1 深度学习与 R 生态
“人类的黎明。”
—— 《2001 太空漫游》 (1968)
在史前荒原上,猿人第一次意识到手中的骨头可以作为武器。伴随着激昂的《查拉图斯特拉如是说》,他将骨头抛向空中,镜头瞬间切换,旋转的骨头变成了一艘在太空中翱翔的飞船。
1.1 深度学习简史
深度学习(Deep Learning)是机器学习的一个分支,它通过多层人工神经网络模拟人脑,从而实现数据处理、模式学习和智能决策。
1943 年,McCulloch 和 Pitts 提出了 M-P 神经元模型,为人工智能奠定了数学基础。1958 年,Frank Rosenblatt发明了感知机(Perceptron),这是一种单层神经网络,能够进行简单的二元分类。
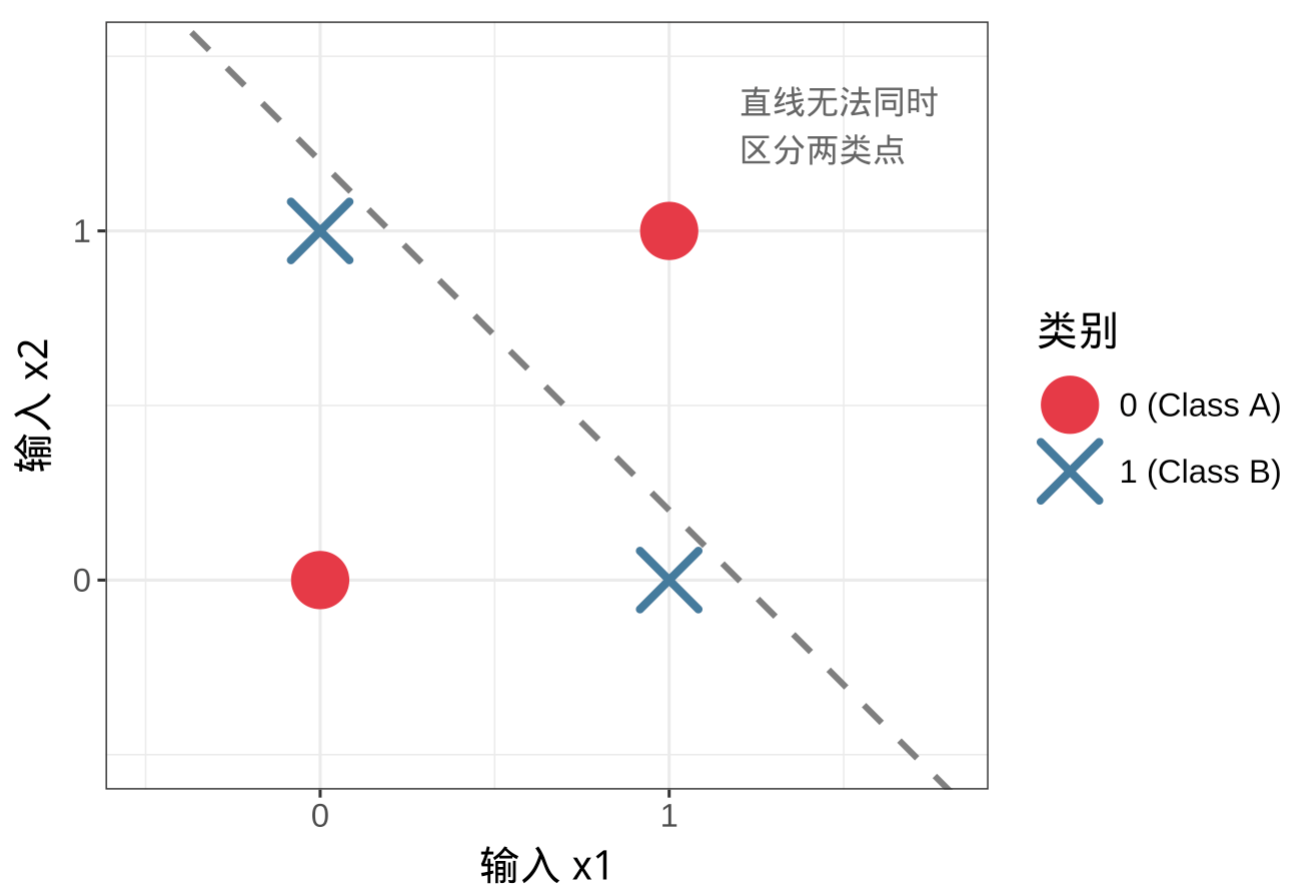
1969 年,Minsky 和 Papert 出版了《Perceptrons》一书,从数学上证明了单层感知机无法解决异或(XOR)等非线性问题。这一发现不仅宣告了单层感知机的局限,也直接让神经网络研究陷入了第一次“寒冬”,研究资金和公众关注度随之锐减。
1986 年,Geoffrey Hinton 等人完善并推广了反向传播算法(Backpropagation),有效解决了多层网络的训练问题,打破了非线性的诅咒。
1998 年,Yann LeCun 提出了 LeNet-5 卷积神经网络(CNN),并成功应用于手写数字识别(如邮政编码读取),这被视为现代视觉模型的雏形。尽管取得了这一突破,但由于当时计算机算力有限,加之支持向量机(SVM)等统计学习方法风头正盛,神经网络在2000年代初期再次被边缘化,陷入沉寂。
2006 年,Hinton 提出了深度置信网络(DBN),并首次提出了“深度学习”的概念,利用逐层预训练解决了深层网络的优化难题。

2012 年,Alex Krizhevsky 等人构建的 AlexNet 在 ImageNet 图像识别大赛中以压倒性优势夺冠。GPU 算力的介入和大数据集的出现,正式引爆了深度学习革命。
2017 年,Google 提出 Transformer 架构,引入注意力机制(Attention)。它让模型在处理信息时,能够像人类一样,聚焦于输入中最重要的部分,而不是平均对待所有信息。这一架构随后孕育了 BERT 和 GPT 系列模型,开启了以大语言模型(LLM)为代表的生成式人工智能时代。
回顾历史,这些里程碑式的进展最终汇聚成一个核心突破:深度学习改变了机器理解数据的方式。那么,这种‘改变’究竟是什么呢?
传统机器学习极其依赖人工设计的特征工程(Feature Engineering),需要领域专家的经验。而深度学习则让机器自己“学习”如何从原始数据中提取最有用的特征,从而更像一个“聪明的小孩”自己学习看图识物。浅层网络或许只能识别简单的边缘或颜色,但深层网络通过层层递进,能将这些基础特征逐步组合,最终形成复杂的抽象概念(例如从“边缘”到“眼睛”,再到完整的“人脸”)。这种深度的增加,搭建起了一个从低级特征到高级语义的抽象阶梯。
从数学角度看,普适逼近定理(Universal Approximation Theorem)告诉我们:只要拥有足够多的神经元,即使是一个只包含一个隐藏层的神经网络,也能以任意精度模拟任何连续函数。神经网络的训练机制是反向传播:它首先计算预测值与真实值之间的误差(Loss),然后将误差沿网络反方向逐层传递,并利用梯度下降(Gradient Descent)算法,对每个连接的权重(Weight)进行微调,直到误差最小化。
可以理解成一个万能的乐高积木套装,只要积木块(神经元)足够多,并且知道怎么拼(调整权重),它就能拼出任何你想要的形状(逼近任何复杂的函数关系)。
可以用数学语言简单描述为寻找最优参数 \(\theta\),使得损失函数 \(L\) 最小化: \[\theta^* = \operatorname*{argmin}_\theta L(f(x; \theta), y)\]
其中 \(L\) 代表损失函数(衡量预测有多差),\(f(x; \theta)\) 是神经网络的模型(由参数 \(\theta\) 控制),\(y\) 是真实值。
1.2 R torch 的架构底座
序言中我们探讨了 R torch 带来的原生体验与母语直觉。那么,在这些优雅的代码背后,是什么在支撑着深度学习庞大的计算开销?
LibTorch 的原生绑定
R torch 的核心计算能力并非来自 R 语言本身,而是源于它与 PyTorch 共享的底层心脏——LibTorch。
它在架构上直接绕过了 Python 解释器。为了让 R 能够高效地调用 C++ 核心,开发团队引入了一个轻量级的 C 接口层 Lantern。这就构成了一条极其直接且低延迟的调用链路:
R 代码 \(\rightarrow\) Lantern (C 接口) \(\rightarrow\) LibTorch (C++) \(\rightarrow\) CPU / GPU / MPS
这意味着,在 R 中执行的张量运算与自动微分,其底层硬件加速效率与原生 PyTorch 完全对等。无论是在 Mac 本地进行轻量级的代码验证(调用 M 系列芯片的 MPS 加速),还是将代码无缝迁移到配备了 RTX 4090 等高性能 GPU 的 Linux 服务器上进行算力冲刺,这种统一的底层架构都保证了极高的执行效率与跨环境的稳定性。
本书绝大部分代码与案例,均可在轻量级设备(如笔者的 MacBook Air M4 16G)上顺畅完成端到端的训练。若在后续复杂模型中遇到本地算力瓶颈,推荐租用云端 GPU 服务器,配备 NVIDIA RTX 30 系列及以上显卡即可满足全部学习需求。
工具生态矩阵
在坚实的架构底座之上,R 社区已经构建起了一套完备的深度学习工具矩阵。在本书接下来的工程实践中,我们将根据不同的任务场景调用以下核心组件:
| 组件名称 | 功能定位 | 类比 Python 生态 |
|---|---|---|
torch |
核心库。提供张量运算、自动微分、神经网络层。 | torch |
torchvision |
视觉工具箱。提供预训练模型(ResNet, VGG等)、图像转换管线、标准数据集。 | torchvision |
torchaudio |
音频处理工具。提供波形变换、频谱图生成等功能。 | torchaudio |
luz |
高级函数,它封装了繁琐的训练循环(For-loop),提供进度条、指标记录和回调函数(Callbacks)。 | Lightning 或 fast.ai |
hfhub |
允许用户直接从 Hugging Face Hub 下载和加载预训练模型权重。 | huggingface_hub |
在本书的基础章节,我们将克制地仅使用 torch 来手写前向与反向传播,旨在吃透算法底层的数学逻辑;而在后续的工程实践篇章中,我们将全面引入 luz,展示如何用极简的代码构建高标准、可复现的工业级训练管线。
1.3 第一个 torch 程序
在深入深度学习的数学原理之前,我们需要先搭建好“脚手架”。得益于 R torch 的原生设计,这一步比你想象中要简单得多。
1.3.1 安装环境
你只需要在 R 控制台中运行标准的安装命令:
install.packages("torch")安装完成后,第一次加载库时,R torch 会自动检测你的系统环境(Windows/Mac/Linux),并下载对应的 LibTorch 和 Lantern。
考虑到我们后续的学习会用到显卡,比如 NVIDIA 30/40 环境,更建议的安装方式是预编译二进制文件安装方式,可以不用折腾 CUDA 或 cuDNN 环境:
- Windows 和 Linux 支持 cpu 和 cuda 12.8
- MacOS 支持 cpu-intel 或 cpu-m1,Mac 自带的核显也能够被调用起来
由类似 CRAN 的软件仓库提供了所需的所有组件:
options(timeout = 900) # 临时增加超时限制到 900 秒,预编译文件需要下载 2G+
kind <- "cu128"
version <- available.packages()["torch","Version"]
options(repos = c(
torch = sprintf("https://torch-cdn.mlverse.org/packages/%s/%s/", kind, version),
CRAN = "https://cloud.r-project.org" # 或自行替换源
))
install.packages("torch")1.3.2 张量运算
为了直观感受 torch 的威力,我们不做无聊的“Hello World”,而是进行一场实战测试。我们将对比 R 原生矩阵运算 与 torch 张量运算在处理大规模数据时的速度差异。
实验设置:生成两个 \(2000 \times 2000\) 的矩阵,并计算它们的矩阵乘法。
library(torch)
library(bench)
N <- 2000 # 2000x2000, 400 万个元素
matrix_r <- matrix(runif(N * N), nrow = N, ncol = N)
# R 原生矩阵默认是 64 位双精度 (Double),深度学习标准是 32 位单精度 (Float32)
tensor_cpu <- torch_tensor(matrix_r, dtype = torch_float32())
tensor_mps <- tensor_cpu$to(device = torch_device("mps"))
results <- mark(
R_Base_CPU = matrix_r %*% matrix_r,
Torch_CPU = torch_matmul(tensor_cpu, tensor_cpu),
Torch_MPS_Sync = {
ans <- torch_matmul(tensor_mps, tensor_mps)
invisible(ans[1, 1]$item()) # 提取单个元素以强制 CPU 等待 GPU 计算完成
},
iterations = 50,
check = FALSE, # 数据类型精度不同 (Float64 vs Float32),故关闭结果一致性检查
memory = FALSE
)
reslut[,c('expression', 'min', 'median', 'n_itr', 'n_gc', 'total_time')]| expression | min | median | n_itr | n_gc | total_time |
|---|---|---|---|---|---|
| R_Base_CPU | 39.74ms | 39.99ms | 25 | 25 | 1s |
| Torch_CPU | 10.21ms | 11.21ms | 50 | 0 | 558ms |
| Torch_MPS_Sync | 5.74ms | 5.78ms | 50 | 0 | 328ms |
这组测试实际上对比了两个层面:一是 CPU 环境下 Torch 与 R 原生运算的性能,二是 Apple Silicon 的 MPS (GPU) 与 CPU 之间的性能差异:
CPU:
- R 中的矩阵默认是双精度浮点数 (Float64)。CPU 处理一个 64 位数字的开销(内存带宽占用、寄存器占用)比 torch张量 32 位数字要大得多。这也是为什么
mark里增加check = FALSE参数的原因。 - 标准的 R 安装通常采用通用版 BLAS 或 LAPACK 库。其设计理念是“兼容性优先,准确性至上”,因此并未针对 M4 芯片的特定指令集进行深度优化。Torch 基于 LibTorch,它内置了高度优化的线性代数库(通常是 Intel MKL 或针对 ARM 优化的 OpenBLAS)。它能极致利用 M4 芯片的 NEON/AMX 指令集,且默认开启多线程并行(利用所有 CPU 核心),而 R 的矩阵运算通常偏向单线程(除非专门配置)。
- R 在计算
matrix_r %*% matrix_r时,它必须在 R 的堆内存(Heap)中申请新的空间来存储计算结果。这种频繁的内存分配与回收,会不断触发 R 的垃圾回收机制 (GC),导致计算暂停,带来额外的开销(Overhead)。相比之下,Torch 的张量数据存储在 C++ 管理的堆外内存(Off-heap)中。由于bench包仅能监控 R 的内存堆,无法监测到 C++ 层的操作,因此 Torch 不仅有效规避了 R 的 GC 干扰,也节省了昂贵的内存分配与检查时间。
GPU:
- MPS 利用的是 GPU 的强大算力。与 CPU 只有区区 8-12 个核心、更擅长处理复杂逻辑任务不同,M4 的 GPU 拥有成百上千个微小的计算单元。对于矩阵乘法这种“每个元素都能独立并行计算”的任务,GPU 能够瞬间同时完成,而 CPU 只能排队逐个处理。
- M4 芯片的统一内存(Unified Memory)架构,使得数据无需在 CPU 和 GPU 之间通过缓慢的总线进行拷贝(这正是传统 NVIDIA 显卡的痛点)。Torch 只需要发出指令,GPU 就能直接读取数据,几乎实现了零延迟启动计算。
在上面的代码中,你已经无意间使用了两个核心概念,这将在下一章详细展开:
torch_tensor(): 这是 torch 的核心数据结构。你可以把它看作是 R 中的array或matrix,但它更智能,知道自己该在 CPU 还是 GPU 上待着。tensor_cpu$to(device = torch_device("mps")): 这是设备迁移操作,它将数据从计算机的主内存(RAM)“搬运”到了显卡的显存(VRAM)中。