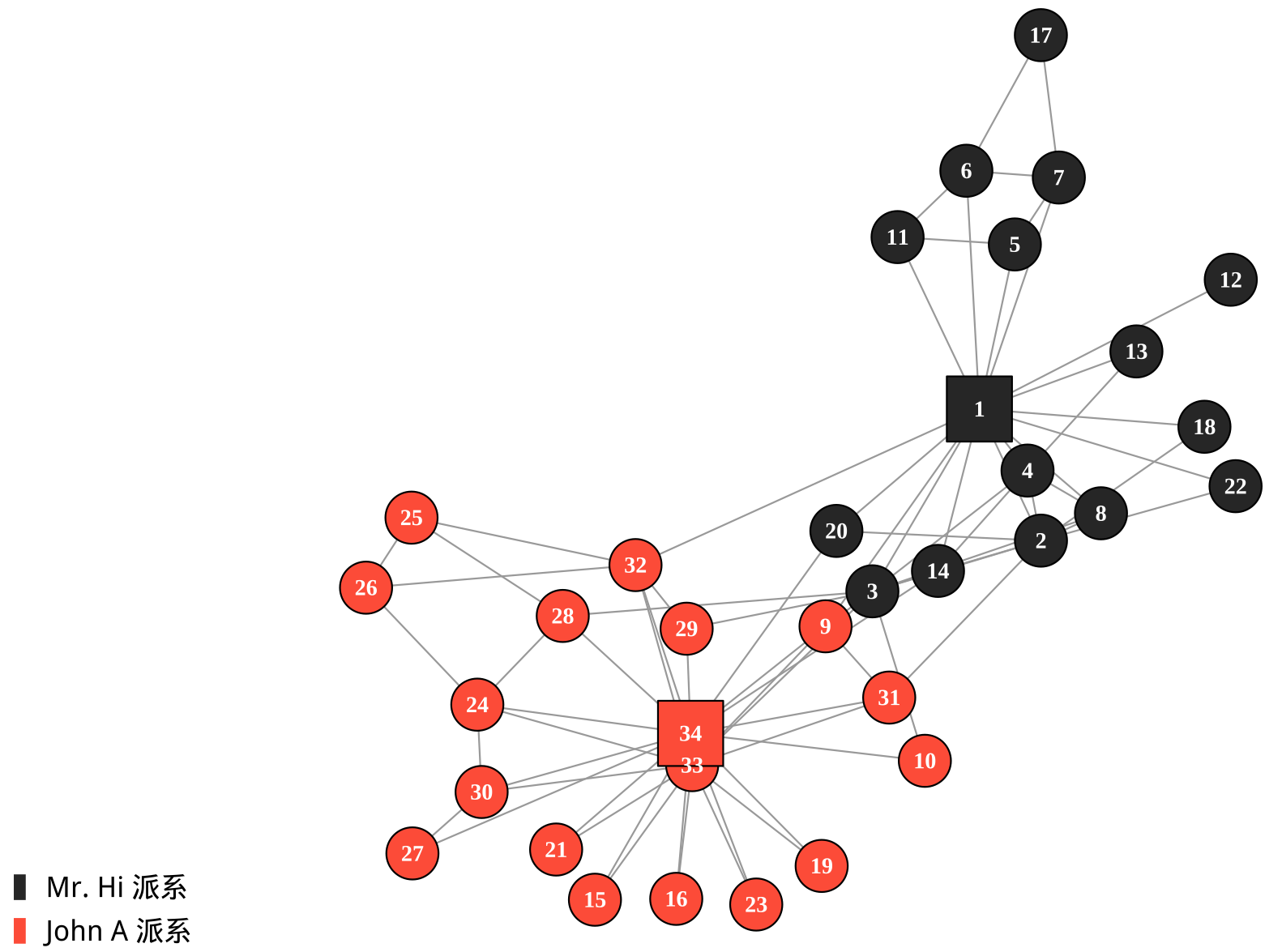
Zachary 空手道俱乐部数据集记录的是在分裂发生之前,成员之间的社交关系。
- 节点 (Nodes):34 个。代表俱乐部的 34 名成员。
- 边 (Edges):78 条。代表成员之间的友谊或互动关系。
Zachary 记录的关系不仅仅是“谁和谁一起练空手道”,而是俱乐部之外的互动(如一起吃饭、去对方家里做客等)。通过社员们的关系来预测他们最终选择的阵营,是 Zachary 当时主要研究的方向之一。
在网络中边的表示为 1-- 2 1-- 3 1-- 4 1-- 5 ...,转化为矩阵形式就是判断两两关系是否存在,存在关系则记为 1,二维空间表达见 图 10.2 (a),这个矩阵也被称为邻接矩阵 (Adjacency Matrix)。从传统统计视角看,有了这个矩阵,各个网络节点的空间表征可以通过奇异值分解来计算获得,比如将列信息放在二维空间上,其远近关系见图 10.2 (b)。
注意,因为这里的邻接矩阵是对称阵,所以奇异值分解之后的行向量信息和列向量信息表达一致,分解之后 u,v 也是一样。如果是用户购买商品的协同阵,这个场景下 u,v 的意义不同。
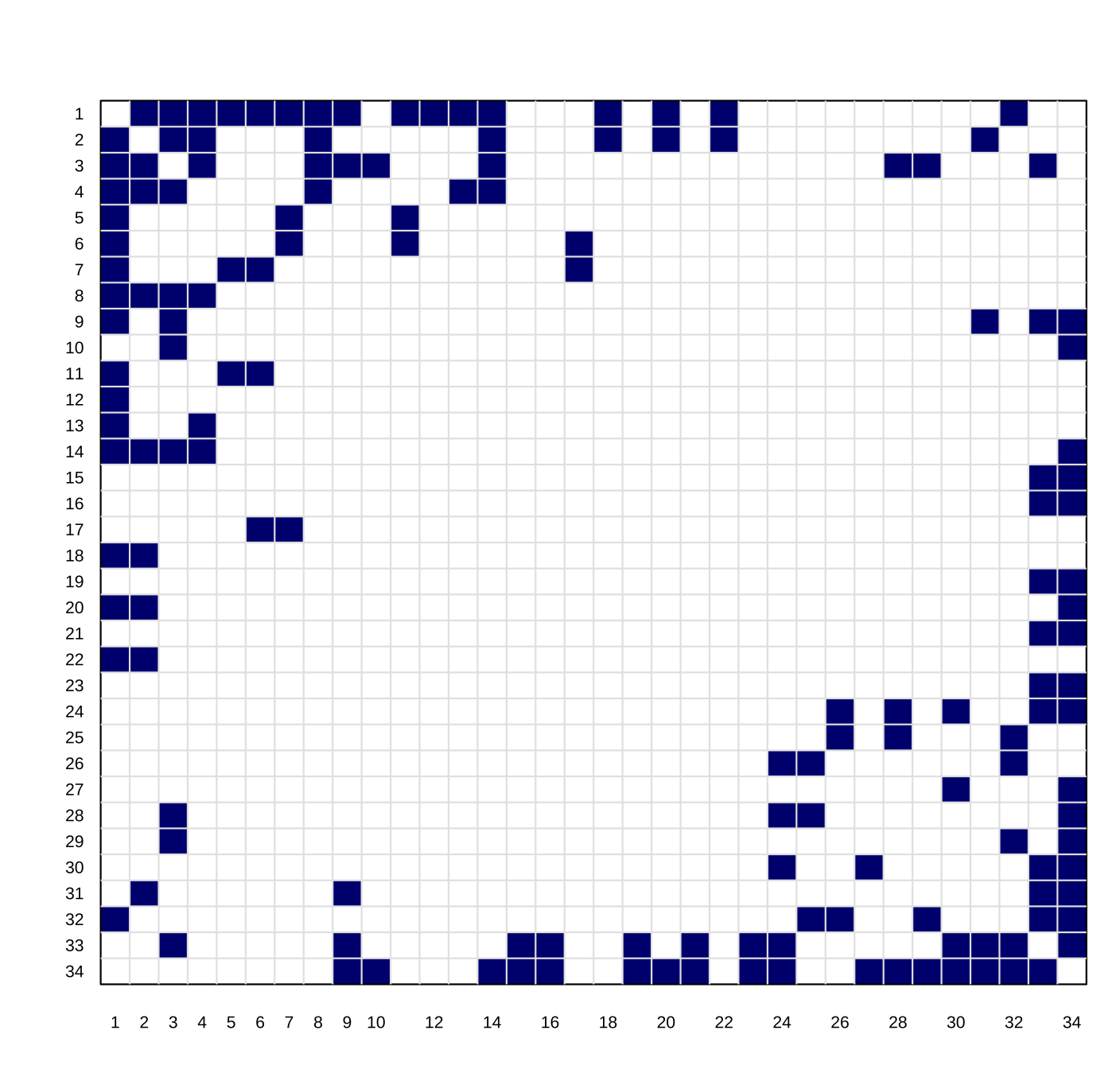
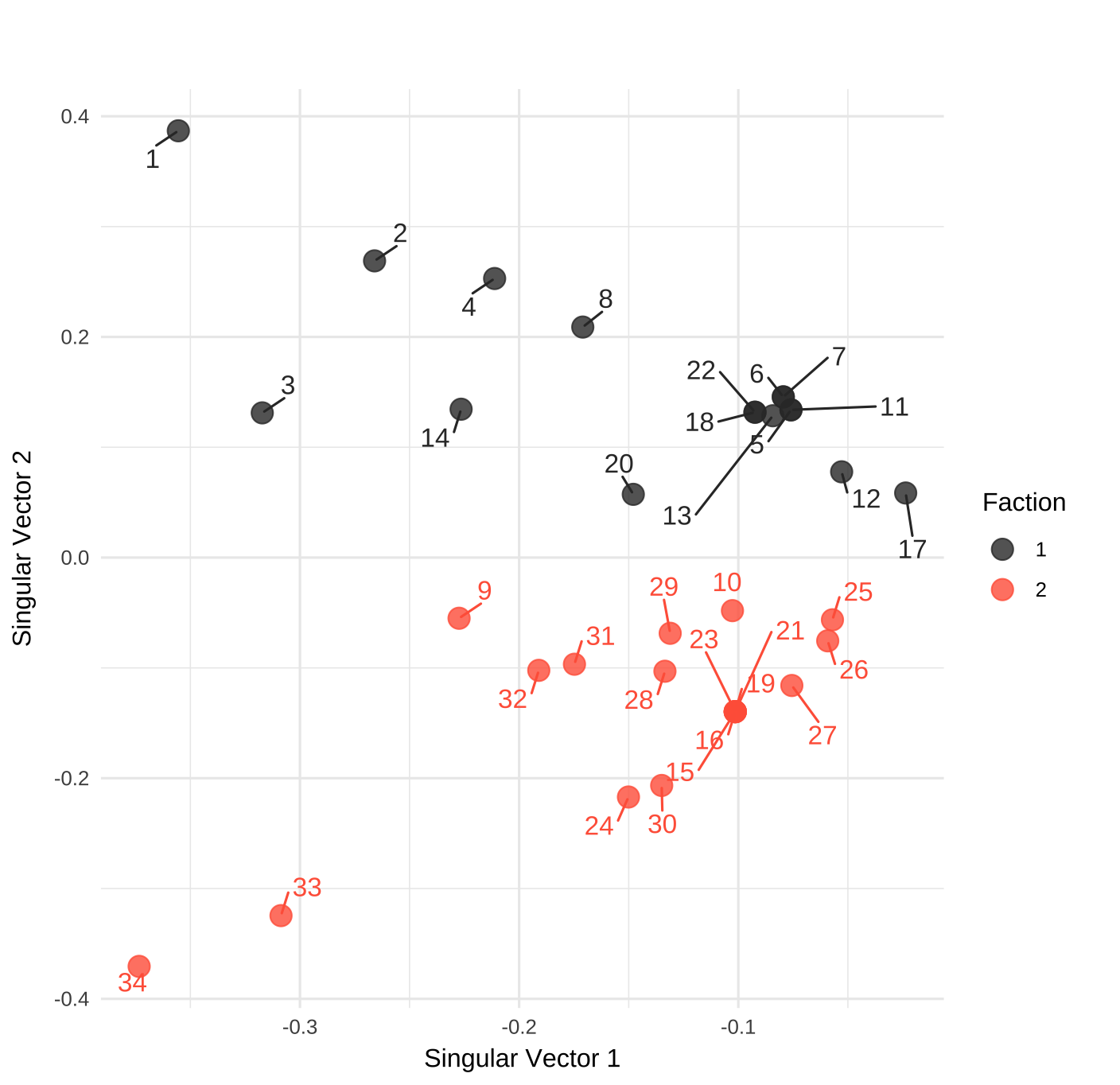
但使用奇异值分解有两个很大的弊端:
- 因为只用到了邻接信息,对于每个节点自己的信息无法使用。例如节点可能包含了肤色、性别、入会时间长短、缴纳会费金额数等1。
- 如果我们遗漏了一个节点,因为 SVD 是无监督的,那需要把这个节点放在一起重新计算。但我们期望是一个预测模型,任意新数据过来,都可以基于模型做精准判断。
随着图卷积网络 (Kipf 和 Welling 2017) Graph Convolutional Network 被提出,该方法完美地将“图结构”和“神经网络”结合在了一起。它的设计思想可以拆成三个步骤:特征变换、信息聚合、归一化。
公式通常写作:
\[ H^{(l+1)} = \sigma(\underbrace{\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}}_{\text{结构归一化}} \underbrace{X^{(l)}}_{\text{特征}} \underbrace{W^{(l)}}_{\text{权重}}) \]
我们从右向左看 GCN 到底在做什么。
一、\(XW\) 特征变化(神经网络)部分:
这就是最普通的神经网络全连接层(Linear Layer)。不看图的结构,只看节点自己的特征,也被成为节点特征矩阵(Feature Matrix),矩阵的第 \(i\) 行代表第 \(i\) 个节点的特征向量。
神经网络可以把节点的特征维度进行映射(比如从 1433 维降维到 16 维)。
二、\(A(XW)\) 信息聚合部分:
用邻接矩阵 \(A\) 去乘变换后的特征矩阵。在矩阵代数中,用邻接矩阵乘特征矩阵,等同于把邻居的特征加起来。如果 \(A_{ij} = 1\),说明节点 \(j\) 是节点 \(i\) 的邻居,那么节点 \(j\) 的特征就会被加到节点 \(i\) 身上。
原始的 \(A\) 对角线通常是 0,为了不丢失自身信息,\(\tilde{A} = A + I\)。
三、\(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\) 归一化:
如果一个节点有 1000 个邻居,那么特征值会非常大,我们需要加权平均,而不是简单的加和。
有多少个邻居对应的概念就是度矩阵(degree matrix)\(D\),如果 \(D^{-1}A\) 只乘在左边,只解决了我是接受者的问题,我同时还是一个发送者,权重也要被平均,要右乘。从我这个节点的进出都要被控制。
对于节点 \(i\) 和 \(j\) 之间的边,权重从原本的 1 变成了 \(\frac{1}{\sqrt{d_i}\sqrt{d_j}}\)。又因为 \(A\) 为了不丢失自身信息,加了自环,\(\tilde{A} = A + I\),\(\tilde{D}\) 是 \(\tilde{A}\) 的度矩阵,所以表达为矩阵 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\)
最后叠加一个常规的非线性变化 \(\sigma\)。
10.2 代码实现
首先是基础指标的计算,这里大量利用了 igraph(Antonov 等 2023) 包的基本功能。包括获取 Zachary 网络数据,取得邻接矩阵,绘制图形等。
library(igraph)
g <- make_graph("Zachary")
A_matrix <- as_adjacency_matrix(g, sparse = FALSE)
A <- torch_tensor(A_matrix, dtype = torch_float())
num_nodes <- length(V(g))
I <- torch_eye(num_nodes)
A_hat <- A + I # 添加自环,保留自身特征
D_hat_diag <- torch_sum(A_hat, dim = 2) # 计算度矩阵(按行求和)
# 计算 D^{-1/2}
D_inv_sqrt_diag <- torch_pow(D_hat_diag, -0.5)
D_inv_sqrt <- torch_diag(D_inv_sqrt_diag) # 将向量转回对角矩阵
# D^{-1/2} %*% A_hat %*% D^{-1/2}
L_sym <- torch_mm(torch_mm(D_inv_sqrt, A_hat), D_inv_sqrt)接下来是定义模型,是两层结构的 GCN:
GCN <- nn_module(
"GCN",
initialize = function(in_feat, hidden_feat, out_feat) {
# 两个线性层 (对应公式中的 W)
self$layer1 <- nn_linear(in_feat, hidden_feat)
self$layer2 <- nn_linear(hidden_feat, out_feat)
},
forward = function(x, adj) {
# --- 第一层 GCN ---
x <- self$layer1(x) # 线性变换 XW
x <- torch_mm(adj, x) # 向外走一步,直接的邻居
x <- torch_relu(x)
# --- 第二层 GCN ---
x <- self$layer2(x) # 线性变换
x <- torch_mm(adj, x) # 向外走两步,邻居的邻居
return(x) # 输出层直接输出 Logits
}
)
X <- torch_eye(num_nodes)
model <- GCN(in_feat = 34, hidden_feat = 4, out_feat = 2)
# 真实标签 (Ground Truth):
# 1 = Mr. Hi (教练), 2 = John A (主管)
manual_labels <- c(
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, # 1-10号
1, 1, 1, 1, 2, 2, 1, 1, 2, 1, # 11-20号
2, 1, 2, 2, 2, 2, 2, 2, 2, 2, # 21-30号
2, 2, 2, 2 # 31-34号
)
labels <- torch_tensor(manual_labels, dtype = torch_long())输入特征 (in_feat = 34):
因为这个数据集没有节点的个人特征(如年龄、身高等),代码使用了单位矩阵 (torch_eye) 作为特征 \(X\)。这意味着每个节点的初始特征就是它唯一的 ID(One-Hot 编码)。
第一层 (layer1):
首先对特征进行线性变换(权重矩阵 \(W_0\)),将变换后的特征与预处理好的邻接矩阵相乘。这步操作在数学上等同于:每个节点收集并聚合了它所有直接邻居的信息。最后做 relu 操作。
第二层 (layer2):
再次进行线性变换和邻接矩阵相乘。但此时节点收集了“邻居的邻居”的信息(二阶信息)。
读者也可以考虑注释掉第二层邻居的邻居这个逻辑,看看对最终预测有什么影响。
最终输出维度 out_feat = 2,代表两个阵营(Mr. Hi 和 John A)的预测分数(Logits)。
criterion <- nn_cross_entropy_loss()
optimizer <- optim_adam(model$parameters, lr = 0.01)
for (epoch in 1:100) {
optimizer$zero_grad()
output <- model(x = X, adj = L_sym)
# === 关键点:只计算两个节点的 Loss ===
# 我们假装只知道 Node 1 (索引1) 和 Node 34 (索引34) 的身份
# Node 1 是教练 (类别0), Node 34 是主管 (类别1)
# 掩码索引:
target_idx <- torch_tensor(c(1, 34), dtype = torch_long())
# 只取出这两个节点的预测结果和真实标签来计算误差
loss <- criterion(output[target_idx], labels[target_idx])
loss$backward()
optimizer$step()
}这里使用了半监督训练策略 (Semi-Supervised Learning)。虽然空手道俱乐部有 34 个人,但我们只用了 2 个人的标签来训练模型。
- 所有人都有真实标签,但在训练计算 Loss 时,被“人为隐藏”了。
- 在计算 loss 时,只传入了这两个节点的预测值和真实标签。
虽然 Loss 只由 2 个节点产生,但在计算梯度时,由于图卷积层 torch_mm(adj, x) 的存在,这两个节点的输出依赖于它们的邻居,邻居又依赖于邻居的邻居。因此,梯度会沿着图的连接结构反向传播,更新所有相关的权重。
从预测结果上看,仅仅错了一个节点 3。在其他在图神经网络的研究文献中,3号节点是整个空手道俱乐部网络中最难分类的“摇摆人。当然从概率上看也是不太容易区分。
> nnf_softmax(final_output, dim = 2)[3,]
torch_tensor
0.4081
0.5919我们将各个节点在 Mr. Hi 和 John A 两个方向上绘制散点图,同时标记实际分类,也能看到 3 很难区分:
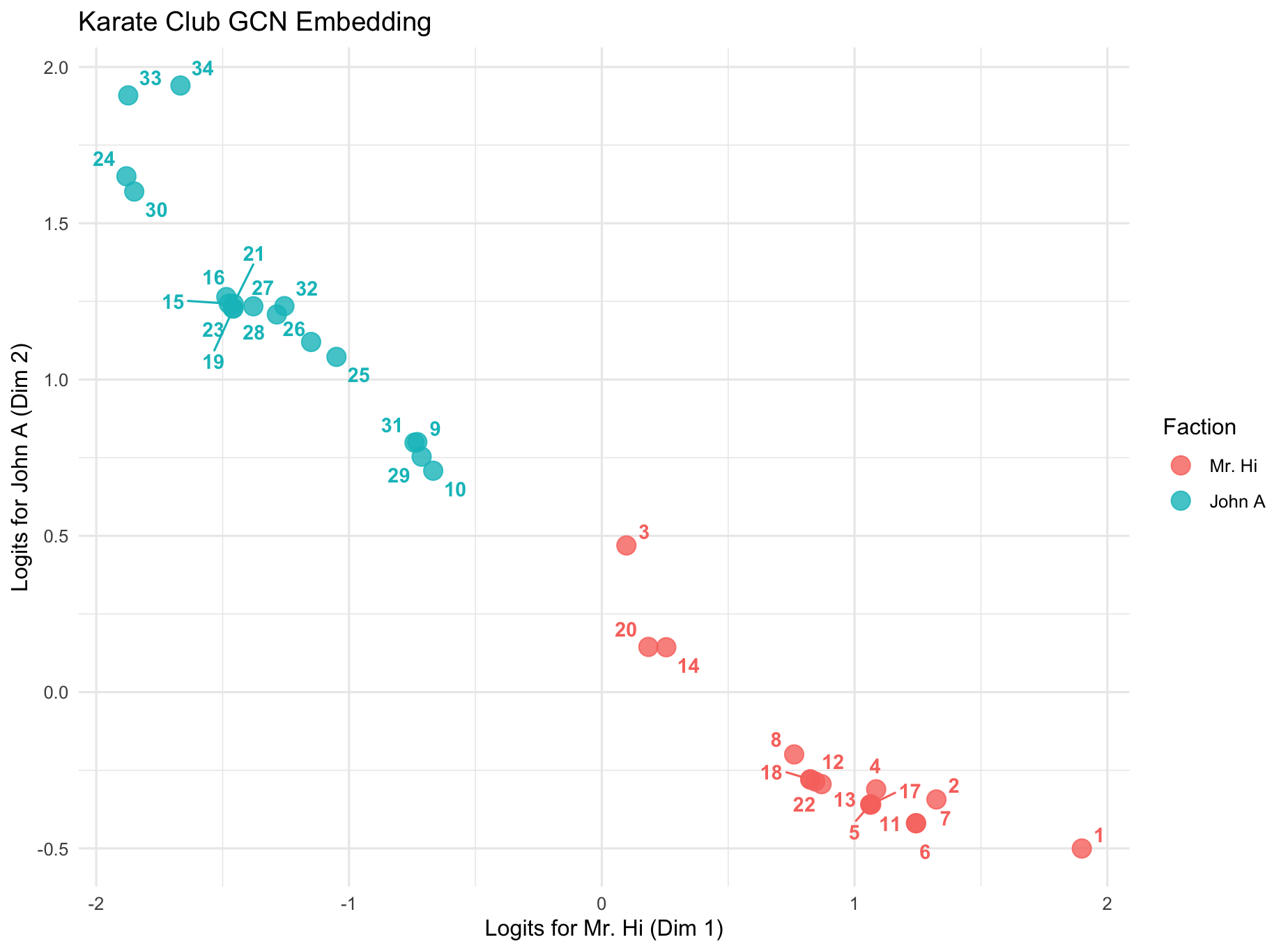
10.3 增加特征矩阵
Zachary 空手道俱乐部数据集太过于简单,它并不包含特征矩阵,本节我们引入 Cora 数据集来说明引入特征矩阵的效果。
cora.content 是 <paper_id> + <word_attributes> + <class_label> 这样的结构,第一列是 paper_id,最后一列是 class_label,中间是论文的词袋模型(Bag-of-Words)向量表示,表明特定的关键词是否出现在该文档中。我们要使用的特征矩阵就是这部分。
content <- read.table("cora.content", stringsAsFactors = FALSE)
# 提取 ID 映射
paper_ids <- content$V1
id_map <- setNames(1:length(paper_ids), paper_ids) # 将原始ID映射为 1..N 的索引
# 提取特征 (X),最后一列是分类信息
features <- as.matrix(content[, 2:(ncol(content) - 1)])
# features <- torch_eye(nrow(content))这个特征矩阵也可以设置为单位阵,即没有自身的特征,只考虑邻接矩阵的信息。
| 统计项 | 数值 | 说明 |
|---|---|---|
| 节点数 (Nodes) | 2,708 | 数据集中共有 2708 篇论文。 |
| 边数 (Edges) | 5,429 | 共有 5429 条引用记录。 |
| 特征维度 (Features) | 1,433 | 每个节点是一个 1433 维的 0/1 向量(词汇表大小为 1433)。 |
| 类别数 (Classes) | 7 | 论文被分为 7 个类别。 |
| 图类型 | 有向图 | 但在 GCN 等算法中通常被视为无向图处理。 |
7 个论文类别:
- Case Based (基于案例的推理)
- Genetic Algorithms (遗传算法)
- Neural Networks (神经网络)
- Probabilistic Methods (概率方法)
- Reinforcement Learning (强化学习)
- Rule Learning (规则学习)
- Theory (理论)
整体逻辑几乎一样,使用特征矩阵的准确率为 86.33%,不使用特征矩阵的模型准确率为 82.37%,约有 3-4 个点的差异。
利用所有论文最终训练出来的 embeddings 结果,再做 t-SNE 降维可视化:
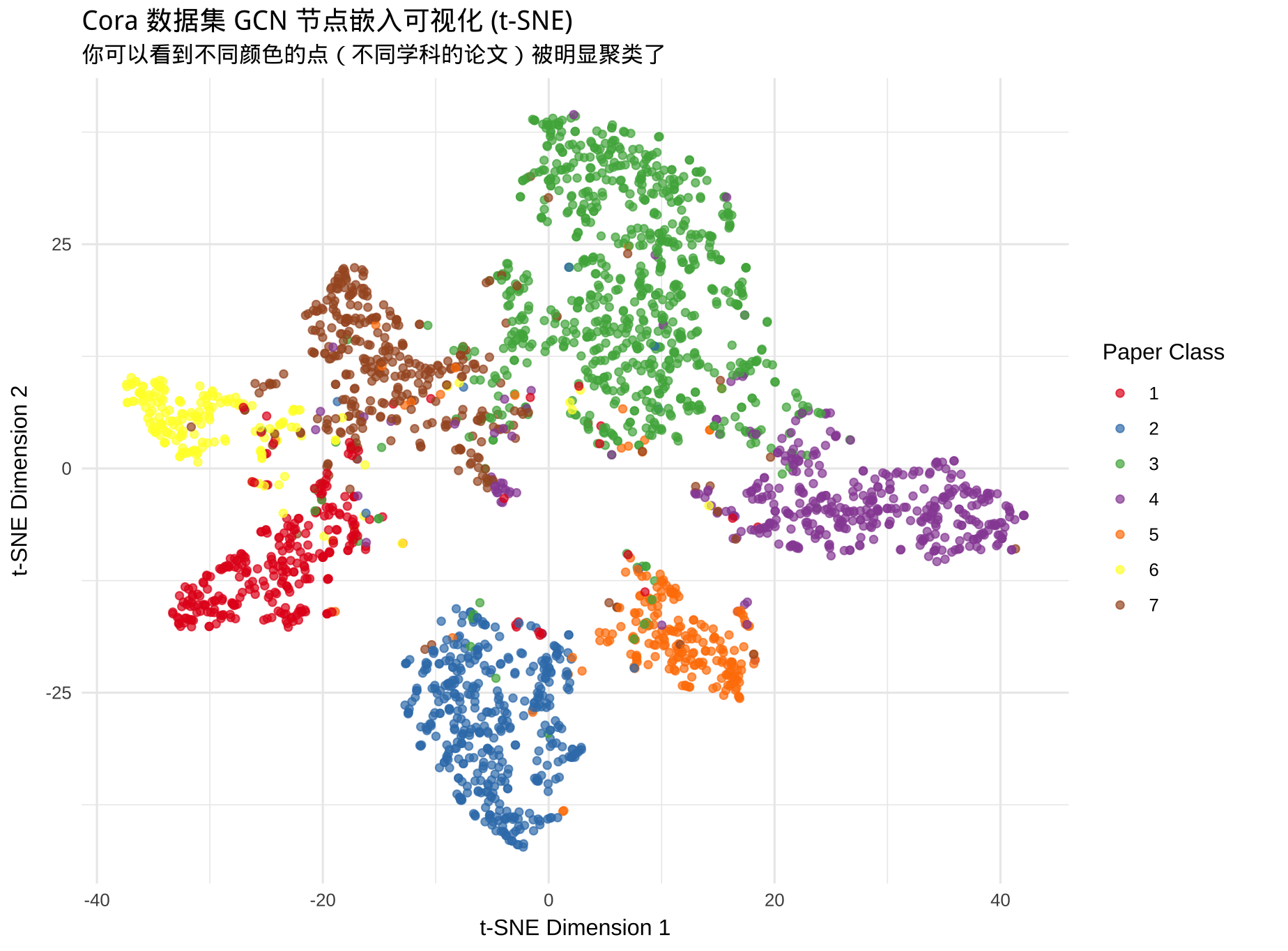
可以看到 7 团不同颜色的点簇拥在一起。这直接证明了模型学会了区分不同的论文主题。
读者也可以考虑在 GNN 体系下,如何使用 Attention 技术做优化。
在标准 GCN 的公式 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\) 中,节点 \(i\) 和邻居 \(j\) 之间的权重是静态的,完全由图的拓扑结构(度数)决定,计算结果固定为 \(\frac{1}{\sqrt{d_i d_j}}\)。这意味着,对于一篇“深度学习”的论文,\(j_1\)(另一篇深度学习论文)和 \(j_2\)(一篇毫无关系的生物学论文)如果度数相同,它们传递的信息权重是一样的。这显然不合理。
GAT (Graph Attention Network) 引入了注意力机制,让模型自己去“学”权重:
\[ \alpha_{ij} = \text{softmax}(\text{LeakyReLU}(\vec{a}^T [W\vec{h}_i || W\vec{h}_j])) \]
通过计算节点特征之间的相互关系,GAT 可以动态地分配权重。如果 \(j_1\) 的内容和 \(i\) 更相似,\(\alpha_{i,j_1}\) 的值就会更大。GAT 可以帮助图神经网络从“结构驱动(Structure-driven)”进化到了“语义驱动(Semantics-driven)”。
10.4 LightGCN
前面两个案例的只是为了演示图神经网络的思想而设置的超小型数据集,我们回归到稍稍工业化一点的场景——基于用户历史观影行为的电影推荐。
本小节使用了常见的 Movielens 10M 数据集做演示。该数据集有 1000 万条边,69878 个用户,10677 部电影。按照观影时间顺序,将前 8/9 的 ratrings 数据作为训练集,后 1/9 作为测试集2。
目标是通过用户-商品的跳转关系,来看构建一个推荐引擎,观察 GCN 模型的效果。
先通过构造一个 Item_based Collaborative Filtering 引擎来看一下我们的基线在哪里,使用 Cosine 相似来度量商品关联度:
# 归一化 R (列归一化)
item_norms <- sqrt(colSums(R_train))
item_norms[item_norms == 0] <- 1e-9
# R_norm = R * D_item^(-1/2) ... 这里简单除以模长
R_norm <- t(t(R_train) / item_norms)
# Sim = R_norm^T * R_norm
S_cosine <- t(R_norm) %*% R_norm
diag(S_cosine) <- 0 # 移除自相似在预测测试集时,我们只需要通过用户的观影历史同商品相似矩阵的“协同”关系,取 Top K 就可以获得推荐清单:
pred_strategy_cf <- function(history_mat) {
return(history_mat %*% S_cosine)
}按照这种朴素的推荐思想,我们可以计算剩余 1/9 的测试集,Top 10 的查准率和查全率3:分别为 0.16429 和 0.017401。
通过前文描述,如果我聚合了周围的节点信息,将邻接矩阵做对称归一化 \(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2}\),可以有效压制了热门节点的噪声,放大了长尾节点的特征。我们可以尝试在 item_based CF 基础上做改进:
A <- S_cosine
diag(A) <- 1 # 添加自环 (Self-loops)
# 计算度矩阵 D
d_vals <- rowSums(A)
d_inv_sqrt <- 1 / sqrt(d_vals)
d_inv_sqrt[is.infinite(d_inv_sqrt)] <- 0
D_mat <- Diagonal(x = d_inv_sqrt)
# 对称归一化
A_hat <- D_mat %*% A %*% D_mat
pred_strategy_gnn1 <- function(history_mat) {
return(history_mat %*% A_hat)
}同样观察 Top 10 推荐电影的查准率和查全率:0.16912,0.019487,效果有明显提升!
既然这种找“直接邻居”的 1-Hop 的归一化有优势,如果有更多层堆叠,是不是就能够实现信息的高阶传播(High-order Propagation)呢?
在推荐系统中,探索高阶的图拓扑结构是提升效果的关键。
10.4.1 设计哲学
答案是显然的。当我们将推荐数据视为一个“用户-物品”的二部图时,GCN 可以帮我们找到统一空间下 user 和 item 的向量,向量相似度代表了空间上的距离远近。
- user-user 相似
- user-item 相似
- item-item 相似
这种显式的结构化学习思路虽然很好,但标准的 GCN(如前文提到的 Zachary 和 Cora 案例)对于推荐系统来说太“重”了。观察原始公式
\[ H^{(l+1)} = \sigma(\tilde{D}^{-1/2}\tilde{A}\tilde{D}^{-1/2} X^{(l)} W^{(l)}) \]
会发现,标准 GCN 包含两个对推荐任务多余的操作:
- 特征变换(Feature Transformation):即公式中的 \(W\)。因为协同过滤场景的输入通常只是 ID 的 One-hot 编码,并没有丰富的语义特征,线性变换 \(W\) 徒增了计算量,甚至可能引入过拟合。
- 非线性激活(Non-linear Activation):即公式中的 \(\sigma\)(如 ReLU)。在协同过滤场景下,非线性变换对提升效果贡献甚微,甚至会阻碍梯度的传播。
LightGCN (He 等 2020) 提出了一种极简的图卷积网络,它去掉了特征变换和非线性激活,只保留了 GCN 中最核心的组件:邻居聚合(Neighborhood Aggregation)。
其单层传播公式简化为:
\[ e_u^{(k+1)} = \sum_{i \in \mathcal{N}_u} \frac{1}{\sqrt{|D_u|} \sqrt{|D_i|}} e_i^{(k)} \]
这意味着,用户在第 \(k+1\) 层的特征,仅仅是其交互过的所有物品在第 \(k\) 层特征的加权和(反之亦然)。
LightGCN 的另一个特点是对不同层 Embedding 的利用。
- 0 层(0-Hop):仅代表 ID 自身的初始特征(类似传统 MF)。
- 1 层(1-Hop):代表用户的直接交互历史(User \(\to\) Item)。
- 2 层(2-Hop):代表“和我买过一样东西的人也买过的东西”(User \(\to\) Item \(\to\) User)。
- 3 层(3-Hop):进一步捕获社群兴趣(User \(\to\) Item \(\to\) User \(\to\) Item)。
最终的输出 Embedding 是所有层 Embedding 的加权和(通常取平均):
\[ e_u = \frac{1}{K+1} \sum_{k=0}^K e_u^{(k)} \]
这种设计让 Embedding 既保留了自身的特质,又平滑了邻居的共性。
10.4.2 代码实现
先看 lightGCN 函数的初始化部分
initialize = function(num_nodes, emb_dim, n_layers) {
self$n_layers <- n_layers
self$num_nodes <- num_nodes
self$embedding <- nn_embedding(num_nodes, emb_dim)
nn_init_normal_(self$embedding$weight, std = 0.1)
},这里只对 user 和 item 进行了 normal embedding 处理。再看 forward 部分:
forward = function(adj) {
all_indices <- torch_arange(1, self$num_nodes,
dtype = torch_long(), device = adj$device)
E_current <- self$embedding(all_indices)
E_final <- E_current
# 线性图传播
for (i in 1:self$n_layers) {
E_current <- torch_matmul(adj, E_current)
E_final <- E_final + E_current
}
# 层平均
E_final <- E_final / (self$n_layers + 1)
return(E_final)
}邻接矩阵全图4是一个稀疏张量5,传入后进行线性叠加。增加一个辅助函数,通过点积来计算用户对商品的评分:
score_pairs = function(all_embs, u_indices, i_indices) {
u_emb <- all_embs[u_indices, ]
i_emb <- all_embs[i_indices, ]
torch_sum(u_emb * i_emb, dim = 2)
}在模型跟新参数的过程采用了均匀负采样(Uniform Negative Sampling)策略来构建隐式反馈数据。即,针对每一个真实的用户-物品交互(正样本,标签为 1),我们在保持用户不变的前提下,从全量物品集中随机抽取一个物品构造为负样本(标签为 0),构建成成对的数据输入。配合二元交叉熵损失函数(BCE Loss),完成模型训练:
# 1. 计算全图 Embedding (传播)
all_embs <- model(adj_sparse)
# 2. 针对 Batch 计算分数
preds <- model$score_pairs(all_embs, u_input, i_input)
# 3. Loss
loss <- nnf_binary_cross_entropy_with_logits(preds, labels)可以对比推荐 10 个商品,基线 CF 算法和 CF 1-hop 算法6 的提升效果:
| Model | Precision(%提升) | Recall(%提升) |
|---|---|---|
| Item-CF baseline | 0.1643 (0) | 0.0174 (0) |
| Graph-Regularized CF (1-Hop) | 0.1691 (2.9) | 0.0195 (12.0) |
| Graph-Regularized CF (1-Hop+0.5*2-Hop) | 0.1682 (2.4) | 0.0190 (8.9) |
| LightGCN (BCE, emb_dim=64, Layers=3) | 0.1752 (6.6) | 0.0208 (19.6) |
从表中数据可以看出图神经网络在推荐场景下的优势:
- 即便只是 1-Hop 的线性 CF(本质上类似一种归一化的矩阵分解),其 Recall 也从 Item-CF 的 0.0174 提升到了 0.0195。这说明显式地在图上进行信息传播,比单纯的基于统计共现的协同过滤更能捕捉用户偏好。
- LightGCN 的高阶优势:当层数增加到 3 层时,LightGCN 取得了最高的召回率 (0.0208)。这 3 层卷积意味着模型成功捕获了三阶邻居的信息。在电影推荐中,这意味着模型不仅推荐了“我看过的电影的相似电影”,还挖掘出了“口味相似的其他用户发现的小众佳片”。
LightGCN 以极简的结构证明了:在没有丰富内容特征的场景下,图结构本身就是最好的特征。
10.4.3 工程应用
在传统的矩阵分解(MF)模型中,用户向量(User Embedding)通常被视为模型的一个静态参数。这意味着,当用户在系统中有新的交互(例如刚刚点击了一部电影),或者一个全新的冷启动用户进入系统时,模型往往束手无策——因为它必须等待下一次全量重新训练才能更新该用户的向量参数。
但在图神经网络(特别是 LightGCN)的框架下,我们拥有了处理这一问题的天然优势。这种技术在工业界常被称为 Folding-in 或 归纳式推断(Inductive Inference)。
核心思想:用户即其行为的总和。
我们在前文中提到,LightGCN 的核心传播公式本质上是邻居聚合。如果我们忽略掉复杂的层级归一化系数,第一层图卷积可以被简单理解为:
\[ e_u \approx \text{Pool}( \{e_i | i \in \mathcal{N}_u\} ) \]
即:用户的特征向量,等于他所交互过的所有物品特征向量的聚合(通常是平均值或加权和)。
与传统 Item-CF 不同的是,Item-CF 聚合的是离散的物品 ID(拼图式的硬匹配),而 GNN 聚合的是经过训练的、包含丰富图结构信息的物品 Embedding(调色式的语义融合)。只要物品的 Embedding 训练得足够好(捕获了物品间的共现和语义关系),我们就可以通过“组装”这些物品向量,实时构建出用户的意图向量。
在工程落地实时召回时,我们通常采用“动静分离”的简化策略:
\[ e_u^{\text{realtime}} \approx \underbrace{e_u^{(0)}}_{\text{离线训练好的长期画像}} + \beta \cdot \underbrace{\text{Mean}(e_{new\_items})}_{\text{实时行为带来的增量}} \]
甚至在很多简化的 GNN 召回系统中,直接用 Item 的平均向量(Mean of Items)来代表用户当前的 Query 向量,效果已经非常好了。