5 优化与训练动力学
“生,死,再来一次。”
—— 《明日边缘》 (2014)
阿汤哥陷入了时间循环的战场。每一次战死,时间就会重置,但他并非一无所获——他保留了上一次战斗的记忆。凭借这份记忆,他在下一次重生时微调动作,比上一次走得更远。
5.1 再看反向传播
在 R torch 中,张量不仅仅是数据的容器,它还拥有记忆。当我们设置 requires_grad = TRUE 时,张量参与的每一次运算都会被记录在案。这不仅记录了结果,还记录了“我是怎么来的”。
当我们调用 backward() 时,Autograd 引擎并非在进行某种黑魔法,而是在执行一场精密的数学接力。我们可以从微观(标量)和宏观(向量)两个维度来解剖它。
一、微观视角:链式法则与“误差归因”
让我们从最简单的标量复合函数 \(L = (w \cdot x + b)^2\) 开始。
library(torch)
# 1. 定义叶子节点 (Leaf Nodes)
x <- torch_tensor(1.0)
w <- torch_tensor(2.0, requires_grad = TRUE)
b <- torch_tensor(3.0, requires_grad = TRUE)
# 2. 前向传播 (构建动态计算图)
u <- w * x # 节点 1
v <- u + b # 节点 2
L <- v ^ 2 # 节点 3 (Loss)
cat("Loss value:", L$item(), "\n")
# (2*1 + 3)^2 = 25当 \(L\)(Loss)过大时,我们需要知道是谁的错。调用 L$backward() 的过程,在工程视角下,就是一场“误差归因”(或者俗称“甩锅”)的游戏:
- \(L\) 责问 \(v\):谁让我变这么大的?\(L\) 对 \(v\) 的导数是 \(\frac{\partial L}{\partial v} = 2v\)。这是上游梯度。
- \(v\) 感到委屈:我是由 \(u\) 和 \(b\) 加起来的。于是它把责任分发下去,计算本地导数(Local Gradient)并乘以收到的上游梯度。
- \(u\) 继续甩锅:把责任推给 \(w\) 和 \(x\)…
数学上,这就是链式法则 (Chain Rule)。为了求 \(\frac{\partial L}{\partial w}\),我们将路径上的所有导数相乘:
\[ \frac{\partial L}{\partial w} = \underbrace{\frac{\partial L}{\partial v}}_{\text{上游梯度}} \cdot \underbrace{\frac{\partial v}{\partial u}}_{\text{Add层导数}} \cdot \underbrace{\frac{\partial u}{\partial w}}_{\text{Mul层导数}} \]
L$backward()
cat("w 的梯度:", w$grad$item(), "\n")
# dL/dw = 2(wx+b) * 1 * x = 2 * 5 * 1 = 10二、宏观视角:雅可比矩阵与计算墙
在中学的标量世界里,导数只是一个数值(斜率)。但在深度学习中,函数通常是向量到向量的映射 \(\mathbf{y} = f(\mathbf{x})\)。
此时,单纯的导数不足以描述关系,我们需要雅可比矩阵 (Jacobian Matrix)。雅可比矩阵记录了输出向量的每一个元素对输入向量每一个元素的敏感度:
\[ J = \frac{\partial \mathbf{y}}{\partial \mathbf{x}} = \begin{bmatrix} \frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_n} \\ \vdots & \ddots & \vdots \\ \frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_n} \end{bmatrix} \]
这里出现了一个致命的问题:
根据链式法则,如果网络有 \(N\) 层,总的变化率等于各层雅可比矩阵的连乘:\(J_{total} = J_n \cdot J_{n-1} \cdots J_1\)。假如这一层有 1000 个神经元,下一层也有 1000 个,那么雅可比矩阵的大小就是 \(1000 \times 1000\)(一百万个元素)。如果网络深达 100 层,连续进行 100 次这种巨型矩阵乘法,内存和算力会瞬间爆炸。
三、工程解法:VJP (向量-雅可比积)
幸运的是,我们不需要计算整个雅可比矩阵。
在反向传播的起点,我们的最终目标 Loss 通常是一个标量。这意味着,链式法则的最顶端,我们要传递的不是一个矩阵,而是一个梯度向量 \(\mathbf{v}\)。
利用矩阵乘法的结合律,torch 采用了一种聪明的策略:VJP (Vector-Jacobian Product)。
\[ \text{Next Gradient} = \mathbf{v} \cdot J \]
Autograd 引擎不会傻乎乎地去算 \(J \times J \times J\),而是让向量 \(\mathbf{v}\) 像接力棒一样从后往前传:
- 起点:Loss 产生初始梯度向量 \(\mathbf{v}\)。
- 接力:每一层不计算完整的雅可比矩阵 \(J\),而是直接计算 \(\mathbf{v} \cdot J\) 的结果。
- 瘦身:\(\mathbf{v}\) (向量) 乘以 \(J\) (矩阵) 的结果仍然是一个向量。
你会发现一个很有意思的结果:
- 全量雅可比(如果不优化):\(\text{矩阵} \times \text{矩阵} \dots\) (复杂度 \(O(n^3)\),内存爆炸)
- 反向传播(VJP):\(\text{向量} \times \text{矩阵} \to \text{向量}\) (复杂度 \(O(n^2)\),始终保持“瘦身”状态)
这解释了为什么深度学习极度依赖 GPU:反向传播的本质就是一系列大规模的矩阵乘法1。这也是为什么线性层 nn_linear() 的权重矩阵在反向传播时扮演了雅可比矩阵的角色。
| 概念 | 标量视角 | 向量视角 | R / torch 工程实现 |
|---|---|---|---|
| 基本单元 | 数值 (Scalar) | 向量 (Vector) | Tensor |
| 变化率 | 导数 (Derivative) | 雅可比矩阵 (Jacobian) | grad_fn / 权重矩阵 (Linear层) |
| 链式法则 | 简单的乘法 | 矩阵乘法 (\(J_2 \times J_1\)) | VJP (向量 \(\times\) 矩阵) |
| 计算流向 | 无所谓 | 反向 (Reverse Mode) | backward() |
四、为什么 backward() 有时需要参数?
理解了 VJP,你就能解开 torch 中最令人困惑的行为之一:backward(gradient=...) 参数。当你调用 loss$backward() 时,因为 loss 是标量,初始的梯度向量 \(\mathbf{v}\) 默认为 [1.0]。
但是,如果你的输出 y 不是标量,而是一个向量(例如多目标优化,或者你要计算非 Loss 节点的导数),torch 就会因为没有向量 \(\mathbf{v}\)),没法做 后续的 VJP,此时就会报错。
你必须手动提供这个外部梯度向量:
# 场景:输出是一个向量 [y1, y2, y3]
x <- torch_tensor(c(1, 2, 3), requires_grad = TRUE)
y <- x^2 # y = [1, 4, 9]
# y$backward() # 错误!grad can be implicitly created only for scalar outputs
# 我们必须提供一个向量 v,作为 VJP 的初始“接力棒”
# 假设我们认为 y 的三个元素同等重要,给权重 1
v <- torch_tensor(c(1, 1, 1))
y$backward(gradient = v)
x$grad
# 输出: [2, 4, 6]
# 数学本质: J 是对角矩阵 diag(2x),v=[1,1,1]
# Result = v * J = [1*2x1, 1*2x2, 1*2x3]5.2 梯度下降演进和实现
通过反向传播,我们已经拿到了每一个参数的梯度(\(\nabla w\))。梯度告诉了我们需要往哪个方向走才能让 Loss 变小。
但是,“往那个方向走多远?” 以及 “是每次都只看当下的梯度,还是参考一下之前的惯性?”这两个问题决定了训练是快速收敛,还是在原地震荡,甚至发散。这就是优化算法(Optimizer)研究的领域。我们将从最基础的随机梯度下降出发,一路演进到现代大模型标配的 AdamW。
5.2.1 批量大小的权衡
最朴素的更新公式是:
\[ w_{t+1} = w_t - \eta \cdot \nabla L(w_t) \]
其中 \(\eta\) 是学习率。但在计算 \(\nabla L\) 时,我们需要用到多少数据?
批量梯度下降 (Batch GD) 与随机梯度下降 (SGD)
Batch GD:每次更新都计算所有样本的梯度。
- 做法:把所有训练数据都算一遍,求平均梯度,然后走一步。
- 优点:走得很稳,方向极准。
- 缺点:内存瞬间爆炸;每次更新都要算很久,且容易卡在鞍点(Saddle Point)出不来(因为梯度太稳了,没有噪声)。
SGD:每次更新只用一个样本。
- 做法:每次只随机抽取一条数据,算梯度,走一步。
- 优点:更新频率极快,引入了大量随机噪声,有助于跳出局部最优。
- 缺点:无法利用 GPU 矩阵并行加速(GPU 讨厌处理标量);Loss 曲线剧烈震荡,难以收敛。
在这两种方法之间是否有折中方案呢?答案是显然的——Mini-batch SGD:每次用一小批(比如 32 或 64 个)更新梯度。这是工业界深度学习的标准做法。每个批次的样本可以打包成一个矩阵,能充分利用 GPU 的并行优势。而且引入了适度的“梯度噪声”(Gradient Noise)。这种噪声被证明具有正则化效果,能帮助模型找到更加平坦(Robust)的极小值区域。
回顾:Batch Size 不是在优化器中设置,而是在 dataloader 中设置(下一章会详细介绍)。
# 数据加载器,定义每次喂给优化器多少数据量
train_dl <- dataloader(train_ds, batch_size = 64, shuffle = TRUE)5.2.2 冲量和自适应算法
在实际地形(损失曲面)中,SGD 往往面临“病态曲率”的问题。以最简单的凸函数 \(f(x) = x^2\) 为例,其梯度为 \(2x\)。梯度下降的迭代公式为:
\[ x_{t+1} = x_t - \eta \cdot (2x_t) = x_t (1 - 2\eta) \]
这本质上是一个等比数列,公比为 \(q = (1 - 2\eta)\)。迭代的收敛性完全取决于 \(|q|\) 的大小:
- 单调收敛:\(0 < q < 1 \Rightarrow \eta < 0.5\)(始终在同侧靠近 0)。
- 震荡收敛:\(-1 < q < 0 \Rightarrow 0.5 < \eta < 1.0\)(在 0 两侧跳跃,但幅度减小)。
- 发散:\(|q| > 1 \Rightarrow \eta > 1.0\)(跳跃幅度无限增大)。
看以 \(x=-10\) 为起点,到最优点 \(x=0\) 的优化路径:
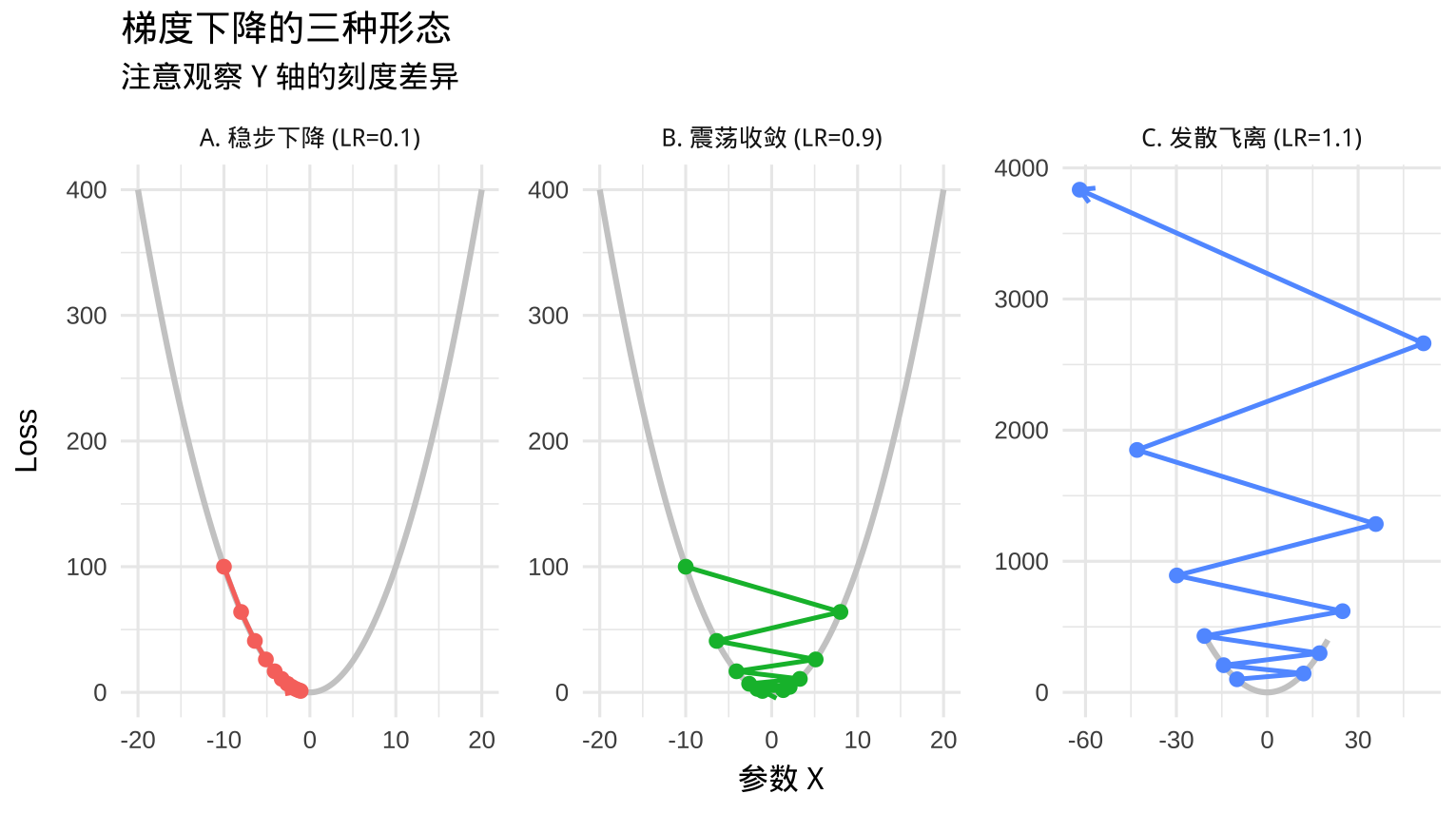
仔细观察上图的中间情况(震荡收敛),你会发现一个令人抓狂的现象:模型花费了大量的步数在山谷的两壁之间“反复横跳”。这是普通随机梯度下降(SGD)最大的缺陷——它是“健忘”的。它只根据当前的脚下的坡度决定方向,完全不考虑之前走了几千步积累下来的“大势”。但如果我们能给优化器一种“惯性”,让它保持往这个趋势,那么这种无意义的横向震荡就会被平滑掉。
这就是动量法(Momentum)诞生的初衷。其更新公式如下:
\[ \begin{aligned} v_{t} &= \gamma v_{t-1} + \eta \nabla_\theta J(\theta_t) \\ \theta_{t+1} &= \theta_t - v_{t} \end{aligned} \]
其中 \(v_t\) 是速度向量,\(\gamma\) 是动量系数(通常设为 0.9),\(\eta\) 是学习率。
- 在震荡方向:正负梯度相互抵消,速度减小,震荡受到抑制。
- 在前进方向:梯度方向一致,速度不断累积,加速收敛。
标准动量是“先计算梯度,再根据累积速度跳跃”;而 Nesterov 是“先根据累积速度跳跃,在预判的新位置计算梯度”。这种“先跳后看”的策略提供了更强的校正能力。
在 R torch 中启用动量只需添加一个参数:
# nesterov = TRUE 要求 momentum > 0
optimizer <- optim_sgd(
model$parameters,
lr = 0.01,
momentum = 0.9,
nesterov = TRUE
)Momentum 虽然解决了震荡问题,但它所有的参数共享同一个学习率 \(\eta\)。这在处理稀疏特征时(如 NLP 中的生僻词 Embedding)非常低效:
- 高频词梯度更新频繁,需要小学习率。
- 生僻词梯度偶尔出现一次,如果学习率太小,根本学不动。
我们需要给每一个参数定制一个专属的学习率。这就是自适应学习率(Adaptive Learning Rate)算法家族的起源。
1. RMSprop
RMSprop 的核心思想是:“根据路况调整底盘”。它维护一个梯度平方的移动平均值 \(v_t\)。如果某个参数的历史梯度一直很大(很陡),我们就除以 \(\sqrt{v_t}\) 来调低它的学习率;反之则调高。
2. Adam (Adaptive Moment Estimation)
这是目前也是过去十年最流行的优化器。简单来说: \[ \text{Adam} = \text{Momentum (一阶矩)} + \text{RMSprop (二阶矩)} \]
它既有惯性(跑得快),又能自适应(不同参数不同步长)。
3. AdamW:修正后的 Adam
在 R torch 中,你会发现同时存在 optim_adam 和 optim_adamw。如果你在训练 Transformer 或任何现代深度网络,请无脑选择 optim_adamw。
在标准的 SGD 中,L2 正则化 2 等价于权重衰减(Weight Decay)。但在自适应算法(如 Adam)中,正则化项 \(\lambda w_t\) 也被 Adam 的自适应机制(除以 \(\sqrt{v_t}\))给“缩放”了,L2 的正则化力度被扭曲,导致正则化效果不可控。
AdamW (Adam with Decoupled Weight Decay) 修正了这个问题:它将权重衰减项从梯度更新的计算中剥离出来,直接作用于参数本身。
\[ \theta_{t+1} = \underbrace{\theta_t - \eta \cdot \text{Adam}(\nabla L)}_{\text{基于 Loss 的优化}} - \underbrace{\eta \lambda \theta_t}_{\text{纯粹的权重衰减}} \]
除非你有明确理由(如复现旧论文),否则建议优先使用 AdamW 替代 Adam。
# weight_decay 通常设置为 1e-2 到 1e-4 之间
optimizer <- optim_adamw(
model$parameters,
lr = 1e-3,
betas = c(0.9, 0.999), # 默认的一阶和二阶矩系数
weight_decay = 0.01
)5.2.3 三种优化器的对比
让读者有一个直观感受,我们利用 Beale 函数测试不同优化器的效果。它有一个平坦且狭长的谷底,极小值位于 \((3, 0.5)\)。
\[ f(x, y) = (1.5 - x + xy)^2 + (2.25 - x + xy^2)^2 + (2.625 - x + xy^3)^2 \]
这种地形对优化器非常不友好:梯度在大部分区域很平缓(导数小),导致步伐迈不开;而在接近极值点时形状又很狭长。
先定义这个函数:
library(torch)
library(tidyverse)
beale_loss <- function(x, y) {
(1.5 - x + x * y)^2 +
(2.25 - x + x * y^2)^2 +
(2.625 - x + x * y^3)^2
}我们尝试比较标准 SGD、SGD + 动量法、Adam 三种策略在优化路径上的效果。为了公平起见,我们创建一个辅助函数,输入优化器名称,输出它从起点 \((0, 0)\) 走到终点的完整轨迹坐标。
run_optim <- function(optim_func, name, lr, steps = 200) {
x <- torch_tensor(0.0, requires_grad = TRUE)
y <- torch_tensor(0.0, requires_grad = TRUE)
# 动态调用优化器函数
opt <- optim_func(list(x, y), lr = lr)
# 利用 purrr 包做循环
# map_dfr 自动将每次迭代的结果合并为 tibble
purrr::map_dfr(1:steps, function(i) {
opt$zero_grad()
loss <- beale_loss(x, y)
loss$backward()
opt$step()
list(step = i, x = x$item(), y = y$item())
}) %>%
mutate(optimizer = paste0(name, " (lr=", lr, ")"))
}我们让三个优化器跑默认的 200 步。注意,为了展示 Adam 的高效,我们可以给它设置稍大的学习率,而 SGD 如果学习率太大容易飞出屏幕。
# 特殊处理:Momentum 需要额外的参数,这里简单处理
all_paths <- list(
run_optim(optim_sgd, "SGD", 0.01),
run_optim(function(p, lr)optim_sgd(p, lr, momentum = 0.9),
"Momentum", 0.01),
run_optim(optim_adam, "Adam", 0.1)
) %>% bind_rows()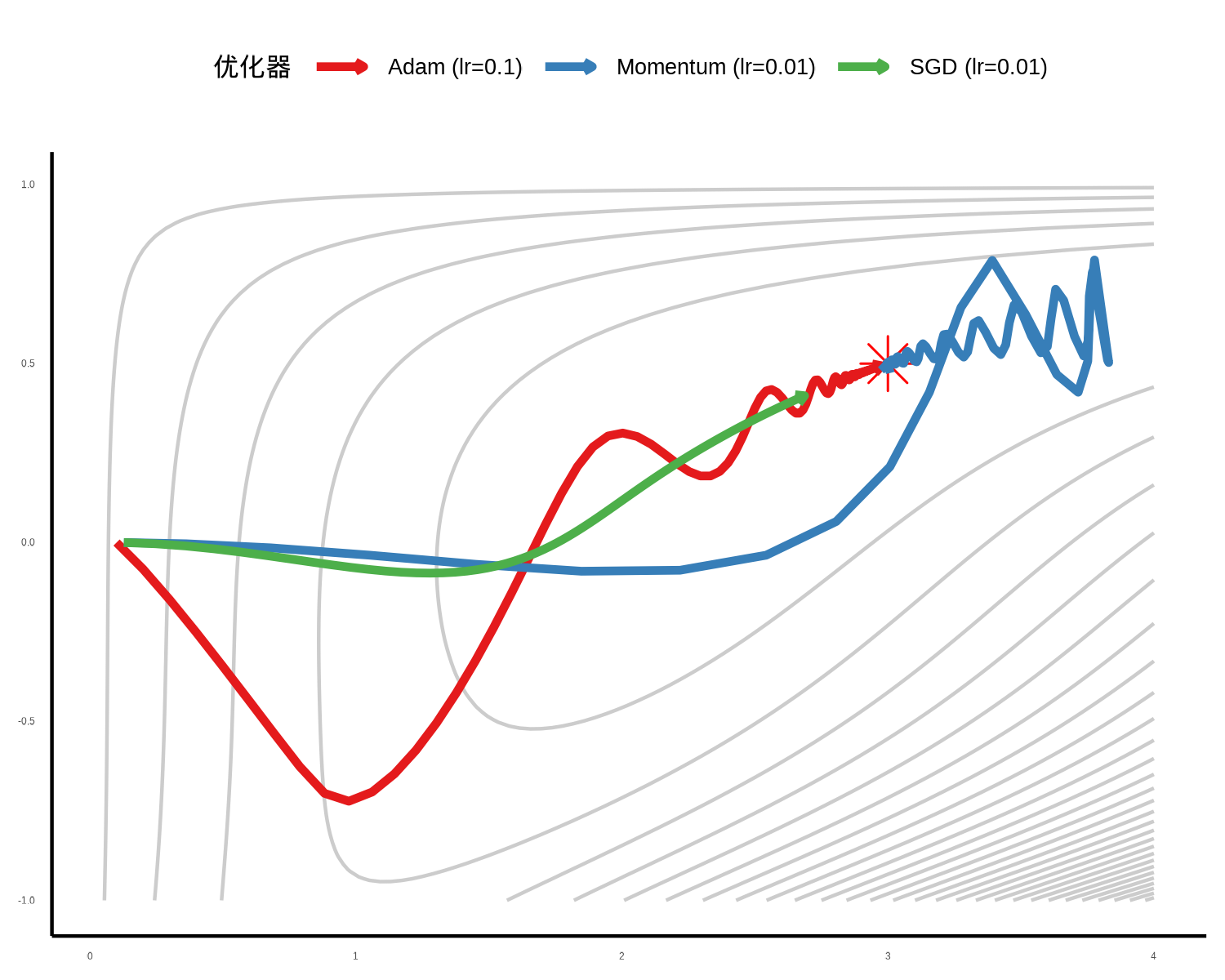
可以从两组策略中看到收敛过程到达最优解(十字点)的速度:
绿色的标准 SGD:平滑,直冲最优解的位置。但像一个摩擦力极大的滑块,走到一半走不动了。因为 LR 小,它不震荡了,但也不前进了。SGD 没有任何记忆。它只看当下的梯度。在 Beale 函数这种长峡谷中,如果学习率小,它就走不动;如果学习率大,它就会在峡谷两壁之间来回震荡,无法沿谷底前进。
蓝色的 Momentum:起步后,它迅速加速(因为梯度方向一致,速度累积)。有趣的是,你会看到它冲过了头(Overshoot),甚至绕着目标点转了一圈才慢慢停下来。这就是为什么在使用 Momentum 时,往往需要配合学习率衰减
红色的 Adam:除开头外,线条几乎是直奔目标而去。它似乎能“看穿”地形,直接切入谷底,并且迅速收敛到红星附近。这是自适应学习率的威力。Adam 发现某个方向(纵向)坡度缓,就自动调大该方向的步长;发现某个方向(横向)震荡大,就调小步长。它相当于给参数空间进行了“归一化”,让每一步都走得极其高效。
5.2.4 State Dict (状态字典)
前文提到 Momentum 和 Adam 需要利用历史梯度。那么这些历史信息存在哪里呢?答案是 state_dict。
当我们实例化一个优化器时,它并没有立即分配内存存储这些信息。但在第一次调用 step() 后,优化器会初始化其内部状态。
让我们看看一个带 Momentum 的 SGD 优化器内部长什么样:
model <- nn_linear(1, 1)
# 定义带 0.9 动量的 SGD
opt <- optim_sgd(model$parameters, lr = 0.1, momentum = 0.9)
# 进行一次虚拟更新,激活状态
loss <- model(torch_tensor(matrix(1)))
loss$backward()
opt$step()
# 查看优化器的内部状态
state <- opt$state_dict()
# state_dict 包含两个部分:
# 1. param_groups: 学习率、动量系数等超参数
# 2. state: 存储动量缓存 (Momentum Buffer)
print(names(state))在 state 中,你会发现对应每个参数都有一个动量缓冲区(其形状与参数一致)。这就是为什么我们在保存模型检查点(Checkpoint)时,不仅要保存模型的权重,还要保存优化器的 state_dict。
如果只保存了模型权重,恢复训练时,优化器丢失了之前的“惯性”(动量归零),模型往往需要震荡很久才能重新进入最佳下降状态。
另外,我们还可以针对不同层设置不同学习率。比如在迁移学习(Transfer Learning)中,我们经常需要:
- 冻结预训练的骨干网络(Backbone),或者只给它极小的学习率。
- 全速训练新添加的分类头(Head)。
R torch 的 optim 支持传入参数组(Parameter Groups)来实现这一点:
# 假设 model 有两部分: model$backbone 和 model$head
optimizer <- optim_sgd(
# 传入一个列表,列表里每个元素是一个 list
list(
# 第 1 组:骨干网络,学习率很低
list(params = model$backbone$parameters, lr = 0.0001),
# 第 2 组:分类头,学习率正常
list(params = model$head$parameters, lr = 0.01)
),
# 这里是默认参数,如果没有指定,就用这个
momentum = 0.9
)通过这种方式,我们可以极其精细地控制训练动力学。
5.3 学习率调度器
本节我们将介绍学习率调度器 (LR Scheduler),它负责根据训练进度动态调整学习率,是提升模型精度最廉价且有效的手段之一。
为什么要变频?可以类比打高尔夫球:
- 开球阶段:离洞很远,你需要大力挥杆(大学习率),让球迅速接近目标。
- 推杆阶段:球已经在洞口附近,你需要极其小心地微调(小学习率)。如果这时候还大力挥杆,球就会被打飞,甚至在这个洞口周围来回震荡,永远进不去。
在神经网络的 Loss 地形图上也是如此:训练初期,参数随机初始化,离最优解很远,我们需要较大的 LR 快速下降。训练后期需要逐步减小 LR,让模型收敛到极小值的“坑底”,而不是在坑口边缘徘徊。
R torch 的 lr_scheduler 模块提供了多种策略。我们将介绍最实用的三种。
一、阶梯式衰减 (lr_step)
这是最简单粗暴的策略:每隔固定的 Epoch,将学习率砍一刀。
# 定义优化器 (初始 lr = 0.1)
optimizer <- optim_sgd(model$parameters, lr = 0.1)
# 定义调度器:每过 30 个 Epoch,将 lr 乘以 0.1
scheduler <- lr_step(optimizer, step_size = 30, gamma = 0.1)
# 模拟:
# Epoch 1-30: lr = 0.1
# Epoch 31-60: lr = 0.01
# ...适用简单任务场景,或者你明确知道模型大概什么时候收敛。
二、监控式衰减 (lr_reduce_on_plateau)
这是一种“不见兔子不撒鹰”的策略。它不看时间,而是看效果。如果验证集 Loss 连续 \(N\) 个 Epoch 都不再下降(遇到了瓶颈 Plateau),它才降低学习率。
optimizer <- optim_adam(model$parameters, lr = 0.001)
# 策略:如果 validation loss 连续 10 次 (patience) 没有降低,
# 就把学习率乘以 0.1 (factor),且要在后台打印出来 (verbose)
scheduler <- lr_reduce_on_plateau(
optimizer,
mode = "min",
factor = 0.1,
patience = 10,
verbose = TRUE
)适合于所有场景,最省心。
三、余弦退火与 OneCycle
Leslie Smith 提出的 “Super-Convergence” 理论彻底改变了我们的观念。他发现,先热身(Warm-up)再冷却的效果最好。
- Warm-up:学习率从很小线性增加到很大。这有助于让模型参数快速“对齐”,并探索平坦区域。
- Annealing:学习率按余弦曲线下降到极小值。
# 这种调度器需要知道总的训练步数
scheduler <- lr_one_cycle(
optimizer,
max_lr = 0.01, # 学习率峰值
epochs = num_epochs, # 总轮数
steps_per_epoch = num_batches # 每轮有多少个 batch
)适合 Transformer、大模型、从头训练复杂网络。它通常能让模型收敛得更快、更准。
另外有个细节,调度器放在循环的哪里?不同的调度器有不同的更新频率:
- 大多数调度器(Step, MultiStep, ReduceOnPlateau):按 Epoch 更新。 放在 optimizer$step() 循环外。
- OneCycle 调度器:按 Batch 更新。 放在 optimizer$step() 循环内。
以及,由于学习率是在后台悄悄变化的,我们很容易配错参数(比如衰减过快导致训练停滞),记录学习率的变化是个好习惯。
# 获取当前学习率的辅助函数
get_lr <- function(optimizer) {
# 优化器可能有多个参数组,通常取第一个即可
optimizer$param_groups[[1]]$lr
}
# 记录列表
lr_history <- numeric(num_epochs)
for (epoch in 1:num_epochs) {
# ... 训练代码 ...
scheduler$step()
lr_history[epoch] <- get_lr(optimizer)
}
# 使用 ggplot2 绘图
library(ggplot2)
tibble(epoch = 1:num_epochs, lr = lr_history) %>%
ggplot(aes(epoch, lr)) +
geom_line() +
labs(title = "学习率变化曲线")5.4 诊断和调试
我们在炼丹的过程,经常也会有失败的情况,在各个环节插入辅助函数或对象是非常好的习惯。尤其是 Loss 的变化,可以帮我们定位问题:
一、Loss 变成 NaN(梯度爆炸)
这是最吓人的情况。通常在训练的前几轮,Loss 突然从一个正常数变成了 NaN(Not a Number),随后所有的输出都变成了 NaN。
回顾第 1 节的链式法则:\(\text{Grad} \approx \prod w_i\)。如果网络很深,且权重初始化得稍大(例如都大于 1),连乘效应会让梯度呈指数级增长。当梯度值超过计算机浮点数能表示的上限(Float32 约 \(3.4 \times 10^{38}\))时,就会溢出变成 Inf 或 NaN。这在 RNN 和 Transformer 中尤为常见。
解决办法是梯度裁剪 (Gradient Clipping)。这是一种简单粗暴但极其有效的手段:在 optimizer$step() 之前,强行把梯度的“长度”(范数)砍一刀,限制在一个阈值内。
# 在训练循环中
loss$backward()
# max_norm = 1.0 意味着如果所有参数的梯度向量模长超过 1,
# 就按比例缩小它们,保持方向不变,但模长变为 1。
# 这行代码必须放在 backward() 之后,step() 之前。
nn_utils_clip_grad_norm_(model$parameters, max_norm = 1.0)
optimizer$step()我们在第 12 章会利用该函数。
二、Loss 剧烈震荡
Loss 下降了一点,然后开始疯狂上下跳动,甚至有时还反弹变大。一般是因为学习率(LR)过大。 这就好比在上一节的 Beale 函数实验中,你给了 SGD 一个巨大的步长,导致它在峡谷两壁之间来回撞墙,永远落不到谷底。
解决方案:
- 把学习率调小 10 倍(例如从 0.01 变成 0.001)。
- 使用我们第 4 节介绍的 LR Scheduler。
5.5 混合精度训练 (AMP)
在真实的工业界部署和大规模模型训练中,我们经常会面临一种物理限制:GPU 显存容量与计算带宽。自动混合精度(Automatic Mixed Precision, AMP)技术,可以巧妙地利用数值类型的特性,在不损失模型精度的前提下,让训练速度翻倍并使显存占用减半。
5.5.1 半精度与单精度
在深度学习的默认设置中,张量的数据类型通常是 32 位浮点数(Float32,简称 FP32)。它在计算机内存中占用 4 个字节,能够提供极高的数值精度和广阔的表示范围。
然而,神经网络本质上是对数据分布的统计逼近,它具有极强的“抗噪”能力。这就引出了一个关键问题:我们真的需要那么高的计算精度吗?
为了提升算力,NVIDIA 等硬件厂商在现代 GPU 中引入了针对低精度计算优化的 Tensor Core。这使得 16 位浮点数(FP16 或 BF16,占用 2 个字节)成为训练加速的利器:
- 一个包含 1 亿参数的模型,其权重在 FP32 下占用 400MB 显存,而在 FP16 下仅需 200MB。这直接允许我们将 Batch Size 翻倍,或者在单卡上塞进更深的网络。
- 数据体积减半意味着在 CPU 与 GPU 之间、或者 GPU 显存与计算单元之间搬运数据的速度更快。同时,Tensor Core 处理 FP16 矩阵乘法的吞吐量远超 FP32。
FP16 的可表示范围远小于 FP32。FP32 可以轻松表示 1e-38 级别的微小数字,而 FP16 一旦遇到小于 6.10e-5 的数值,就会直接将其截断为 0,这在深度学习中被称为下溢 (Underflow)。
5.5.2 自动混排
为了在“高精度(防下溢)”和“低精度(高性能)”之间寻找完美平衡,自动混合精度 (AMP) 应运而生。AMP 的核心思想是:让计算框架自动判断每一层操作适合哪种精度。
在 R 的 torch 生态中,AMP 通过两个核心组件完美闭环:with_autocast 与 cuda_amp_grad_scaler。
一、上下文管理器:with_autocast()
- 矩阵乘法、卷积,这些操作计算密集,对微小误差不敏感。这些适合 FP16 的操作。
- Softmax 归一化、交叉熵损失、BatchNorm 的统计量。这些操作一旦使用低精度,极易发生数值溢出(Overflow)或下溢。这些适合保留 FP32。
在 R 中,我们无需手动为每个张量转换类型,只需将前向传播包裹在 with_autocast() 中,框架会在底层自动完成这种“智能调度”。
二、梯度缩放器:cuda_amp_grad_scaler
即使前向传播完美解决了精度分配问题,反向传播时依然面临梯度下溢的致命隐患。
在训练后期,损失函数对权重的偏导数(梯度)通常极小。如果这些梯度因为 FP16 的精度限制而变成 0,网络就会停止学习(被称为“死掉”)。为了解决这个问题,我们需要引入梯度缩放(Grad Scaler)。
其数学逻辑非常直观:在反向传播前,将 Loss 乘以一个非常大的缩放因子 \(S\)(例如 65536),人为地将梯度“放大”到 FP16 的安全范围内。在更新权重之前,再将梯度除以 \(S\) 还原。
\[ w_{t+1} = w_t - \eta \frac{\nabla (L \times S)}{S} \]
通过这种方式,我们既享受了 FP16 的计算速度,又保护了微小梯度不被丢弃。
5.5.3 代码实现
(注意:运行以下代码需要一块支持 Tensor Core 的 NVIDIA GPU,Mac 的 MPS 不支持 AMP)
首先构造一个重型的 CNN 模型和数据,并将数据放在显存上:
library(torch)
model <- nn_sequential(
nn_conv2d(256, 512, 3, padding = 1), nn_relu(),
nn_conv2d(512, 512, 3, padding = 1), nn_relu(),
nn_adaptive_avg_pool2d(c(1, 1)), nn_flatten(), nn_linear(512, 10)
)$to(device = "cuda")
opt <- optim_adam(model$parameters, lr = 1e-3)
x <- torch_randn(16, 256, 128, 128, device = "cuda")
y <- torch_randint(1, 10, size = 16, dtype = torch_long(), device = "cuda")混合精度 AMP 训练需要稍作改动:
scaler <- cuda_amp_grad_scaler()
for (i in 1:50) {
opt$zero_grad()
with_autocast("cuda", {
loss <- nnf_cross_entropy(model(x), y)
})
scaler$scale(loss)$backward()
scaler$step(opt)
scaler$update()
}对比梯度下降三部曲的标准做法:
for (i in 1:50) {
opt$zero_grad()
loss <- nnf_cross_entropy(model(x), y)
loss$backward()
opt$step()
}在 RTX 30/40 系列的表现,显存峰值(Memory Peak)会显著下降(通常减少 30% 到 50% 不等),并且耗时也会显著缩短。